今日学习内容如下:
1.序列化模块
什么叫序列化——将原本的字典、列表等内容转换成一个字符串的过程就叫做序列化。


比如,我们在python代码中计算的一个数据需要给另外一段程序使用,那我们怎么给? 现在我们能想到的方法就是存在文件里,然后另一个python程序再从文件里读出来。 但是我们都知道,对于文件来说是没有字典这个概念的,所以我们只能将数据转换成字典放到文件中。 你一定会问,将字典转换成一个字符串很简单,就是str(dic)就可以办到了,为什么我们还要学习序列化模块呢? 没错序列化的过程就是从dic 变成str(dic)的过程。现在你可以通过str(dic),将一个名为dic的字典转换成一个字符串, 但是你要怎么把一个字符串转换成字典呢? 聪明的你肯定想到了eval(),如果我们将一个字符串类型的字典str_dic传给eval,就会得到一个返回的字典类型了。 eval()函数十分强大,但是eval是做什么的?e官方demo解释为:将字符串str当成有效的表达式来求值并返回计算结果。 BUT!强大的函数有代价。安全性是其最大的缺点。 想象一下,如果我们从文件中读出的不是一个数据结构,而是一句"删除文件"类似的破坏性语句,那么后果实在不堪设设想。 而使用eval就要担这个风险。 所以,我们并不推荐用eval方法来进行反序列化操作(将str转换成python中的数据结构)
序列化的目的
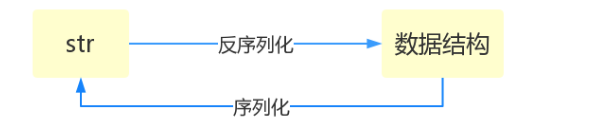
# 从数据类型 --> 字符串的过程 序列化
# 从字符串 --> 数据类型的过程 反序列化
# json *****
# pickle ****
# shelve ***
# json # 数字 字符串 列表 字典 元组
# 通用的序列化格式
# 只有很少的一部分数据类型能够通过json转化成字符串
# pickle
# 所有的python中的数据类型都可以转化成字符串形式
# pickle序列化的内容只有python能理解
# 且部分反序列化依赖python代码
# shelve
# 序列化句柄
# 使用句柄直接操作,非常方便
Json模块提供了四个功能:dumps、dump、loads、load
#json # 数字 字符串 列表 字典 元组 # 1. json dumps序列化方法 loads反序列化方法 # dic = {'s':'sdf','sdf':'sf'} # print(type(str(dic))) # print(type(dic),dic)#<class 'dict'> {'s': 'sdf', 'sdf': 'sf'} # import json # str_d = json.dumps(dic) # print(type(str_d),str_d)#<class 'str'> {"s": "sdf", "sdf": "sf"} # str_l = json.loads(str_d) # print(type(str_l),str_l) # dic = {'s','sdf','sdf'} # import json # str_d = json.dumps(dic) # print(type(str_d),str_d)#集合无法序列化 # dic = (1,2,3) # import json # str_d = json.dumps(dic)#元组序列成str,以列表形式展现 # print(type(str_d),str_d)#<class 'str'> [1, 2, 3] # dic = [1,23,4,5] # import json # str_d = json.dumps(dic)# # print(type(str_d),str_d) # 2. json dump load # import json # # dic = {'s':'sdf','sdf':'sf'} # # f = open('ss',mode = 'w',encoding = 'utf-8') # # json.dump(dic,f) # # f.close() # f = open('ss','r',encoding = 'utf-8') # res = json.load(f) # f.close() # print(type(res),res) import json # dic = {'s':'中国','sdf':'sf'} # f = open('ss',mode = 'w',encoding = 'utf-8') # json.dump(dic,f,ensure_ascii=False) # json.dump(dic,f,ensure_ascii=False) # f.close() # f = open('ss','r',encoding = 'utf-8') # res1 = json.load(f) # # res2 = json.load(f) # f.close() # print(type(res1),res1) # l = [{'k':'11'},{'f':'222'}] # f = open('mm','w') # import json # for dic in l: # str_dic = json.dumps(dic) # f.write(str_dic+' ') # f.close() # f = open('mm') # import json # l = [] # for line in f: # dic = json.loads(line.strip()) # l.append(dic) # f.close() # print(l)
import pickle dic = {'k1':'v1','k2':'v2','k3':'v3'} str_dic = pickle.dumps(dic) print(str_dic) #一串二进制内容 dic2 = pickle.loads(str_dic) print(dic2) #字典 import time struct_time = time.localtime(1000000000) print(struct_time) f = open('pickle_file','wb') pickle.dump(struct_time,f) f.close() f = open('pickle_file','rb') struct_time2 = pickle.load(f) print(struct_time2.tm_year)
用于序列化的两个模块
- json,用于字符串 和 python数据类型间进行转换
- pickle,用于python特有的类型 和 python的数据类型间进行转换
pickle模块提供了四个功能:dumps、dump(序列化,存)、loads(反序列化,读)、load (不仅可以序列化字典,列表...可以把python中任意的数据类型序列化)
这时候机智的你又要说了,既然pickle如此强大,为什么还要学json呢?
这里我们要说明一下,json是一种所有的语言都可以识别的数据结构。
如果我们将一个字典或者序列化成了一个json存在文件里,那么java代码或者js代码也可以拿来用。
但是如果我们用pickle进行序列化,其他语言就不能读懂这是什么了~
所以,如果你序列化的内容是列表或者字典,我们非常推荐你使用json模块
但如果出于某种原因你不得不序列化其他的数据类型,而未来你还会用python对这个数据进行反序列化的话,那么就可以使用pickle
shelve也是python提供给我们的序列化工具,比pickle用起来更简单一些。
shelve只提供给我们一个open方法,是用key来访问的,使用起来和字典类似。
import shelve f = shelve.open('shelve_file') f['key'] = {'int':10, 'float':9.5, 'string':'Sample data'} #直接对文件句柄操作,就可以存入数据 f.close() import shelve f1 = shelve.open('shelve_file') existing = f1['key'] #取出数据的时候也只需要直接用key获取即可,但是如果key不存在会报错 f1.close() print(existing)
这个模块有个限制,它不支持多个应用同一时间往同一个DB进行写操作。所以当我们知道我们的应用如果只进行读操作,我们可以让shelve通过只读方式打开DB
import shelve f = shelve.open('shelve_file', flag='r') existing = f['key'] f.close() print(existing)
由于shelve在默认情况下是不会记录待持久化对象的任何修改的,所以我们在shelve.open()时候需要修改默认参数,否则对象的修改不会保存。
import shelve f1 = shelve.open('shelve_file') print(f1['key']) f1['key']['new_value'] = 'this was not here before' f1.close() f2 = shelve.open('shelve_file', writeback=True) print(f2['key']) f2['key']['new_value'] = 'this was not here before' f2.close()
writeback方式有优点也有缺点。优点是减少了我们出错的概率,并且让对象的持久化对用户更加的透明了;但这种方式并不是所有的情况下都需要,首先,使用writeback以后,shelf在open()的时候会增加额外的内存消耗,并且当DB在close()的时候会将缓存中的每一个对象都写入到DB,这也会带来额外的等待时间。因为shelve没有办法知道缓存中哪些对象修改了,哪些对象没有修改,因此所有的对象都会被写入。
2.模块
import time import time import time #同一模块只导入一次 # 先从sys.modules里查看是否已经被导入 # 如果没有被导入,就依据sys.path路径取寻找模块 # 找到了就导入 import time import sys print(sys.modules.keys())
import time as t print(t.time()) 示范用法一: 有两中sql模块mysql和oracle,根据用户的输入,选择不同的sql功能 #mysql.py def sqlparse(): print('from mysql sqlparse') #oracle.py def sqlparse(): print('from oracle sqlparse') #test.py db_type=input('>>: ') if db_type == 'mysql': import mysql as db elif db_type == 'oracle': import oracle as db db.sqlparse()
示范用法二: 为已经导入的模块起别名的方式对编写可扩展的代码很有用,假设有两个模块xmlreader.py和csvreader.py,它们都定义了函数read_data(filename):用来从文件中读取一些数据,但采用不同的输入格式。可以编写代码来选择性地挑选读取模块,例如 if file_format == 'xml': import xmlreader as reader elif file_format == 'csv': import csvreader as reader data=reader.read_date(filename)
在一行导入多个模块import sys,os,re 对比import my_module,会将源文件的名称空间'my_module'带到当前名称空间中,使用时必须是my_module.名字的方式 而from 语句相当于import,也会创建新的名称空间,但是将my_module中的名字直接导入到当前的名称空间中,在当前名称空间中,直接使用名字就可以了 from my_module import read1,read2 这样在当前位置直接使用read1和read2就好了,执行时,仍然以my_module.py文件全局名称空间 #测试一:导入的函数read1,执行时仍然回到my_module.py中寻找全局变量money #demo.py from my_module import read1 money=1000 read1() ''' 执行结果: from the my_module.py spam->read1->money 1000 ''' #测试二:导入的函数read2,执行时需要调用read1(),仍然回到my_module.py中找read1() #demo.py from my_module import read2 def read1(): print('==========') read2() ''' 执行结果: from the my_module.py my_module->read2 calling read1 my_module->read1->money 1000 ''' #测试三:导入的函数read1,被当前位置定义的read1覆盖掉了 #demo.py from my_module import read1 def read1(): print('==========') read1() ''' 执行结果: from the my_module.py ========== '''
from my_module import * 把my_module中所有的不是以下划线(_)开头的名字都导入到当前位置,大部分情况下我们的python程序不应该使用这种导入方式,因为*你不知道你导入什么名字,很有可能会覆盖掉你之前已经定义的名字。而且可读性极其的差,在交互式环境中导入时没有问题。 from my_module import * #将模块my_module中所有的名字都导入到当前名称空间 print(money) print(read1) print(read2) print(change) ''' 执行结果: from the my_module.py 1000 <function read1 at 0x1012e8158> <function read2 at 0x1012e81e0> <function change at 0x1012e8268> ''' 在my_module.py中新增一行 __all__=['money','read1'] #这样在另外一个文件中用from my_module import *就这能导入列表中规定的两个名字
我们可以通过模块的全局变量__name__来查看模块名: 当做脚本运行: __name__ 等于'__main__' 当做模块导入: __name__= 模块名 作用:用来控制.py文件在不同的应用场景下执行不同的逻辑 if __name__ == '__main__': def fib(n): a, b = 0, 1 while b < n: print(b, end=' ') a, b = b, a+b print() if __name__ == "__main__": print(__name__) num = input('num :') fib(int(num))
python解释器在启动时会自动加载一些模块,可以使用sys.modules查看 在第一次导入某个模块时(比如my_module),会先检查该模块是否已经被加载到内存中(当前执行文件的名称空间对应的内存),如果有则直接引用 如果没有,解释器则会查找同名的内建模块,如果还没有找到就从sys.path给出的目录列表中依次寻找my_module.py文件。 所以总结模块的查找顺序是:内存中已经加载的模块->内置模块->sys.path路径中包含的模块 sys.path的初始化的值来自于: The directory containing the input script (or the current directory when no file is specified). PYTHONPATH (a list of directory names, with the same syntax as the shell variable PATH). The installation-dependent default. 需要特别注意的是:我们自定义的模块名不应该与系统内置模块重名。虽然每次都说,但是仍然会有人不停的犯错。 在初始化后,python程序可以修改sys.path,路径放到前面的优先于标准库被加载。 1 >>> import sys 2 >>> sys.path.append('/a/b/c/d') 3 >>> sys.path.insert(0,'/x/y/z') #排在前的目录,优先被搜索 注意:搜索时按照sys.path中从左到右的顺序查找,位于前的优先被查找,sys.path中还可能包含.zip归档文件和.egg文件,python会把.zip归档文件当成一个目录去处理。 #首先制作归档文件:zip module.zip foo.py bar.py import sys sys.path.append('module.zip') import foo,bar #也可以使用zip中目录结构的具体位置 sys.path.append('module.zip/lib/python') #windows下的路径不加r开头,会语法错误 sys.path.insert(0,r'C:UsersAdministratorPycharmProjectsa') 至于.egg文件是由setuptools创建的包,这是按照第三方python库和扩展时使用的一种常见格式,.egg文件实际上只是添加了额外元数据(如版本号,依赖项等)的.zip文件。 需要强调的一点是:只能从.zip文件中导入.py,.pyc等文件。使用C编写的共享库和扩展块无法直接从.zip文件中加载(此时setuptools等打包系统有时能提供一种规避方法),且从.zip中加载文件不会创建.pyc或者.pyo文件,因此一定要事先创建他们,来避免加载模块是性能下降。
#官网链接:https://docs.python.org/3/tutorial/modules.html#the-module-search-path 搜索路径: 当一个命名为my_module的模块被导入时 解释器首先会从内建模块中寻找该名字 找不到,则去sys.path中找该名字 sys.path从以下位置初始化 执行文件所在的当前目录 PTYHONPATH(包含一系列目录名,与shell变量PATH语法一样) 依赖安装时默认指定的 注意:在支持软连接的文件系统中,执行脚本所在的目录是在软连接之后被计算的,换句话说,包含软连接的目录不会被添加到模块的搜索路径中 在初始化后,我们也可以在python程序中修改sys.path,执行文件所在的路径默认是sys.path的第一个目录,在所有标准库路径的前面。这意味着,当前目录是优先于标准库目录的,需要强调的是:我们自定义的模块名不要跟python标准库的模块名重复,除非你是故意的,傻叉。
为了提高加载模块的速度,强调强调强调:提高的是加载速度而绝非运行速度。python解释器会在__pycache__目录中下缓存每个模块编译后的版本,格式为:module.version.pyc。通常会包含python的版本号。例如,在CPython3.3版本下,my_module.py模块会被缓存成__pycache__/my_module.cpython-33.pyc。这种命名规范保证了编译后的结果多版本共存。 Python检查源文件的修改时间与编译的版本进行对比,如果过期就需要重新编译。这是完全自动的过程。并且编译的模块是平台独立的,所以相同的库可以在不同的架构的系统之间共享,即pyc使一种跨平台的字节码,类似于JAVA火.NET,是由python虚拟机来执行的,但是pyc的内容跟python的版本相关,不同的版本编译后的pyc文件不同,2.5编译的pyc文件不能到3.5上执行,并且pyc文件是可以反编译的,因而它的出现仅仅是用来提升模块的加载速度的。 python解释器在以下两种情况下不检测缓存 1 如果是在命令行中被直接导入模块,则按照这种方式,每次导入都会重新编译,并且不会存储编译后的结果(python3.3以前的版本应该是这样) python -m my_module.py 2 如果源文件不存在,那么缓存的结果也不会被使用,如果想在没有源文件的情况下来使用编译后的结果,则编译后的结果必须在源目录下 提示: 1.模块名区分大小写,foo.py与FOO.py代表的是两个模块 2.你可以使用-O或者-OO转换python命令来减少编译模块的大小 -O转换会帮你去掉assert语句 -OO转换会帮你去掉assert语句和__doc__文档字符串 由于一些程序可能依赖于assert语句或文档字符串,你应该在在确认需要的情况下使用这些选项。 3.在速度上从.pyc文件中读指令来执行不会比从.py文件中读指令执行更快,只有在模块被加载时,.pyc文件才是更快的 4.只有使用import语句是才将文件自动编译为.pyc文件,在命令行或标准输入中指定运行脚本则不会生成这类文件,因而我们可以使用compieall模块为一个目录中的所有模块创建.pyc文件 复制代码 模块可以作为一个脚本(使用python -m compileall)编译Python源 python -m compileall /module_directory 递归着编译 如果使用python -O -m compileall /module_directory -l则只一层 命令行里使用compile()函数时,自动使用python -O -m compileall 详见:https://docs.python.org/3/library/compileall.html#module-compileall
3.包
包是一种通过使用‘.模块名’来组织python模块名称空间的方式。
1. 无论是import形式还是from...import形式,凡是在导入语句中(而不是在使用时)遇到带点的,都要第一时间提高警觉:这是关于包才有的导入语法
2. 包是目录级的(文件夹级),文件夹是用来组成py文件(包的本质就是一个包含__init__.py文件的目录)
3. import导入文件时,产生名称空间中的名字来源于文件,import 包,产生的名称空间的名字同样来源于文件,即包下的__init__.py,导入包本质就是在导入该文件
强调:
1. 在python3中,即使包下没有__init__.py文件,import 包仍然不会报错,而在python2中,包下一定要有该文件,否则import 包报错
2. 创建包的目的不是为了运行,而是被导入使用,记住,包只是模块的一种形式而已,包即模块
1.关于包相关的导入语句也分为import和from ... import ...两种,但是无论哪种,无论在什么位置,在导入时都必须遵循一个原则:凡是在导入时带点的,点的左边都必须是一个包,否则非法。可以带有一连串的点,如item.subitem.subsubitem,但都必须遵循这个原则。
2.对于导入后,在使用时就没有这种限制了,点的左边可以是包,模块,函数,类(它们都可以用点的方式调用自己的属性)。
3.对比import item 和from item import name的应用场景:
如果我们想直接使用name那必须使用后者。
需要注意的是from后import导入的模块,必须是明确的一个不能带点,否则会有语法错误,如:from a import b.c是错误语法
不管是哪种方式,只要是第一次导入包或者是包的任何其他部分,都会依次执行包下的__init__.py文件(我们可以在每个包的文件内都打印一行内容来验证一下),这个文件可以为空,但是也可以存放一些初始化包的代码。
绝对导入和相对导入
我们的最顶级包glance是写给别人用的,然后在glance包内部也会有彼此之间互相导入的需求,这时候就有绝对导入和相对导入两种方式:
绝对导入:以glance作为起始
相对导入:用.或者..的方式最为起始(只能在一个包中使用,不能用于不同目录内)
例如:我们在glance/api/version.py中想要导入glance/cmd/manage.py
4.
软件开发规范
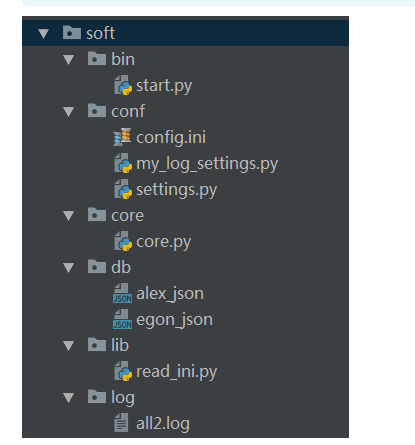
#=============>bin目录:存放执行脚本 #start.py import sys,os BASE_DIR=os.path.dirname(os.path.dirname(os.path.abspath(__file__))) sys.path.append(BASE_DIR) from core import core from conf import my_log_settings if __name__ == '__main__': my_log_settings.load_my_logging_cfg() core.run() #=============>conf目录:存放配置文件 #config.ini [DEFAULT] user_timeout = 1000 [egon] password = 123 money = 10000000 [alex] password = alex3714 money=10000000000 [yuanhao] password = ysb123 money=10 #settings.py import os config_path=r'%s\%s' %(os.path.dirname(os.path.abspath(__file__)),'config.ini') user_timeout=10 user_db_path=r'%s\%s' %(os.path.dirname(os.path.dirname(os.path.abspath(__file__))), 'db') #my_log_settings.py """ logging配置 """ import os import logging.config # 定义三种日志输出格式 开始 standard_format = '[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]' '[%(levelname)s][%(message)s]' #其中name为getlogger指定的名字 simple_format = '[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s' id_simple_format = '[%(levelname)s][%(asctime)s] %(message)s' # 定义日志输出格式 结束 logfile_dir = r'%slog' %os.path.dirname(os.path.dirname(os.path.abspath(__file__))) # log文件的目录 logfile_name = 'all2.log' # log文件名 # 如果不存在定义的日志目录就创建一个 if not os.path.isdir(logfile_dir): os.mkdir(logfile_dir) # log文件的全路径 logfile_path = os.path.join(logfile_dir, logfile_name) # log配置字典 LOGGING_DIC = { 'version': 1, 'disable_existing_loggers': False, 'formatters': { 'standard': { 'format': standard_format }, 'simple': { 'format': simple_format }, }, 'filters': {}, 'handlers': { #打印到终端的日志 'console': { 'level': 'DEBUG', 'class': 'logging.StreamHandler', # 打印到屏幕 'formatter': 'simple' }, #打印到文件的日志,收集info及以上的日志 'default': { 'level': 'DEBUG', 'class': 'logging.handlers.RotatingFileHandler', # 保存到文件 'formatter': 'standard', 'filename': logfile_path, # 日志文件 'maxBytes': 1024*1024*5, # 日志大小 5M 'backupCount': 5, 'encoding': 'utf-8', # 日志文件的编码,再也不用担心中文log乱码了 }, }, 'loggers': { #logging.getLogger(__name__)拿到的logger配置 '': { 'handlers': ['default', 'console'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕 'level': 'DEBUG', 'propagate': True, # 向上(更高level的logger)传递 }, }, } def load_my_logging_cfg(): logging.config.dictConfig(LOGGING_DIC) # 导入上面定义的logging配置 logger = logging.getLogger(__name__) # 生成一个log实例 logger.info('It works!') # 记录该文件的运行状态 if __name__ == '__main__': load_my_logging_cfg() #=============>core目录:存放核心逻辑 #core.py import logging import time from conf import settings from lib import read_ini config=read_ini.read(settings.config_path) logger=logging.getLogger(__name__) current_user={'user':None,'login_time':None,'timeout':int(settings.user_timeout)} def auth(func): def wrapper(*args,**kwargs): if current_user['user']: interval=time.time()-current_user['login_time'] if interval < current_user['timeout']: return func(*args,**kwargs) name = input('name>>: ') password = input('password>>: ') if config.has_section(name): if password == config.get(name,'password'): logger.info('登录成功') current_user['user']=name current_user['login_time']=time.time() return func(*args,**kwargs) else: logger.error('用户名不存在') return wrapper @auth def buy(): print('buy...') @auth def run(): print(''' 购物 查看余额 转账 ''') while True: choice = input('>>: ').strip() if not choice:continue if choice == '1': buy() if __name__ == '__main__': run() #=============>db目录:存放数据库文件 #alex_json #egon_json #=============>lib目录:存放自定义的模块与包 #read_ini.py import configparser def read(config_file): config=configparser.ConfigParser() config.read(config_file) return config #=============>log目录:存放日志 #all2.log [2017-07-29 00:31:40,272][MainThread:11692][task_id:conf.my_log_settings][my_log_settings.py:75][INFO][It works!] [2017-07-29 00:31:41,789][MainThread:11692][task_id:core.core][core.py:25][ERROR][用户名不存在] [2017-07-29 00:31:46,394][MainThread:12348][task_id:conf.my_log_settings][my_log_settings.py:75][INFO][It works!] [2017-07-29 00:31:47,629][MainThread:12348][task_id:core.core][core.py:25][ERROR][用户名不存在] [2017-07-29 00:31:57,912][MainThread:10528][task_id:conf.my_log_settings][my_log_settings.py:75][INFO][It works!] [2017-07-29 00:32:03,340][MainThread:12744][task_id:conf.my_log_settings][my_log_settings.py:75][INFO][It works!] [2017-07-29 00:32:05,065][MainThread:12916][task_id:conf.my_log_settings][my_log_settings.py:75][INFO][It works!] [2017-07-29 00:32:08,181][MainThread:12916][task_id:core.core][core.py:25][ERROR][用户名不存在] [2017-07-29 00:32:13,638][MainThread:7220][task_id:conf.my_log_settings][my_log_settings.py:75][INFO][It works!] [2017-07-29 00:32:23,005][MainThread:7220][task_id:core.core][core.py:20][INFO][登录成功] [2017-07-29 00:32:40,941][MainThread:7220][task_id:core.core][core.py:20][INFO][登录成功] [2017-07-29 00:32:47,222][MainThread:7220][task_id:core.core][core.py:20][INFO][登录成功] [2017-07-29 00:32:51,949][MainThread:7220][task_id:core.core][core.py:25][ERROR][用户名不存在] [2017-07-29 00:33:00,213][MainThread:7220][task_id:core.core][core.py:20][INFO][登录成功] [2017-07-29 00:33:50,118][MainThread:8500][task_id:conf.my_log_settings][my_log_settings.py:75][INFO][It works!] [2017-07-29 00:33:55,845][MainThread:8500][task_id:core.core][core.py:20][INFO][登录成功] [2017-07-29 00:34:06,837][MainThread:8500][task_id:core.core][core.py:25][ERROR][用户名不存在] [2017-07-29 00:34:09,405][MainThread:8500][task_id:core.core][core.py:25][ERROR][用户名不存在] [2017-07-29 00:34:10,645][MainThread:8500][task_id:core.core][core.py:25][ERROR][用户名不存在]
5.异常和错误
错误
1.语法错误(这种错误,根本过不了python解释器的语法检测,必须在程序执行前就改正) #语法错误示范一 if #语法错误示范二 def test: pass #语法错误示范三 print(haha 2.逻辑错误(逻辑错误) #用户输入不完整(比如输入为空)或者输入非法(输入不是数字) num=input(">>: ") int(num) #无法完成计算 res1=1/0 res2=1+'str'
异常
在python中不同的异常可以用不同的类型(python中统一了类与类型,类型即类)去标识,不同的类对象标识不同的异常,一个异常标识一种错误
s='hello' int(s)
dic={'name':'egon'}
dic['age']
l=['egon','aa'] l[3]
AttributeError 试图访问一个对象没有的树形,比如foo.x,但是foo没有属性x IOError 输入/输出异常;基本上是无法打开文件 ImportError 无法引入模块或包;基本上是路径问题或名称错误 IndentationError 语法错误(的子类) ;代码没有正确对齐 IndexError 下标索引超出序列边界,比如当x只有三个元素,却试图访问x[5] KeyError 试图访问字典里不存在的键 KeyboardInterrupt Ctrl+C被按下 NameError 使用一个还未被赋予对象的变量 SyntaxError Python代码非法,代码不能编译(个人认为这是语法错误,写错了) TypeError 传入对象类型与要求的不符合 UnboundLocalError 试图访问一个还未被设置的局部变量,基本上是由于另有一个同名的全局变量, 导致你以为正在访问它 ValueError 传入一个调用者不期望的值,即使值的类型是正确的
异常处理语法
try: 被检测的代码块 except 异常类型: try中一旦检测到异常,就执行这个位置的逻辑
s1 = 'hello' try: int(s1) except IndexError as e: print(e) except KeyError as e: print(e) except ValueError as e: print(e)
s1 = 'hello' try: int(s1) except Exception as e: print(e)
s1 = 'hello' try: int(s1) except IndexError as e: print(e) except KeyError as e: print(e) except ValueError as e: print(e) except Exception as e: print(e)
s1 = 'hello' try: int(s1) except IndexError as e: print(e) except KeyError as e: print(e) except ValueError as e: print(e) #except Exception as e: # print(e) else: print('try内代码块没有异常则执行我') finally: print('无论异常与否,都会执行该模块,通常是进行清理工作')
try..except这种异常处理机制就是取代if那种方式,让你的程序在不牺牲可读性的前提下增强健壮性和容错性 异常处理中为每一个异常定制了异常类型(python中统一了类与类型,类型即类),对于同一种异常,一个except就可以捕捉到,可以同时处理多段代码的异常(无需‘写多个if判断式’)减少了代码,增强了可读性 使用try..except的方式 1:把错误处理和真正的工作分开来 2:代码更易组织,更清晰,复杂的工作任务更容易实现; 3:毫无疑问,更安全了,不至于由于一些小的疏忽而使程序意外崩溃了;
try: raise TypeError('类型错误') except Exception as e: print(e)
class EvaException(BaseException): def __init__(self,msg): self.msg=msg def __str__(self): return self.msg try: raise EvaException('类型错误') except EvaException as e: print(e)