算法基础~链表~求两个链表的交点(不考虑时间、空间复杂度)
✿ 1、求交点结点~思路:找到同一个结点,指针指向的同一个结点地址相同,(地址在内存分配上具有唯一特性) 可以使用工具 set集合,因为唯一性+遍历结束的null只有一个
(唯一性)就是set的特性。
● 2、使用set集合原因:无序,不允许有重复的元素【唯一性】,只允许有一个null元素对象。【链表遍历结束就是null】
3,直接先看一下代码,再看过程分析:
public class Solution { public: ListNode *getIntersectionNode(ListNode *headA, ListNode *headB){ std:: set<ListNode*> node_set; //将A链表"装"到set集合中 while(headA){ node_set.insert(headA); headA = headA->next; } //循环遍历B链表,依次与set中的每个元素做地址比较 while(headB){ //找到地址相同 if(node_set.find(headB) != node_set.end()){ return headB; } headB = headB->next; } return NULL; } }
4、过程分析:
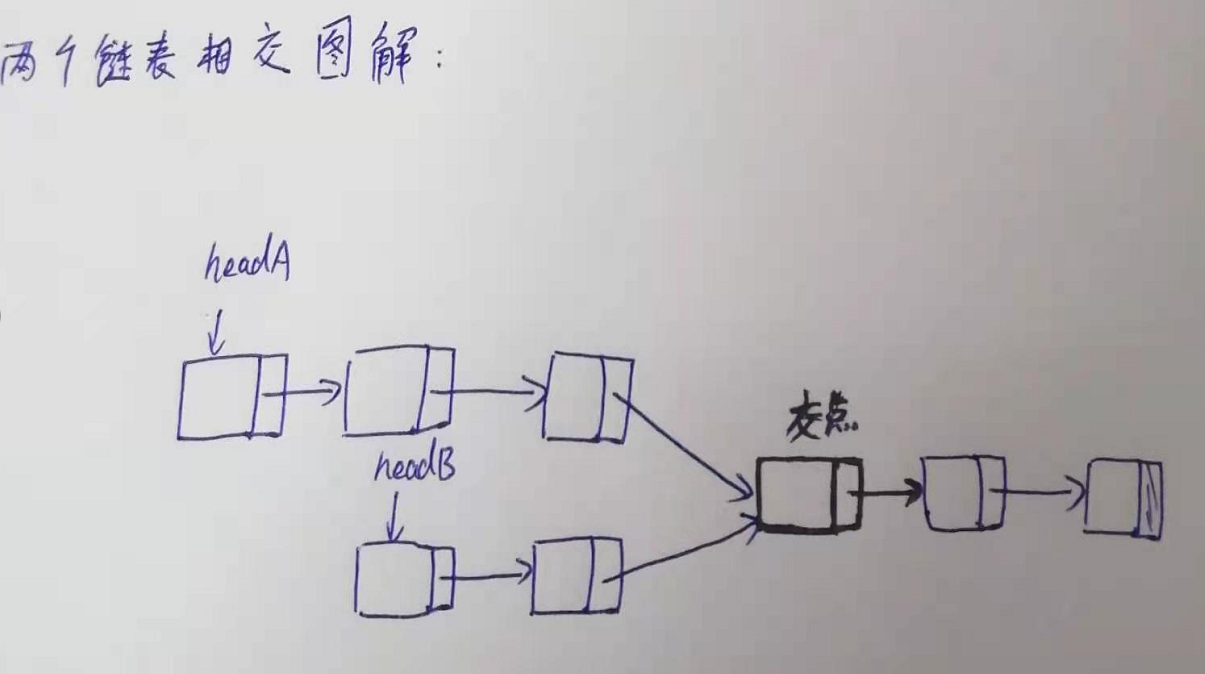
思路:(1) 参考链表A“装”到set 集合中,然后B链表从头到尾依次去与“装”到 set 集合中的每个元素做地址的比较。
【为什么要以其中一条链为参照链? because:链表的长度不一,
例如图解A链表的长度明显就是长于B链表的,如果不以其中某一条链表为参照链,则A、B链表不可能相遇!】
(2)具体代码思路:①遍历A链表,将A中结点对应的指针(地址),插入set集合;
② 遍历B链表,将B中结点对应的指针(地址),在set中查找,
发现的set中第一个相同结点,即是两个链表的交点。
ps:本题中的时间复杂度是O(nlogn),即set集合查找时复杂度是logn,而B链还需要遍历n个复杂度,所以最终复杂度 nlogn;
空间复杂度是O(n).
ps:在数据结构中集合set、map常常作为工具使用【键值对、封装好的增删改查】