学习了两天Python 3的urllib,想着自己爬点东西,就想到了日常用的翻译,选择了两款网页翻译,百度和有道,都看了看网页的结构,发现有道的挺有趣,就尝试着爬取有道翻译,期间也遇到了一些小问题,拿出来分享一下,下面是我爬取的过程。
本文参考https://blog.csdn.net/nunchakushuang/article/details/75294947,此文对于现在爬取有道翻译已经过时了,下面是本人新测试的代码
1、首先打开有道翻译,随便翻译点内容,查看请求头和回复体
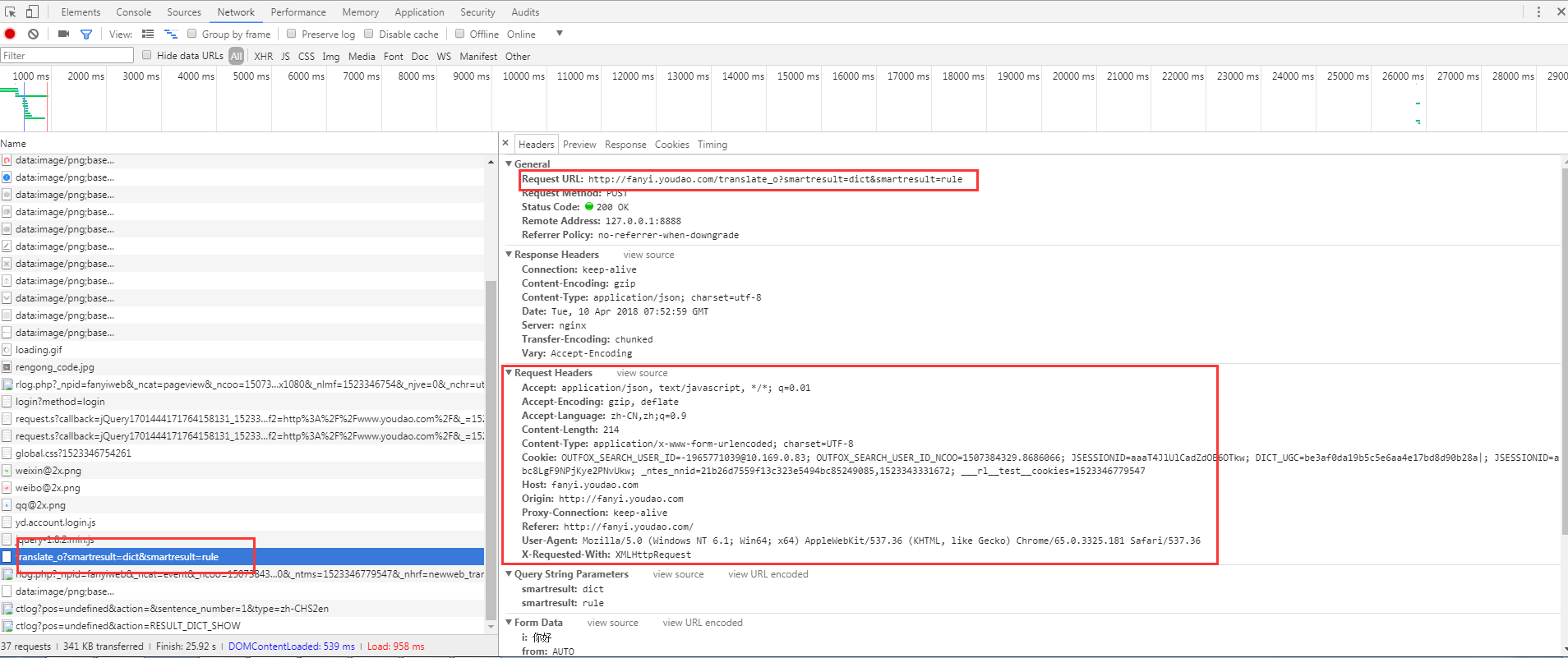
分析请求头可以发现:
请求url是http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule,
请求方式POST,
带有本地cookie的访问,
往下看请求头有一个“X-Requested-With”参数,可以认为是通过ajax局部刷新,向后台请求数据的,
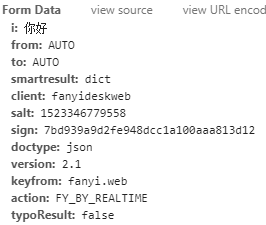
后面跟着POST请求的表单数据form data
有道翻译回复体是一个字典类型的数据
{"translateResult":[[{"tgt":"hello","src":"你好"}]],"errorCode":0,"type":"zh-CHS2en","smartResult":{"entries":["","hello ","hi "],"type":1}}
通过以上观察,我们可以伪造一个请求头和请求数据,来获取翻译结果:
#coding=utf-8 from urllib import request,parse import random import time import hashlib #可以是user-Agent列表,也可以是代理列表 ua_list = [ "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36", "Mozilla/5.0(compatible;MSIE9.0;WindowsNT6.1;Trident/5.0", "Opera/9.80(Macintosh;IntelMacOSX10.6.8;U;en)Presto/2.8.131Version/11.11", "Mozilla/4.0(compatible;MSIE7.0;WindowsNT5.1;TencentTraveler4.0)", "Mozilla/4.0(compatible;MSIE7.0;WindowsNT5.1;Trident/4.0;SE2.XMetaSr1.0;SE2.XMetaSr1.0;.NETCLR2.0.50727;SE2.XMetaSr1.0)", ] #在user-agent列表里随机选择一个user-agent user_agent = random.choice(ua_list) url = "http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule" key = input("请输入需要翻译的文字:") form_data = {"i":key, "from":"AUTO", "to":"AUTO", "smartresult":"dict", "client": "fanyideskweb", "salt": "1523346779558", "sign": "7bd939a9d2fe948dcc1a100aaa813d12", "doctype":"json", "version":"2.1", "keyfrom":"fanyi.web", "action":"FY_BY_REALTIME", "typoResul":"False" } data = parse.urlencode(form_data).encode('utf-8') requests = request.Request(url, data=data, method="POST") requests.add_header("User-Agent",user_agent) response = request.urlopen(requests) print(response.read().decode('utf-8'))
执行后发现,不管怎样,返回结果都是"{"errorCode": 50}",然后通过学习https://blog.csdn.net/nunchakushuang/article/details/75294947此文的思想分析方式,分析出了有道翻译现有的反爬虫机制,已经不单单是靠salt和sign来确定客户端是人在访问还是程序在访问,现有的有道反爬机制是通过请求头带有的参数来决定的,包括“X-Requested-With”、“Cookie”,还有salt和sign来决定,我们需要构造完整的请求头去爬取信息,否则缺少任意一个都会返回错误代码,下面是完整的构造代码。
#coding=utf-8 from urllib import request,parse import random import time import hashlib #可以是user-Agent列表,也可以是代理列表 ua_list = [ "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36", "Mozilla/5.0(compatible;MSIE9.0;WindowsNT6.1;Trident/5.0", "Opera/9.80(Macintosh;IntelMacOSX10.6.8;U;en)Presto/2.8.131Version/11.11", "Mozilla/4.0(compatible;MSIE7.0;WindowsNT5.1;TencentTraveler4.0)", "Mozilla/4.0(compatible;MSIE7.0;WindowsNT5.1;Trident/4.0;SE2.XMetaSr1.0;SE2.XMetaSr1.0;.NETCLR2.0.50727;SE2.XMetaSr1.0)", ] #在user-agent列表里随机选择一个user-agent user_agent = random.choice(ua_list) url = "http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule" key = input("请输入需要翻译的文字:") S = 'fanyideskweb' n = key r = str(int(time.time()*1000) + random.randint(1,10)) D = "ebSeFb%=XZ%T[KZ)c(sy!" o = hashlib.md5((S+n+r+D).encode('utf-8')).hexdigest() form_data = {"i":key, "from":"AUTO", "to":"AUTO", "smartresult":"dict", "client": S, "salt": r, "sign": o, "doctype":"json", "version":"2.1", "keyfrom":"fanyi.web", "action":"FY_BY_REALTIME", "typoResul":"False" } data = parse.urlencode(form_data).encode('utf-8') requests = request.Request(url, data=data, method="POST") requests.add_header("Host", "fanyi.youdao.com") requests.add_header("Connection", "keep-alive") requests.add_header("Origin", "http://fanyi.youdao.com") requests.add_header("User-Agent",user_agent) requests.add_header("X-Requested-With", "XMLHttpRequest") requests.add_header("Referer", "http://fanyi.youdao.com/") requests.add_header("Cookie", "OUTFOX_SEARCH_USER_ID=-1965771039@10.169.0.83; OUTFOX_SEARCH_USER_ID_NCOO=1507384329.8686066; JSESSIONID=aaaT4JlUlCadZdOE6OTkw; ___rl__test__cookies=1523342915528") response = request.urlopen(requests) print(response.read().decode('utf-8'))
思想:反爬在不断进步,我们也需要不断去分析,乐此不疲,把技术运用在对的地方,是一个很好的习惯,别拿别人的东西,去自己谋利,那就有违道德了!