随着公司业务的增长,数据量越来越大,原有的数据节点的容量已经不能满足存储数据的需求,需要在原有集群基础上动态添加新的数据节点。
-
环境准备
(1)在hadoop104主机上再克隆一台hadoop105主机
(2)修改IP地址和主机名称
sudo vim /etc/sysconfig/network 修改主机名称
sudo vim /etc/sysconfig/network-scripts/ifcfg-eth0 修改Ip
sudo vim /etc/udev/rules.d/70-persistent-net.rules 修改网卡
删除eth0 修改eth1为0
(3)新节点没有hadoop、jdk,选台机器拷贝至新节点 (拷贝前提试hosts有集群ip用户名、可以互通)
rsync -av /opt/module/jdk1.8.0_192 hadoop105:/opt/module/
rsync -av /opt/module/hadoop-2.7.2 hadoop105:/opt/module/
sudo rsync -av /etc/profile hadoop105:/etc/profile
source /etc/profile
(4)删除原来HDFS文件系统留存的文件(/opt/module/hadoop-2.7.2/data和log)
rm data logs -rf
(5)(1)直接启动DataNode,即可关联到集群
[hfx@hadoop105 hadoop-2.7.2]$ sbin/hadoop-daemon.sh start datanode
[hfx@hadoop105 hadoop-2.7.2]$ sbin/yarn-daemon.sh start nodemanager
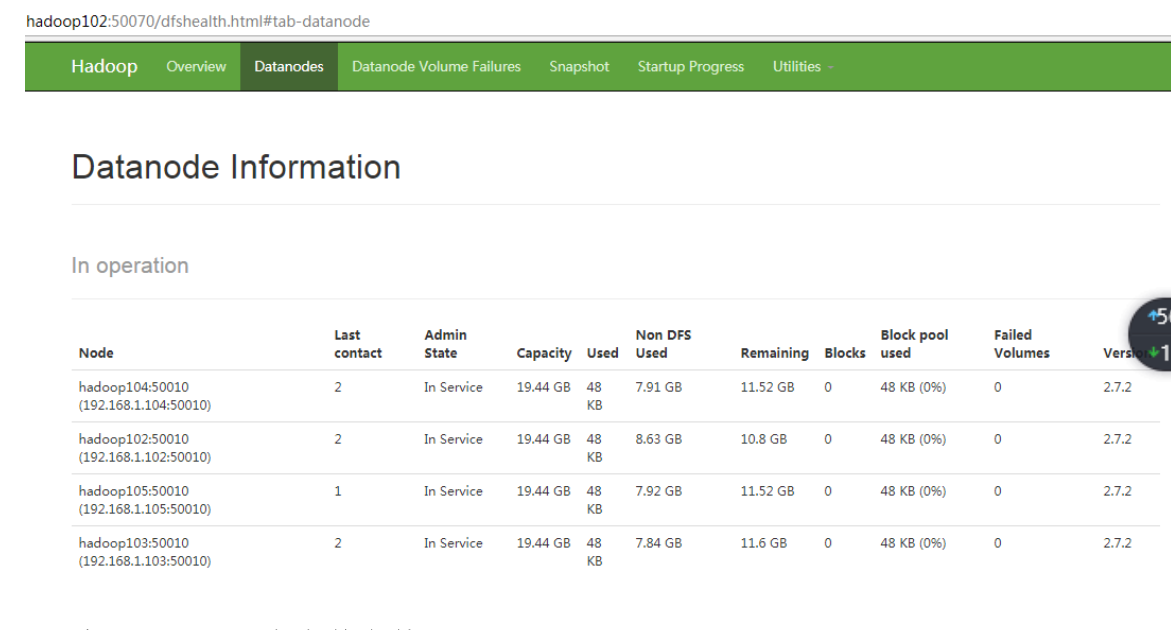
(6)如果数据不均衡,可以用命令实现集群的再平衡 [hfx@hadoop102 sbin]$ ./start-balancer.sh
配置免密
ssh-keygen -t rsa 3个回车
cd .ssh/
ssh-copy-id hadoop102 yes