一.认识Http请求
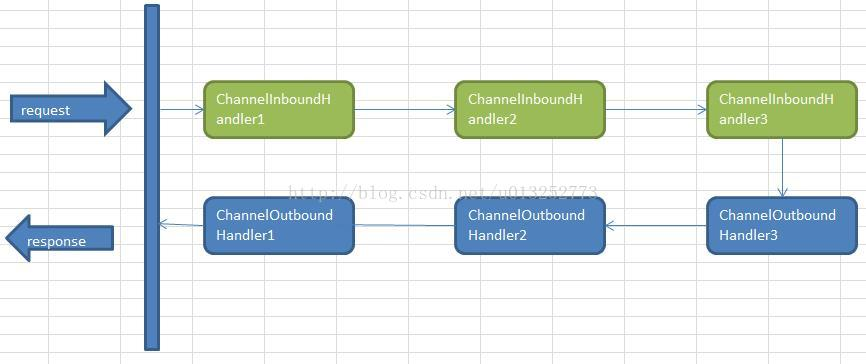
Netty中,可以注册多个handler。ChannelInboundHandler按照注册的先后顺序执行;ChannelOutboundHandler按照注册的先后顺序逆序执行,如下图所示,按照注册的先后顺序对Handler进行排序,request进入Netty后的执行顺序为:
在动手写Netty框架之前,我们先要了解http请求的组成,如下图:

- HTTP Request 第一部分是包含的头信息
- HttpContent 里面包含的是数据,可以后续有多个 HttpContent 部分
- LastHttpContent 标记是 HTTP request 的结束,同时可能包含头的尾部信息
- 完整的 HTTP request,由1,2,3组成
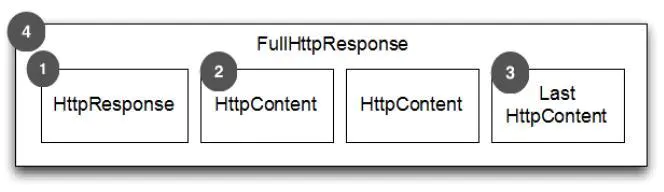
- HTTP response 第一部分是包含的头信息
- HttpContent 里面包含的是数据,可以后续有多个 HttpContent 部分
- LastHttpContent 标记是 HTTP response 的结束,同时可能包含头的尾部信息
- 完整的 HTTP response,由1,2,3组成
从request的介绍我们可以看出来,一次http请求并不是通过一次对话完成的,他中间可能有很次的连接。每一次对话都会建立一个channel,并且一个ChannelInboundHandler一般是不会同时去处理多个Channel的。
如何在一个Channel里面处理一次完整的Http请求?这就要用到我们上图提到的FullHttpRequest,我们只需要在使用netty处理channel的时候,只处理消息是FullHttpRequest的Channel,这样我们就能在一个ChannelHandler中处理一个完整的Http请求了。
HTTP基础实现类:

二.HTTP编码器、解码器
Netty为HTTP消息提供了ChannelHandler编码器和解码器:

网络通信最终都是通过字节流进行传输的。 ByteBuf 是 Netty 提供的一个字节容器,其内部是一个字节数组。 当我们通过 Netty 传输数据的时候,就是通过 ByteBuf 进行的。
HTTP Server 端用于接收 HTTP Request,然后发送 HTTP Response。因此我们只需要 HttpRequestDecoder 和 HttpResponseEncoder 即可。
为了能够表示 HTTP 中的各种消息,Netty 设计了抽象了一套完整的 HTTP 消息结构图,核心继承关系如下图所示。
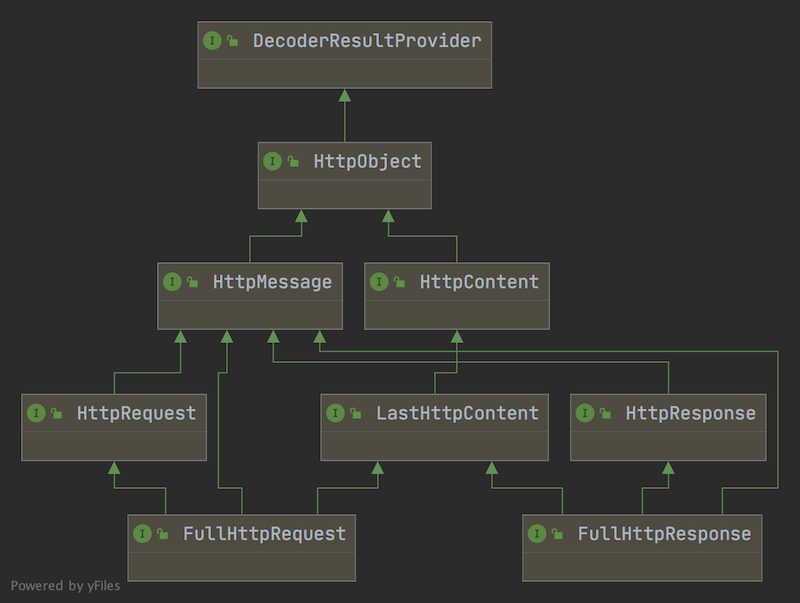
- HttpObject : 整个 HTTP 消息体系结构的最上层接口。HttpObject 接口下又有 HttpMessage 和HttpContent两大核心接口。
- HttpMessage: 定义 HTTP 消息,为HttpRequest和HttpResponse提供通用属性
- HttpRequest : HttpRequest对应 HTTP request。通过 HttpRequest 我们可以访问查询参数(Query Parameters)和 Cookie。和 Servlet API 不同的是,查询参数是通过QueryStringEncoder和QueryStringDecoder来构造和解析查询查询参数。
- HttpResponse: HttpResponse 对应 HTTP response。和HttpMessage相比,HttpResponse 增加了 status(相应状态码) 属性及其对应的方法。
- HttpContent: 分块传输编码(Chunked transfer encoding)是超文本传输协议(HTTP)中的一种数据传输机制(HTTP/1.1 才有),允许 HTTP 由应用服务器发送给客户端应用( 通常是网页浏览器)的数据可以分成多“块”(数据量比较大的情况)。我们可以把 HttpContent 看作是这一块一块的数据。
- LastHttpContent : 标识 HTTP 请求结束,同时包含 HttpHeaders 对象。
- FullHttpRequest 和 FullHttpResponse : HttpMessage 和 HttpContent 聚合后得到的对象。

Netty 自带了常用的编解码器:
- HttpRequestEncoder: 编码器,用于客户端,向服务器发送请求
- HttpResponseEecoder: 编码器,用于服务端,向客户端发送响应
- HttpResponseDecoder: 解码器,用于客户端,接收来自服务端的请求
- HttpRequestDecoder:解码器,用于服务端,接收来自客户端的请求
除了独立的编码器、解码器,Netty还提供了编解码器:
- HttpClientCodec: 用于客户端的编解码器,等效于HttpRequestEncoder和HttpResponseDecoder的组合
- HttpServerCodec:用于服务端的编解码器,等效于HttpRequsetDecoder和 HttpResponseEncoder的组合
- HttpObjectAggregator:聚合器,由于 HTTP 的请求和响应可能由许多部分组成,需要聚合它们以形成完整的消息,HttpObjectAggregator 可以将多个消息部分合并为 FullHttpRequest 或者 FullHttpResponse 消息。
- HttpContentCompressor:压缩,用户服务端,压缩要传输的数据,支持 gzip 和 deflate 压缩格式。
- HttpContentDecompressor:解压缩,用于客户端,解压缩服务端传输的数据。
@Override protected void initChannel(Channel ch) throws Exception { ChannelPipeline pipeline = ch.pipeline(); SSLEngine sslEngine = sslContext.newEngine(ch.alloc()); if (isClient) { //使用 HTTPS,添加 SSL 认证 pipeline.addFirst("ssl", new SslHandler(sslEngine, true)); pipeline.addLast("codec", new HttpClientCodec()); //1、建议开启压缩功能以尽可能多地减少传输数据的大小 //2、客户端处理来自服务器的压缩内容 pipeline.addLast("decompressor", new HttpContentDecompressor()); }else { pipeline.addFirst("ssl", new SslHandler(sslEngine)); //HttpServerCodec:将HTTP客户端请求转成HttpRequest对象,将HttpResponse对象编码成HTTP响应发送给客户端。 pipeline.addLast("codec", new HttpServerCodec()); //服务端,压缩数据 pipeline.addLast("compressor", new HttpContentCompressor()); } //目的多个消息转换为一个单一的FullHttpRequest或是FullHttpResponse //将最大的消息为 512KB 的HttpObjectAggregator 添加到 ChannelPipeline //在消息大于这个之后会抛出一个 TooLongFrameException 异常。 pipeline.addLast("aggregator", new HttpObjectAggregator(512 * 1024)); }
tips:当使用 HTTP 时,建议开启压缩功能以尽可能多地减小传输数据的大小。虽然压缩会带来一些 CPU 时钟周期上的开销。
三.拆包和粘包的解决方案
TCP 传输过程中,客户端发送了两个数据包,而服务端却只收到一个数据包,客户端的两个数据包粘连在一起,称为粘包;
TCP 传输过程中,客户端发送了两个数据包,服务端虽然收到了两个数据包,但是两个数据包都是不完整的,或多了数据,或少了数据,称为拆包;
发生TCP粘包、拆包主要是由于下面一些原因:
1、应用程序写入的数据大于套接字缓冲区大小,这将会发生拆包。
2、应用程序写入数据小于套接字缓冲区大小,网卡将应用多次写入的数据发送到网络上,这将会发生粘包。
3、进行MSS(最大报文长度)大小的TCP分段,当TCP报文长度-TCP头部长度>MSS的时候将发生拆包。
4、接收方法不及时读取套接字缓冲区数据,这将发生粘包。
Netty 预定义了一些解码器用于解决粘包和拆包现象,其中大体分为两类:
基于分隔符的协议:在数据包之间使用定义的字符来标记消息或者消息段的开头或者结尾。这样,接收端通过这个字符就可以将不同的数据包拆分开。
基于长度的协议:发送端给每个数据包添加包头部,头部中应该至少包含数据包的长度,这样接收端在接收到数据后,通过读取包头部的长度字段,便知道每一个数据包的实际长度了。
空闲的连接和超时
检测空闲连接以及超时对于及时释放资源来说是至关重要的。由于这是一项常见的任务,Netty 特地为它提供了几个 ChannelHandler 实现。

示例:
当使用通常的发送心跳消息到远程节点的方法时,如果在 60 秒之内没有接收或者发送任何的数据, 我们将如何得到通知;如果没有响应,则连接会被关闭。
public class IdleStateHandlerInitializer extends ChannelInitializer<Channel> { @Override protected void initChannel(Channel ch) throws Exception { ChannelPipeline pipeline = ch.pipeline(); //IdleStateHandler 将 在被触发时发送一 个 IdleStateEvent 事件 pipeline.addLast(new IdleStateHandler(0, 0, 60, TimeUnit.SECONDS)); // 将一个 HeartbeatHandler 添加到ChannelPipeline 中 pipeline.addLast(new HearbeatHandler()); } //实现userEventTriggred()方法以发送心跳消息 public static final class HearbeatHandler extends ChannelInboundHandlerAdapter { private static final ByteBuf HEARTBEAT_SEQUENCE = Unpooled.unreleasableBuffer(Unpooled.copiedBuffer("HEARTBEAT", CharsetUtil.ISO_8859_1)); @Override public void userEventTriggered(ChannelHandlerContext ctx, Object evt) throws Exception { //发送心跳消息,并在发送失败时关闭该连接 if (evt instanceof IdleStateEvent) { ctx.writeAndFlush(HEARTBEAT_SEQUENCE.duplicate()) .addListener(ChannelFutureListener.CLOSE_ON_FAILURE); } else { //不是 IdleStateEvent 事件,所以将它传递 给下一个 ChannelInboundHandler super.userEventTriggered(ctx, evt); } } } }
如果连接超过60秒没有接收或者发送任何的数据,那么IdleStateHandler 将会使用一个 IdleStateEvent 事件来调用 fireUserEventTriggered()方法。HeartbeatHandler 实现 了 userEventTriggered()方法,如果这个方法检测到 IdleStateEvent 事件,它将会发送心 跳消息,并且添加一个将在发送操作失败时关闭该连接的 ChannelFutureListener 。
基于分隔符的协议
基于分隔符的(delimited)消息协议使用定义的字符来标记的消息或者消息段(通常被称 为帧)的开头或者结尾。由RFC文档正式定义的许多协议(如SMTP、POP3、IMAP以及Telnet1) 都是这样的。此外,当然,私有组织通常也拥有他们自己的专有格式。无论你使用什么样的协 议,下表中列出的解码器都能帮助你定义可以提取由任意标记(token)序列分隔的帧的自 定义解码器。

解码基于分隔符的协议和基于长度的协议:

public class LineBasedHandlerInitializer extends ChannelInitializer<Channel> { @Override protected void initChannel(Channel ch) throws Exception { ch.pipeline().addLast( // 将提取到的桢转发给下一个Channelhandler new LineBasedFrameDecoder(64 * 1024), // 添加 FrameHandler 以接收帧 new FrameHandler() ); } public static final class FrameHandler extends SimpleChannelInboundHandler<ByteBuf> { @Override protected void messageReceived(ChannelHandlerContext ctx, ByteBuf msg) throws Exception { //Do something with the data extracted from the frame } } }
如果你正在使用除了行尾符之外的分隔符分隔的帧,那么你可以以类似的方式使用 DelimiterBasedFrameDecoder,只需要将特定的分隔符序列指定到其构造函数即可。
这些解码器是实现你自己的基于分隔符的协议的工具。
作为示例,我们将使用下面的协议规范:
- 传入数据流是一系列的帧,每个帧都由换行符( )分隔;
- 每个帧都由一系列的元素组成,每个元素都由单个空格字符分隔;
- 一个帧的内容代表一个命令,定义为一个命令名称后跟着数目可变的参数。
我们用于这个协议的自定义解码器将定义以下类:
- Cmd——将帧(命令)的内容存储在ByteBuf中,一个ByteBuf用于名称,另一个 用于参数;
- CmdDecoder——从被重写了的 decode()方法中获取一行字符串,并从它的内容构建 一个 Cmd 的实例;
- CmdHandler——从CmdDecoder获取解码的Cmd对象,并对它进行一些处理;
- CmdHandlerInitializer——为了简便起见,我们将会把前面的这些类定义为专门 的 ChannelInitializer 的嵌套类,其将会把这些 ChannelInboundHandler 安装到 ChannelPipeline 中。
public class CmdHandlerInitializer extends ChannelInitializer<Channel> { public static final byte SPACE = (byte)' '; @Override protected void initChannel(Channel ch) throws Exception { ChannelPipeline pipeline = ch.pipeline(); // 添加 CmdDecoder 以提取 Cmd 对象,并将它转发给下 一个 ChannelInboundHandler pipeline.addLast(new CmdDecoder(64 * 1024)); //添加CmdHandler以接收和处理Cmd对象 pipeline.addLast(new CmdHandler()); } /** * Cmd POJO */ public static final class Cmd { private final ByteBuf name; private final ByteBuf args; public Cmd(ByteBuf name, ByteBuf args) { this.name = name; this.args = args; } public ByteBuf name(){ return name; } public ByteBuf args(){ return args; } } /** * Cmd解码器 */ public static final class CmdDecoder extends LineBasedFrameDecoder { public CmdDecoder(int maxLength) { super(maxLength); } @Override protected Object decode(ChannelHandlerContext ctx, ByteBuf buffer) throws Exception { //从ByteBuf中提取由行尾符序列分隔的帧 ByteBuf frame = (ByteBuf) super.decode(ctx, buffer); //如果输入中没有帧,则返回null if (frame == null) { return null; } //查找第一个空格字符的索引。前面是命令名称,接着是参数 int index = frame.indexOf(frame.readerIndex(), frame.writerIndex(), SPACE); //使用包含有命令名称和参数的切片创建新的Cmd对象 return new Cmd(frame.slice(frame.readerIndex(), index), frame.slice(index + 1, frame.writerIndex())); } } /** * CMdHandler */ public static final class CmdHandler extends SimpleChannelInboundHandler<Cmd> { @Override protected void channelRead0(ChannelHandlerContext ctx, Cmd msg) throws Exception { //处理传经ChannelPipeline的Cmd对象 //Do something with the command } } }
基于长度的协议
基于长度的协议通过将它的长度编码到帧的头部来定义帧,而不是使用特殊的分隔符来标记 它的结束。下表列出了Netty提供的用于处理这种类型的协议的两种解码器。

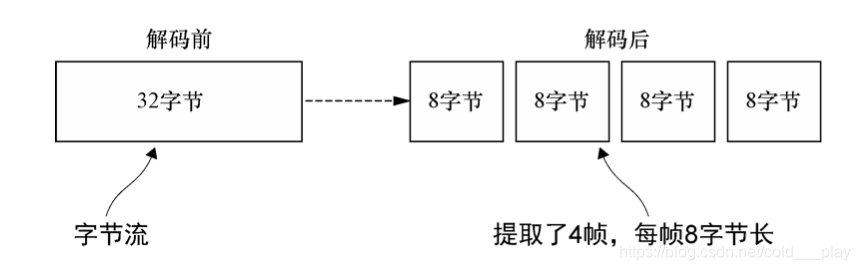
下图展示了 FixedLengthFrameDecoder 的功能,其在构造时已经指定了帧长度为 8 字节。
你将经常会遇到被编码到消息头部的帧大小不是固定值的协议。为了处理这种变长帧,你可以使用 LengthFieldBasedFrameDecoder,它将从头部字段确定帧长,然后从数据流中提取指定的字节数。
示例:长度字段在帧中的偏移量为 0,并且长度为 2 字节。

LengthFieldBasedFrameDecoder 是 Netty 基于长度协议解决拆包粘包问题的一个重要的类,主要结构就是 header+body 结构。我们只需要传入正确的参数就可以发送和接收正确的数据,那吗重点就在于这几个参数的意义。下面我们就具体了解一下这几个参数的意义。先来看一下LengthFieldBasedFrameDecoder主要的构造方法:
public LengthFieldBasedFrameDecoder( int maxFrameLength, int lengthFieldOffset, int lengthFieldLength, int lengthAdjustment, int initialBytesToStrip)
maxFrameLength:最大帧长度。也就是可以接收的数据的最大长度。如果超过,此次数据会被丢弃。
lengthFieldOffset:长度域偏移。就是说数据开始的几个字节可能不是表示数据长度,需要后移几个字节才是长度域。
lengthFieldLength:长度域字节数。用几个字节来表示数据长度。
lengthAdjustment:数据长度修正。因为长度域指定的长度可以使 header+body 的整个长度,也可以只是body的长度。如果表示header+body的整个长度,那么我们需要修正数据长度。
initialBytesToStrip:跳过的字节数。如果你需要接收 header+body 的所有数据,此值就是0,如果你只想接收body数据,那么需要跳过header所占用的字节数。
LengthFieldBasedFrameDecoder 提供了几个构造函数来支持各种各样的头部配置情 况。下面的代码展示了如何使用其 3 个构造参数分别为 maxFrameLength、lengthField- Offset 和 lengthFieldLength 的构造函数。在这个场景中,帧的长度被编码到了帧起始的前 8 个字节中。
//解码基于长度的协议 public class LengthBasedInitializer extends ChannelInitializer<Channel> { @Override protected void initChannel(Channel ch) throws Exception { ChannelPipeline pipeline = ch.pipeline(); pipeline.addLast(new LengthFieldBasedFrameDecoder(64 * 1024, 0, 8)); //添加FrameHandler以处理每个帧 pipeline.addLast(new FrameHandler()); } public static final class FrameHandler extends SimpleChannelInboundHandler<ByteBuf> { @Override protected void channelRead0(ChannelHandlerContext ctx, ByteBuf msg) throws Exception { //处理帧数据 //Do something with the frame } } }
tips:UDP协议不会发生沾包或拆包现象, 因为UDP是基于报文发送的,在UDP首部采用了16bit来指示UDP数据报文的长度,因此在应用层能很好的将不同的数据报文区分开。
写大型数据
因为网络饱和的可能性,如何在异步框架中高效地写大块的数据是一个特殊的问题。由于写 操作是非阻塞的,所以即使没有写出所有的数据,写操作也会在完成时返回并通知 ChannelFuture。当这种情况发生时,如果仍然不停地写入,就有内存耗尽的风险。所以在写大型数据 时,需要准备好处理到远程节点的连接是慢速连接的情况,这种情况会导致内存释放的延迟。
NIO 的零拷贝特性这种特性消除了将文件 的内容从文件系统移动到网络栈的复制过程。所有的这一切都发生在 Netty 的核心中,所以应用 程序所有需要做的就是使用一个 FileRegion 接口的实现,其在 Netty 的 API 文档中的定义是:
“通过支持零拷贝的文件传输的 Channel 来发送的文件区域。”
示例:使用FileRegion传输文件的内容:
File file = new File("big.txt"); //创建一个FileInputStream FileInputStream in = new FileInputStream(file); //以该文件的完整长度创建一个DefaultFileRegion FileRegion region = new DefaultFileRegion(in.getChannel(), 0, file.length()); //发送该DefaultFileRegion,并注册一个ChannelFutureLIstener channel.writeAndFlush(region).addListener( new ChannelFutureListener() { @Override public void operationComplete(ChannelFuture future) throws Exception { if (!future.isSuccess()) { //处理失败 Throwable cause = future.cause(); cause.printStackTrace(); } } } );
这个示例只适用于文件内容的直接传输,不包括应用程序对数据的任何处理。在需要将数据 从文件系统复制到用户内存中时,可以使用 ChunkedWriteHandler,它支持异步写大型数据 流,而又不会导致大量的内存消耗。
关键是interface ChunkedInput<B>,其中类型参数 B 是 readChunk()方法返回的 类型。Netty 预置了该接口的 4 个实现,如下表中所列出的。每个都代表了一个将由 ChunkedWriteHandler 处理的不定长度的数据流。
示例:使用 ChunkedStream 传输文件内容
下面代码说明了 ChunkedStream 的用法,它是实践中最常用的实现。所示的类使用 了一个 File 以及一个 SslContext 进行实例化。当 initChannel()方法被调用时,它将使用所示的 ChannelHandler 链初始化该 Channel。当 Channel 的状态变为活动的时,WriteStreamHandler 将会逐块地把来自文件中的数 据作为 ChunkedStream 写入。数据在传输之前将会由 SslHandler 加密。
//使用ChunkedStream传输文件内容 public class ChunkedWriteHandlerInitializer extends ChannelInitializer<Channel> { private final File file; private final SslContext sslContext; public ChunkedWriteHandlerInitializer(File file, SslContext sslContext) { this.file = file; this.sslContext = sslContext; } @Override protected void initChannel(Channel ch) throws Exception { ChannelPipeline pipeline = ch.pipeline(); //添加 ChunkedWriteHandler 以处理作为 ChunkedInput 传入的数据 pipeline.addLast(new SslHandler(sslContext.newEngine(ch.alloc()))); pipeline.addLast(new ChunkedWriteHandler()); // 一旦连接建立,WriteStreamHandler就开始写文件数据 pipeline.addLast(new WriteStreamHandler()); } public final class WriteStreamHandler extends ChannelInboundHandlerAdapter { // 当连接建立时,channelActive()方法将使用ChunkedInput写文件数据 @Override public void channelActive(ChannelHandlerContext ctx) throws Exception { super.channelActive(ctx); ctx.writeAndFlush(new ChunkedStream(new FileInputStream(file))); } } }
序列化数据
JDK 提供了 ObjectOutputStream 和 ObjectInputStream,用于通过网络对 POJO 的 基本数据类型和图进行序列化和反序列化。该 API 并不复杂,而且可以被应用于任何实现了 java.io.Serializable 接口的对象。但是它的性能也不是非常高效的。
JDK序列化:
如果你的应用程序必须要和使用了ObjectOutputStream和ObjectInputStream的远 程节点交互,并且兼容性也是你最关心的,那么JDK序列化将是正确的选择。下表中列出了 Netty提供的用于和JDK进行互操作的序列化类。

使用JBoss Marshalling进行序列化:
如果你可以自由地使用外部依赖,那么JBoss Marshalling将是个理想的选择:它比JDK序列 化最多快 3 倍,而且也更加紧凑。在JBoss Marshalling官方网站主页 3上的概述中对它是这么定 义的:
"JBoss Marshalling 是一种可选的序列化 API,它修复了在 JDK 序列化 API 中所发现 的许多问题,同时保留了与 java.io.Serializable 及其相关类的兼容性,并添加 了几个新的可调优参数以及额外的特性,所有的这些都是可以通过工厂配置(如外部序 列化器、类/实例查找表、类解析以及对象替换等)实现可插拔的。"
Netty 通过下表所示的两组解码器/编码器对为 Boss Marshalling 提供了支持。
- 第一组兼容 只使用 JDK 序列化的远程节点。
- 第二组提供了最大的性能,适用于和使用 JBoss Marshalling 的 远程节点一起使用。

示例:使用 MarshallingDecoder 和 MarshallingEncoder。同 样,几乎只是适当地配置 ChannelPipeline 罢了。
public class MarshallingInitializer extends ChannelInitializer<Channel> { private final MarshallerProvider marshallerProvider; private final UnmarshallerProvider unmarshallerProvider; public MarshallingInitializer(MarshallerProvider marshallerProvider, UnmarshallerProvider unmarshallerProvider) { this.marshallerProvider = marshallerProvider; this.unmarshallerProvider = unmarshallerProvider; } @Override protected void initChannel(Channel ch) throws Exception { ChannelPipeline pipeline = ch.pipeline(); // 添加 MarshallingDecoder 以 将 ByteBuf 转换为 POJO pipeline.addLast(new MarshallingDecoder(unmarshallerProvider)); // 添加 MarshallingEncoder 以将 POJO 转换为 ByteBuf pipeline.addLast(new MarshallingEncoder(marshallerProvider)); // 添加 ObjectHandler, 以处理普通的实现了 Serializable 接口的 POJO pipeline.addLast(new ObjectHandler()); } public static final class ObjectHandler extends SimpleChannelInboundHandler<Serializable> { @Override protected void channelRead0(ChannelHandlerContext ctx, Serializable msg) throws Exception { //Do something } } }
通过Protocol Buffers序列化:
Netty序列化的最后一个解决方案是利用Protocol Buffers 1的编解码器,它是一种由Google公 司开发的、现在已经开源的数据交换格式。可以在https://github.com/google/protobuf找到源代码。
Protocol Buffers 以一种紧凑而高效的方式对结构化的数据进行编码以及解码。它具有许多的 编程语言绑定,使得它很适合跨语言的项目。下表展示了 Netty 为支持 protobuf 所提供的 ChannelHandler 实现。
示例:
<!-- https://mvnrepository.com/artifact/com.google.protobuf/protobuf-java --> <dependency> <groupId>com.google.protobuf</groupId> <artifactId>protobuf-java</artifactId> <version>3.11.4</version> </dependency>
public class ProtoBufIntializer extends ChannelInitializer<Channel> { private final MessageLite lite; public ProtoBufIntializer(MessageLite lite) { this.lite = lite; } @Override protected void initChannel(Channel ch) throws Exception { ChannelPipeline pipeline = ch.pipeline(); // 添加 ProtobufVarint32FrameDecoder 以分隔帧 pipeline.addLast(new ProtobufVarint32FrameDecoder()); //添加 ProtobufEncoder 以处理消息的编码 pipeline.addLast(new ProtobufEncoder()); // 添加 ProtobufDecoder 以解码消息 pipeline.addLast(new ProtobufDecoder(lite)); //添加 Object- Handler 以处 理解码消息 pipeline.addLast(new ObjectHandler()); } public static final class ObjectHandler extends SimpleChannelInboundHandler<Object> { @Override protected void channelRead0(ChannelHandlerContext ctx, Object msg) throws Exception { //Do something with the obect } } }
参考:
https://blog.csdn.net/cold___play/article/details/106799217
https://www.cnblogs.com/jmcui/p/9550119.html
全文参考:
https://blog.csdn.net/cold___play/article/details/106799217
https://www.cnblogs.com/jmcui/p/9550119.html
https://skyao.gitbooks.io/learning-netty/content/http/object/http_classes.html
https://blog.csdn.net/u013252773/article/details/21254257