1.内置函数


# 内置的方法有很多 # 不一定全都在object中 # class Classes: # def __init__(self,name): # self.name = name # self.student = [] # def __len__(self): # return len(self.student) # def __str__(self): # return 'classes' # py_s9= Classes('python全栈9期') # py_s9.student.append('二哥') # py_s9.student.append('泰哥') # print(len(py_s9)) # print(py_s9) #__del__ # class A: # def __del__(self): # 析构函数: 在删除一个对象之前进行一些收尾工作 # self.f.close() # a = A() # a.f = open() # 打开文件 第一 在操作系统中打开了一个文件 拿到了文件操作符存在了内存中 # del a # a.f 拿到了文件操作符消失在了内存中 # del a # del 既执行了这个方法,又删除了变量 # 引用计数 # __call__ class A: def __init__(self,name): self.name = name def __call__(self): ''' 打印这个对象中的所有属性 :return: ''' for k in self.__dict__: print(k,self.__dict__[k]) a = A('alex')() __del__析构方法,当对象在内存中被释放时,自动触发执行。 注:此方法一般无须定义,因为Python是一门高级语言,程序员在使用时无需关心内存的分配和释放,因为此工作都是交给Python解释器来执行,所以,析构函数的调用是由解释器在进行垃圾回收时自动触发执行的。 __call__对象后面加括号,触发执行。 注:构造方法的执行是由创建对象触发的,即:对象 = 类名() ;而对于 __call__ 方法的执行是由对象后加括号触发的,即:对象() 或者 类()()
2.
class Foo: def __init__(self,name): self.name=name def __getitem__(self, item): print(self.__dict__[item]) def __setitem__(self, key, value): self.__dict__[key]=value def __delitem__(self, key): print('del obj[key]时,我执行') self.__dict__.pop(key) def __delattr__(self, item): print('del obj.key时,我执行') self.__dict__.pop(item) f1=Foo('sb') f1['age']=18 f1['age1']=19 del f1.age1 del f1['age'] f1['name']='alex' print(f1.__dict__)
# __init__ 初始化方法 # __new__ 构造方法 : 创建一个对象 class A: def __init__(self): self.x = 1 print('in init function') # def __new__(cls, *args, **kwargs): # print('in new function') # return object.__new__(A, *args, **kwargs) # a1 = A() # a2 = A() # a3 = A() # print(a1) # print(a2) # print(a3) # print(a.x) # 设计模式 # 23种 # 单例模式 # 一个类 始终 只有 一个 实例 # 当你第一次实例化这个类的时候 就创建一个实例化的对象 # 当你之后再来实例化的时候 就用之前创建的对象 # class A: # __instance = False # def __init__(self,name,age): # self.name = name # self.age = age # def __new__(cls, *args, **kwargs): # if cls.__instance: # return cls.__instance # cls.__instance = object.__new__(cls) # return cls.__instance # # egon = A('egg',38) # egon.cloth = '小花袄' # nezha = A('nazha',25) # print(nezha) # print(egon) # print(nezha.name) # print(egon.name) # print(nezha.cloth) # class A: # def __init__(self,name): # self.name = name # # def __eq__(self, other): # if self.__dict__ == other.__dict__: # return True # else: # return False # # ob1 = A('egon') # ob2 = A('egg') # print(ob1 == ob2) # hash() #__hash__ # class A: # def __init__(self,name,sex): # self.name = name # self.sex = sex # def __hash__(self): # return hash(self.name+self.sex) # # a = A('egon','男') # b = A('egon','nv') # print(hash(a)) # print(hash(b))
3.
import json from collections import namedtuple Card = namedtuple('Card',['rank','suit']) # rank 牌面的大小 suit牌面的花色 # class FranchDeck: # ranks = [str(n) for n in range(2,11)] + list('JQKA') # 2-A # suits = ['红心','方板','梅花','黑桃'] # # def __init__(self): # self._cards = [Card(rank,suit) for rank in FranchDeck.ranks # for suit in FranchDeck.suits] # # def __len__(self): # return len(self._cards) # # def __getitem__(self, item): # return self._cards[item] # # def __setitem__(self, key, value): # self._cards[key] = value # # def __str__(self): # return json.dumps(self._cards,ensure_ascii=False) # deck = FranchDeck() # print(deck[10]) # from random import choice # print(choice(deck)) # # print(choice(deck)) # from random import shuffle # shuffle(deck) # print(deck[10]) # print(deck) # print(deck[:5])
# 100 名字 和 性别 年龄不同 # set # class A: # def __init__(self,name,sex,age): # self.name = name # self.sex = sex # self.age = age # # # def __eq__(self, other): # # if self.name == other.name and self.sex == other.sex: # # return True # # return False # # def __hash__(self): # return hash(self.name + self.sex) # a = A('egg','男',38) # b = A('egg','男',37) # print(set((a,b))) # unhashable # set 依赖对象的 hash eq
4.
# 登录认证 # 加密 --> 解密 # 摘要算法 # 两个字符串 : # import hashlib # 提供摘要算法的模块 # md5 = hashlib.md5() # md5.update(b'123456') # print(md5.hexdigest()) #aee949757a2e698417463d47acac93df # 不管算法多么不同,摘要的功能始终不变 # 对于相同的字符串使用同一个算法进行摘要,得到的值总是不变的 # 使用不同算法对相同的字符串进行摘要,得到的值应该不同 # 不管使用什么算法,hashlib的方式永远不变 # import hashlib # 提供摘要算法的模块 # sha = hashlib.md5() # sha.update(b'alex3714') # print(sha.hexdigest()) # sha 算法 随着 算法复杂程度的增加 我摘要的时间成本空间成本都会增加 # 摘要算法 # 密码的密文存储 # 文件的一致性验证 # 在下载的时候 检查我们下载的文件和远程服务器上的文件是否一致 # 两台机器上的两个文件 你想检查这两个文件是否相等 # 用户注册 # 用户 输入用户名 # 用户输入 密码 # 明文的密码进行摘要 拿到一个密文的密码 # 写入文件 # 用户的登录 # import hashlib # usr = input('username :') # pwd = input('password : ') # with open('userinfo') as f: # for line in f: # user,passwd,role = line.split('|') # md5 = hashlib.md5() # md5.update(bytes(pwd,encoding='utf-8')) # md5_pwd = md5.hexdigest() # if usr == user and md5_pwd == passwd: # print('登录成功') # 1234567890 # abcdefghijk # 6位 # md5 # 撞库 # 加盐 import hashlib # 提供摘要算法的模块 # md5 = hashlib.md5(bytes('盐',encoding='utf-8')) # # md5 = hashlib.md5() # md5.update(b'123456') # print(md5.hexdigest()) # 动态加盐 # 用户名 密码 # 使用用户名的一部分或者 直接使用整个用户名作为盐 # import hashlib # 提供摘要算法的模块 # md5 = hashlib.md5(bytes('盐',encoding='utf-8')+b'') # # md5 = hashlib.md5() # md5.update(b'123456') # print(md5.hexdigest()) #import hashilib # 做摘要计算的 把字节类型的内容进行摘要处理 # md5 sha # md5 正常的md5算法 加盐的 动态加盐 # 文件的一致性校验 # 文件的一致性校验这里不需要加盐 # import hashlib # md5 = hashlib.md5() # md5.update(b'alex') # md5.update(b'3714') # print(md5.hexdigest())
5
# configparse # import configparser # config = configparser.ConfigParser() # config["DEFAULT"] = {'ServerAliveInterval': '45', # 'Compression': 'yes', # 'CompressionLevel': '9', # 'ForwardX11':'yes' # } # config['bitbucket.org'] = {'User':'hg'} # # config['topsecret.server.com'] = {'Host Port':'50022','ForwardX11':'no'} # # with open('example.ini', 'w') as f: # config.write(f) # import configparser # # config = configparser.ConfigParser() # #---------------------------查找文件内容,基于字典的形式 # # print(config.sections()) # [] # # config.read('example.ini') # print(config.sections()) # ['bitbucket.org', 'topsecret.server.com'] # # print('bytebong.com' in config) # False # print('bitbucket.org' in config) # True # print(config['bitbucket.org']["user"]) # hg # print(config['DEFAULT']['Compression']) #yes # print(config['topsecret.server.com']['ForwardX11']) #no # # print(config['bitbucket.org']) #<Section: bitbucket.org> # # for key in config['bitbucket.org']: # 注意,有default会默认default的键 # print(key) # # print(config.options('bitbucket.org')) # 同for循环,找到'bitbucket.org'下所有键 # # print(config.items('bitbucket.org')) #找到'bitbucket.org'下所有键值对 # # print(config.get('bitbucket.org','compression')) # yes get方法Section下的key对应的value # import configparser # config = configparser.ConfigParser() # config.read('example.ini') # 读文件 # config.add_section('yuan') # 增加section # config.remove_section('bitbucket.org') # 删除一个section # config.remove_option('topsecret.server.com',"forwardx11") # 删除一个配置项 # config.set('topsecret.server.com','k1','11111') # config.set('yuan','k2','22222') # f = open('new2.ini', "w") # config.write(f) # 写进文件 # f.close()
# login 登录 # log 日志 # logging # 什么叫日志? # 日志 用来记录用户行为 或者 代码的执行过程 # print # logging # 我能够“一键”控制 # 排错的时候需要打印很多细节来帮助我排错 # 严重的错误记录下来 # 有一些用户行为 有没有错都要记录下来 import logging # logging.basicConfig(level=logging.WARNING, # format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s', # datefmt='%a, %d %b %Y %H:%M:%S') # try: # int(input('num >>')) # except ValueError: # logging.error('输入的值不是一个数字') # logging.debug('debug message') # 低级别的 # 排错信息 # logging.info('info message') # 正常信息 # logging.warning('warning message') # 警告信息 # logging.error('error message') # 错误信息 # logging.critical('critical message') # 高级别的 # 严重错误信息 # print('%(key)s'%{'key':'value'}) # print('%s'%('key','value')) # basicconfig 简单 能做的事情相对少 # 中文的乱码问题 # 不能同时往文件和屏幕上输出 # 配置log对象 稍微有点复杂 能做的事情相对多 import logging logger = logging.getLogger() fh = logging.FileHandler('log.log',encoding='utf-8') sh = logging.StreamHandler() # 创建一个屏幕控制对象 formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s') formatter2 = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s [line:%(lineno)d] : %(message)s') # 文件操作符 和 格式关联 fh.setFormatter(formatter) sh.setFormatter(formatter2) # logger 对象 和 文件操作符 关联 logger.addHandler(fh) logger.addHandler(sh) logging.debug('debug message') # 低级别的 # 排错信息 logging.info('info message') # 正常信息 logging.warning('警告错误') # 警告信息 logging.error('error message') # 错误信息 logging.critical('critical message') # 高级别的 # 严重错误信息 # 程序的充分解耦 # 让程序变得高可定制 # zabbix # logging # 有5种级别的日志记录模式 : # 两种配置方式:basicconfig 、log对象
6.软件开发的架构
我们了解的涉及到两个程序之间通讯的应用大致可以分为两种:
第一种是应用类:qq、微信、网盘、优酷这一类是属于需要安装的桌面应用
第二种是web类:比如百度、知乎、博客园等使用浏览器访问就可以直接使用的应用
这些应用的本质其实都是两个程序之间的通讯。而这两个分类又对应了两个软件开发的架构~
1.C/S架构
C/S即:Client与Server ,中文意思:客户端与服务器端架构,这种架构也是从用户层面(也可以是物理层面)来划分的。
这里的客户端一般泛指客户端应用程序EXE,程序需要先安装后,才能运行在用户的电脑上,对用户的电脑操作系统环境依赖较大。
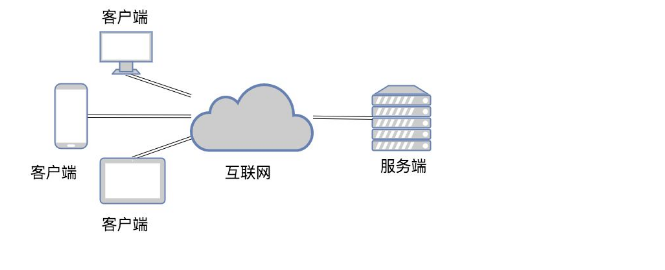
2.B/S架构
B/S即:Browser与Server,中文意思:浏览器端与服务器端架构,这种架构是从用户层面来划分的。
Browser浏览器,其实也是一种Client客户端,只是这个客户端不需要大家去安装什么应用程序,只需在浏览器上通过HTTP请求服务器端相关的资源(网页资源),客户端Browser浏览器就能进行增删改查。

# qq 微信 飞秋 网游 微博 歪歪 _基于应用的网络程序 # 百度 微博 知乎 博客园 网易 _基于浏览器的网络程序 # 网络编程中的 - C/S架构 # c client 客户端 # s server 服务端 # 网络编程中的 - B/S架构 # b broser 浏览器 # s server 服务端 # 不需要额外的安装客户端了,只需要一个网址就可以访问 # 轻量级 - 使用成本低 # B/S架构是C/S架构的一种特殊形式 # 手机上 : 浏览器 app # 两个py程序想要通信 # 写文件 # 在不同机器上的两个py程序之间想要通信 # 网络 # 网络的发展史 # 网卡网口 # 两台机器之间 插上网线就可以通信 # 网卡上 - mac地址 # ip地址 # 是4个点分十进制 - ipv4协议 # 0.0.0.0 - 255.255.255.255 # 127.0.0.1 本机 # 内网字段 192.168.**** # 10.**** # 172.*** # 6个点分十进制 - ipv6协议 # 0.0.0.0.0.0 - 255.255.255.255.255.255 # 交换机 # 广播 # 单播 # 组播 # arp协议 : 通过IP地址获取某一台机器的mac地址 # 子网掩码 # 子网掩码 和 ip地址进行 按位 与 运算 就能得出一个机器所在的网段 # 192.168.21.36 # 11000000.10101000.00010101.00100100 # 255.255.255.0 255.255.0.0 # 11111111.11111111.11111111.00000000 # 11000000.10101000.00010101.00000000 # 192.168.21.0 网段 # 网关地址 : 整个局域网中的机器能沟通过网关ip与外界通信 # 网段 : 子网掩码 和 ip地址进行 按位 与 运算 # 端口 : 0-65535 # 8000-酷狗音乐 22-ssh 3306-mysql # python 网络应用 8000 # ip地址+端口号 : 在全网找到唯一的一台机器+唯一的应用 # 我们选择端口 : 8000之后 # tcp协议 # 全双工的通信协议 # 一旦连接建立起来,那么连接两端的机器能够随意互相通信 # 面向连接的通信方式 # 数据安全不容易丢失 # 建立连接的 三次握手 ****** # 断开连接的 四次挥手 ******