Hadoop 的安装和使用(基于Linux~Ubuntu的虚拟机)
❀准备工作(先下载好Hadoop安装包和Linux版的jdk1.8):
https://hadoop.apache.org/release/3.1.3.html (3.1.3 版本的,其他版本的可以参照官网:https://hadoop.apache.org/ )
下载linux版的jdk:https://www.oracle.com/java/technologies/downloads/#java8 (这里以下载jdk-8u301为例子)

一、简单了解下 Hapdoop 安装六部曲:
1,创建hadoop用户
2,更新apt(和 安装Vim 编译器)
3,安装SSH、配置SSH无密码登陆
4,安装Java环境
5,安装 Hadoop 软件,进行 Hadoop单机安装和配置(非分布式)
6,Hadoop伪分布式安装和配置
~~~~~~~~~~~~(这里介绍一些极大概率会使用的常识和命令)~~~~~~~~~~~~
■ sudo命令
是ubuntu中一种权限管理机制,授权给普通用户执行一些需要root权限执行的操作。使用sudo命令时,需要输入当前用户的密码.
■ 密码
在Linux的终端中输入密码,终端是不会显示任何你当前输入的密码,也不会提示你已经输入了多少字符密码。
■ Ubuntu终端复制粘贴快捷键
在Ubuntu终端窗口中,复制粘贴的快捷键需要加上 shift,即 粘贴是 ctrl+shift+v。
■ ~的含义
在 Linux 系统中,~ 代表的是用户的主文件夹,即 “/home/用户名” 这个目录,如你的用户名为 hadoop,
则 ~ 就代表 “/home/hadoop/”
□ ctr + c:退出当前命令行
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~打开虚拟机的乌邦图,开始操作啦~~~~~~~~~~~~~~~~~~~~~~~
过程中可能遇到无法从主机复制粘贴命令到虚拟机的解决请看文章最后,一些麻烦的解决的第0点
先进入 乌邦图的终端 : 首先按 ctrl+alt+t 打开终端窗口
1,创建hadoop用户:
①(命令如下~ 如果该过程遇到麻烦的话,可以看文章后边第一点,有删除hadoop用户的操作哈)~这里咱创建了一个叫hadoop的用户哈
sudo useradd -m hadoop -s /bin/bash
②(注意:因为是sudo命令,需要先输入当前用户的密码哈)
③ 设置咱创建的用户密码~ 为了防止忘记密码,建议密码就设置为: hadoop
sudo passwd hadoop
④ 为 创建的hadoop 用户增加管理员权限,方便部署,避免一些对新手来说比较棘手的权限问题:
sudo adduser hadoop sudo
或者:⑤ 共享文件夹,用户访问共享文件夹需要 vboxsf 权限, 终端添加hadoop用户到 vboxsf 组里,输入命令:
sudo adduser hadoop vboxsf
添加后重启
或者:⑤若不打算共享文件夹(就跳过共享文件夹操作那一步),最后一步是: 注销当前用户(点击右上角,找到当前的用户,选择注销),返回登陆界面~选择咱创建的 名为“hadoop”的用户 进入
2,更新apt(和 安装Vim 编译器)
~~~~~~~~~~~~先进入 乌邦图的终端 : 首先按 ctrl+alt+t 打开终端窗口~~~~~~~~~~~~~~
(1)更新apt:
sudo apt-get update
注意:若出现如下 “Hash校验和不符” 的提示,可通过更改软件源来解决。若没有该问题,则不需要更改。
从软件源下载某些软件的过程中,可能由于网络方面的原因出现没法下载的情况,那么建议更改软件源。
在学习Hadoop过程中,即使出现“Hash校验和不符”的提示,也不会影响Hadoop的安装。
(可以看文章的最后第二点有解决“Hash校验和不符”的操作)
(2) 安装Vim 编译器:(安装的过程当按它提示继续执行时,输入一下 y)
sudo apt-get install vim
~~~~~~~~~~~~~~~~~~~~~~~~(Vim编译的常用操作)~~~~~~~~~~~~~~~~~~~~~
vim的常用模式有分为命令模式,插入模式,正常模式,可视模式。
正常模式:主要用来浏览文本内容。一开始打开vim都是正常模式。按 Esc键 任何情况,都可以返回正常模式
插入编辑模式:用来向文本中添加内容的。在正常模式下,输入 i 键,即可进入插入编辑模式。
注意退出vim时,如果使用vim修改任何文本,需要 在正常模式下(Esc键),输入 shift+zz (或者按 :wq )进行保存,然后再退出 vim
3,安装SSH、配置SSH无密码登陆(Ubuntu 默认已安装了 SSH client,此外还需要安装 SSH server)
集群、单节点模式都需要用到 SSH 登陆(类似于远程登陆,你可以登录某台 Linux 主机,并且在上面运行命令)
① 命令:
sudo apt-get install openssh-server
② 安装后,可以使用如下命令登陆本机:(该过程按照提示,输入 yes)
ssh localhost
③ 配置成SSH无密码登陆:
exit # 退出刚才的 ssh localhost cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost ssh-keygen -t rsa # 会有提示,都按回车就可以 cat ./id_rsa.pub >> ./authorized_keys # 加入授权
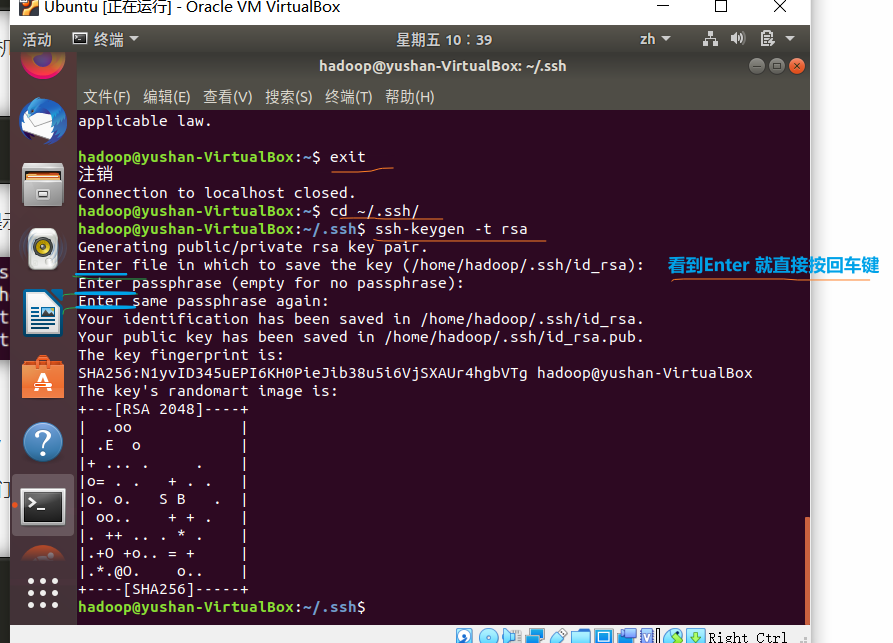
此时再用 ssh localhost 命令,无需输入密码就可以直接登陆了~~~
4,安装Java环境 (安装JDK方式(手动安装,推荐本方式))~该过程遇到的bug解决情况在文章最后,一些麻烦的解决的第三点
(例如:■ 0x00007FFC10CA2ACC指令 引用了0x0000000000000000 内存,该内存不能written,要终止程序?)
(例如:■ 如何从windows传输文件到virtualBox中ubuntu系统~即共享文件)
(例如:■ bug:虚拟机下Ubuntu共享文件夹不能显示(您没有查看共享文件的权限))
(例如:■ bug:VirtualBox 主机于虚拟机不能复制粘贴的bug)
(例如:■ bug:热键等鼠标独占的问题)
① 将jdk文件jdk-8u301-linux-x64.tar.gz下载到本地电脑,假设保存在“/home/yushan/下载/”目录下。
(该过程,先通过共享文件功能,在主机windows下将jdk压缩包拷贝的共享文件下,然后重启虚拟机)
■ 可能遇到的bug1:虚拟机下Ubuntu共享文件夹不能显示 解决:在主机windows下将jdk压缩包(要共享的文件)共享,重新拷贝到共享文件夹下,然后Ubuntu重启(点击菜单栏:控制-> 重启) ■ 可能遇到的bug2:您没有查看共享文件的权限~
解决:终端添加hadoop用户到 vboxsf 组里,输入命令: sudo adduser hadoop vboxsf 然后重启
② ctr+alt+t 进入终端(当前用户是hadoop哈),执行以下命令:
cd /usr/lib sudo mkdir jvm #创建/usr/lib/jvm目录用来存放JDK文件 cd ~ #进入hadoop用户的主目录 cd 下载 #注意区分大小写字母,刚才已经通过FTP软件把JDK安装包jdk-8u301-linux-x64.tar.gz上传到该目录下 sudo tar -zxvf ./jdk-8u301-linux-x64.tar.gz -C /usr/lib/jvm #把JDK文件解压到/usr/lib/jvm目录下
③ JDK文件解压缩以后,可以执行如下命令到/usr/lib/jvm目录查看一下:(可以看到,在/usr/lib/jvm目录下有个jdk1.8.0_301目录)
cd /usr/lib/jvm ls
④ 设置环境变量:
cd ~ vim ~/.bashrc
⑤ 使用vim编辑器, 进入 插入模式,按 i 键,(在文件的开头位置,添加如下几行内容):
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_301
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
⑥ 按Esc 键,进入vim的正常模式,然后 输入shift+zz(保存并退出)
⑦ 让.bashrc文件的配置立即生效:
source ~/.bashrc
⑧ 查看是否安装成功:
java -version
看到java的版本,则配置java环境成功啦
5,安装 Hadoop(默认安装的Hadoop 就是单机版的啦,即单 Java 进程)
① 通过windows 在官网下载好hadoop的安装包,放到共享文件夹里,然后启动虚拟机~
然后把 hadoop的安装包复制粘贴到 文件夹的下载里~
② 将 Hadoop 安装至 /usr/local/ 中:
sudo tar -zxf ~/下载/hadoop-3.1.3.tar.gz -C /usr/local # 解压到/usr/local中 cd /usr/local/ sudo mv ./hadoop-3.1.3/ ./hadoop # 将文件夹名改为hadoop sudo chown -R hadoop ./hadoop # 修改文件权限
③ Hadoop 的解压和版本查看:
cd /usr/local/hadoop ./bin/hadoop version
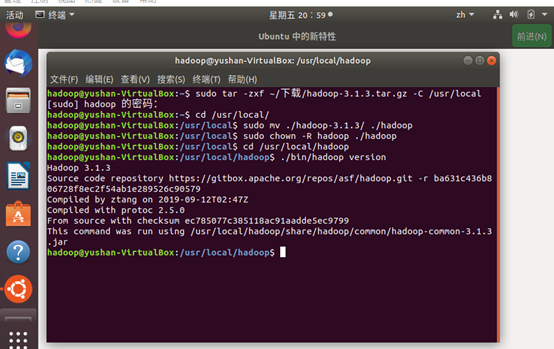
~~~~~~~看到了hadoop版本,则安装成功啦
❀ 可选操作,测试一下单机版的hadoop运行情况哈
在此我们选择运行 grep 例子(hadoop的jar包有的一个例子~运行 ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar 可以看到所有例子), 我们将 input 文件夹中的所有文件作为输入,筛选当中符合正则表达式 dfs[a-z.]+ 的单词并统计出现的次数,最后输出结果到 output 文件夹中。
① 命令:
cd /usr/local/hadoop mkdir ./input cp ./etc/hadoop/*.xml ./input # 将配置文件作为输入文件 ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep ./input ./output 'dfs[a-z.]+' cat ./output/* # 查看运行结果
② 执行结果如下:

③ 需要先将 ./output 删除。 注意,Hadoop 默认不会覆盖结果文件,导致再次运行上面实例会提示出错。
rm -r ./output
~~~~~~~~~~~~~未完待续,《Hadoop安装最后一步~Hadoop伪分布式配置》~~~~~~~~~~~~
参考文章:https://www.cnblogs.com/shan333/p/15333455.html
~~~~~~~~~~~~~~~~~~~~~~~~~~~(最后,一些麻烦的解决)~~~~~~~~~~~~~~~~~~~~~~~
第0点:无法从主机复制粘贴命令到虚拟机:
步骤:设置 -》存储 -》控制器:SATA -》...
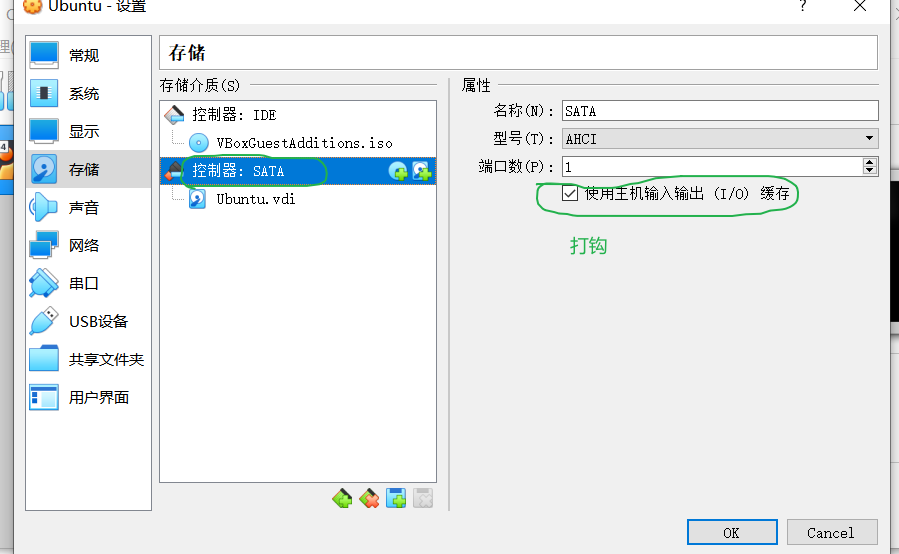
第一点:删除hadoop用户的操作
① 执行userdel命令:
sudo userdel XXX //XXX为需要删除的用户名
② 删除用户:
sudo rm -rf /home/XXX //XXX为需要删除的用户名
③ 删除用户权限相关配置,
先删除/home目录下的文件:
cd /home rm -rf XXX //XXX为需要删除的用户名
再删除/etc/passwd下的用户:
cat /etc/passwd
④ 删除/etc/group下的用户组文件:
cat /etc/group
⑤删除/var/spool/mail下的邮箱文件:
cd /var/spool/mail rm -rf XXX //XXX为需要删除的用户信息
参考文章:https://blog.csdn.net/CAU_Ayao/article/details/83502880
第二点:解决: “Hash校验和不符” 【该过程提示要输入密码,你就输入一下哈】
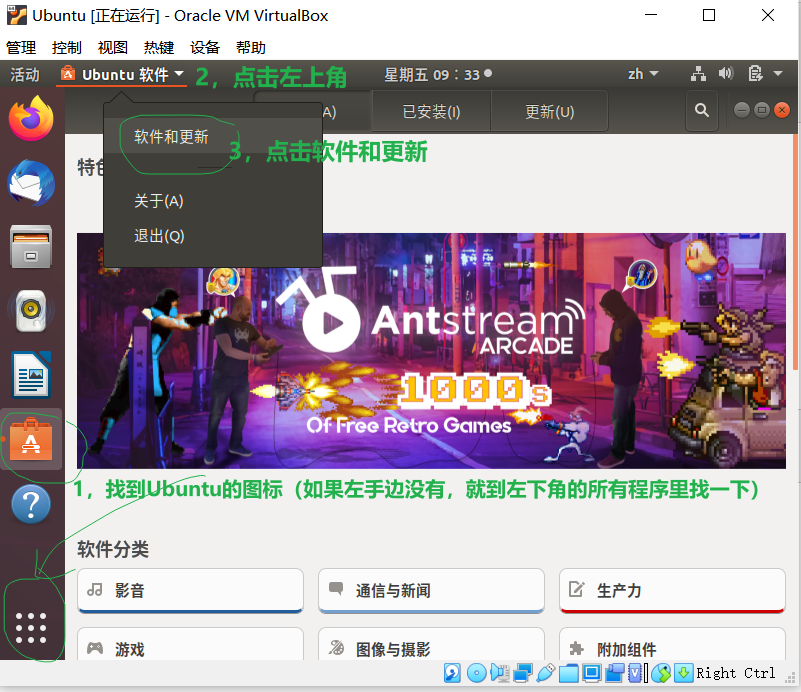
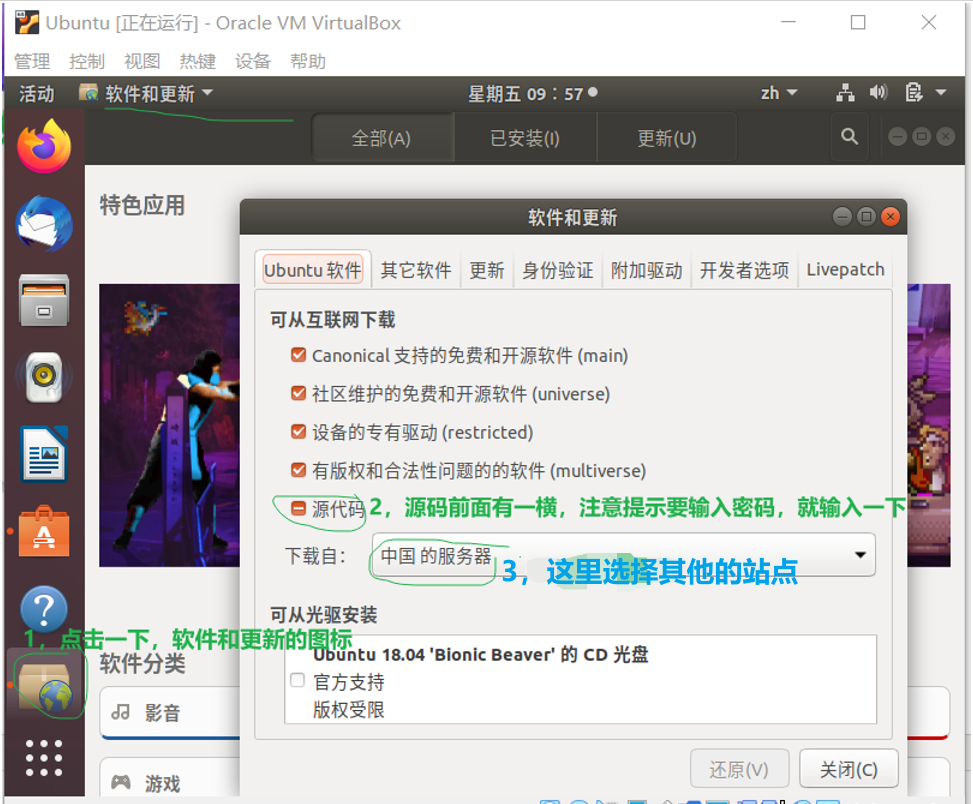
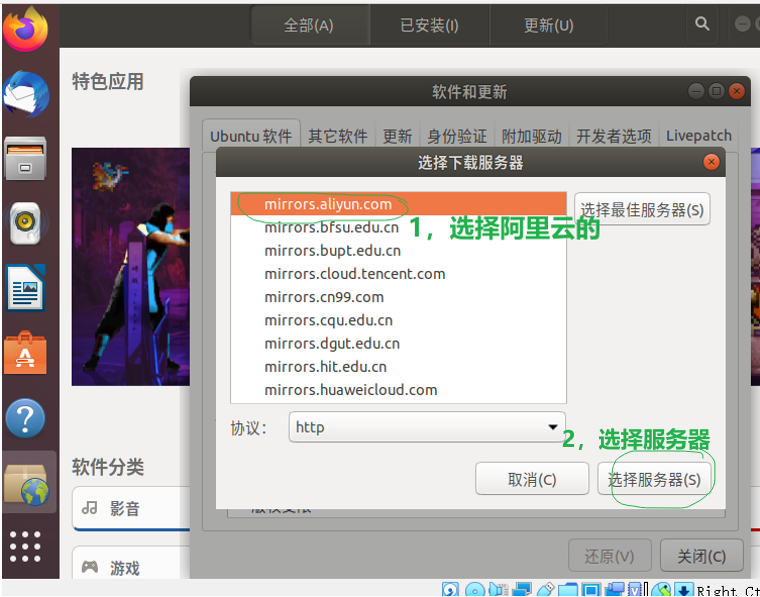
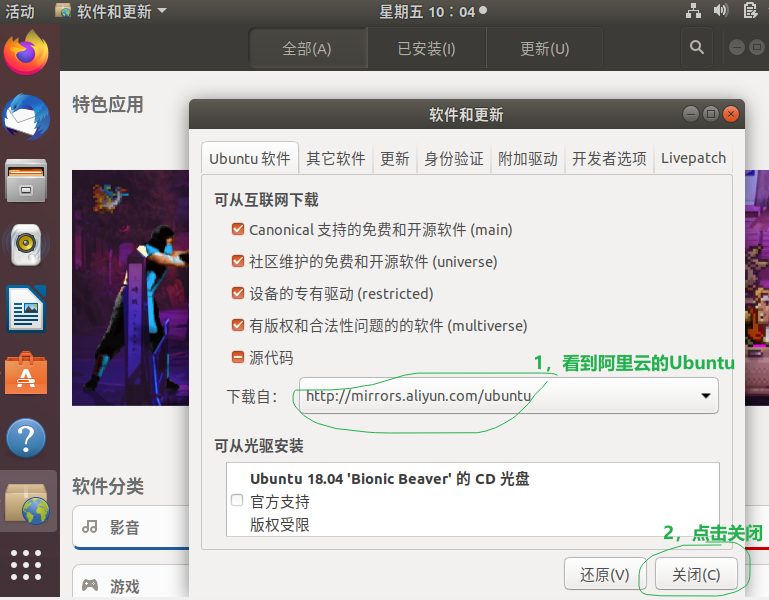
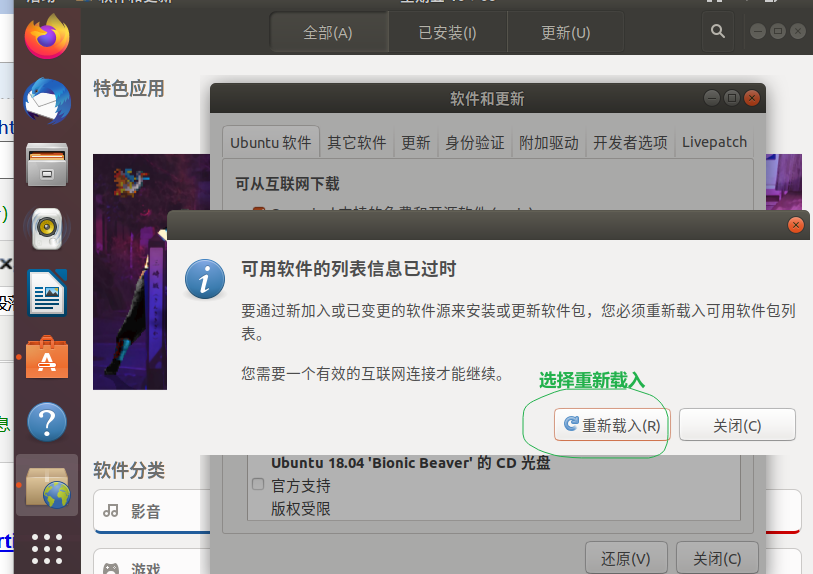
参考文章:http://dblab.xmu.edu.cn/blog/install-hadoop/
第三点:解决:安装Java环境 ~该过程遇到的bug
(例如:■ 0x00007FFC10CA2ACC指令 引用了0x0000000000000000 内存,该内存不能written,要终止程序?)
终极解决法(关闭hyper -V):参考文章 https://www.cnblogs.com/shan333/p/15362864.html
解决方法一: 重启ubuntu 解决方法二:重启windows(成功解决)~临时解决一下 解决方法三:(如果是win7系统的话)修改主机文件~参考文章 https://blog.csdn.net/weixin_43802738/article/details/104714241
(例如:■ 如何从windows传输文件到virtualBox中ubuntu系统~即共享文件)
解决:参考我写的上一篇文章里的 " 可选操作~对于需要安装hadoop 建议操作搞一波" 部分内容
(例如:■ bug:虚拟机下Ubuntu共享文件夹不能显示(您没有查看共享文件的权限))
解决:终端添加hadoop用户到 vboxsf 组里,输入命令: sudo adduser hadoop vboxsf
然后,在主机windows下将jdk压缩包(要共享的文件)共享,重新拷贝到共享文件夹下,然后Ubuntu重启(点击:控制-> 重启)
重启,重启是王道。
(例如:■ bug:VirtualBox 主机于虚拟机不能复制粘贴的bug)~ VBox -》 设置 -》 存储 -》......
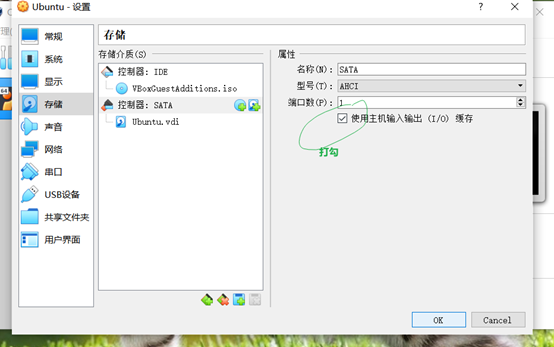
(例如:■ bug:热键等鼠标独占的问题)
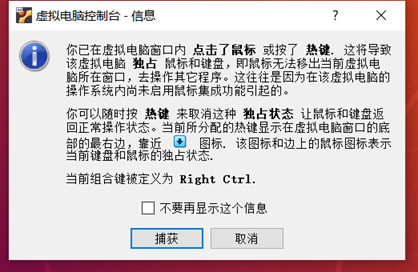
解决:按右手边的ctr 键