前言
本篇文章将会介绍一个NodeJS社区中的ORM:Prisma。我接触它的时间不算长,但已经对它的未来发展充满信心。这篇文章其实三个月以前就写了一部分,所以文中会出现“如果你觉得它不错,不如考虑基于Prisma来完成你的毕设”这样的话。
在刚开始写的时候,bven爷的毕设一行都还没动,而到了我今天发的时候,他已经是优秀毕业生了...
同时,原本准备一篇搞定所有内容,但是觉得这种教程类的文章如果写的这么长,很难让人有读完的兴致。所以就拆成了两部分:
- 第一部分主要是铺垫,介绍目前NodeJS社区比较主流的ORM与Query Builder,以及Prisma的简单使用,这一部分主要是为接触ORM较少的同学做一个基础知识的铺垫。
- 第二部分包括Prisma的花式进阶使用,包括多表级联、多数据库协作以及与GraphQL的实战,最后会展开来聊一聊Prisma的未来。
文章的大致顺序如下:
- NodeJS社区中的老牌、传统ORM
- 传统ORM的Data Mapper 与 Active Record模式
- Query Builder
- Prisma的基础环境配置
- Hello Prisma
- 从单表CRUD开始
- 多表、多数据库实战
- Prisma与GraphQL:全链路类型安全
- Prisma与一体化框架
NodeJS社区中的ORM
经常写Node应用的同学通常免不了要和ORM打交道,毕竟写原生SQL对于大部分前端同学来说真的是一种折磨。ORM的便利性使得很多情况下我们能直观而方便的和数据库打交道(虽然的确有些情况下ORM搞不定),用我们熟悉的JavaScript来花式操作数据库。 NodeJS社区中主流的ORM主要有这么几个,它们都有各自的一些特色:
- Sequelize,比较老牌的一款ORM,缺点是TS支持不太好,但是社区有Sequelize-TypeScript。
Sequelize定义表结构的方式是这样的: - ``
typescriptconst { Sequelize, Model, DataTypes } = require('sequelize');const sequelize = new Sequelize('sqlite::memory:');class User extends Model {}User.init({username: DataTypes.STRING,birthday: DataTypes.DATE}, { sequelize, modelName: 'user' });(async () => {await sequelize.sync();const jane = await User.create({username: 'janedoe',birthday: new Date(1980, 6, 20)});console.log(jane.toJSON());})();
```
(我是觉得不那么符合直觉,所以我只在入门时期简单使用过) - TypeORM,NodeJS社区star最多的一个ORM。也确实很好用,在我周围的同学里备受好评,同时也是我自己用的最多的一个ORM。亮点在基于装饰器语法声明表结构、事务、级联等,以及很棒的TS支持。
TypeORM声明表结构是这样的: - `
typescriptimport { Entity, PrimaryGeneratedColumn, Column } from "typeorm";@Entity()export class User {@PrimaryGeneratedColumn()id: number;@Column()firstName: string;@Column()lastName: string;@Column()age: number;}
比起Sequelize来要直观的多,而且由于通过类属性的方式来定义数据库字段,可以很好的兼容Mixin以及其他基于类属性的工具库,如TypeGraphQL。 - MikroORM,比较新的一个ORM,同样大量基于装饰器语法,亮点在于自动处理所有事务以及表实体会在全局保持单例模式,暂时还没深入使用过过。
MikroORM定义表结构方式是这样的: - `
typescript@Entity()export class Book extends BaseEntity {@Property()title!: string;@ManyToOne()author!: Author;@ManyToOne()publisher?: IdentifiedReference<Publisher>;@ManyToMany({ fixedOrder: true })tags = new Collection<BookTag>(this);} - Mongoose、Typegoose,MongoDB专用的ORM,这里简单放一下TypeGoose的使用示例:
- `
typescriptimport { prop, getModelForClass } from '@typegoose/typegoose';import * as mongoose from 'mongoose';class User {@prop()public name?: string;@prop({ type: () => [String] })public jobs?: string[];}const UserModel = getModelForClass(User);(async () => {await mongoose.connect('mongodb://localhost:27017/', { useNewUrlParser: true, useUnifiedTopology: true, dbName: 'test' });const { _id: id } = await UserModel.create({ name: 'JohnDoe', jobs: ['Cleaner'] } as User);const user = await UserModel.findById(id).exec();console.log(user);})(); - Bookshelf,一个相对简单一些但也五脏俱全的ORM,基于Knex(Strapi底层的Query Builder,后面会简单介绍)。它的使用方式大概是这样的:
- `
typescriptconst knex = require('knex')({client: 'mysql',connection: process.env.MYSQL_DATABASE_CONNECTION})// bookshelf 基于 knex,所以需要实例化knex然后传入const bookshelf = require('bookshelf')(knex)const User = bookshelf.model('User', {tableName: 'users',posts() {return this.hasMany(Posts)}})const Post = bookshelf.model('Post', {tableName: 'posts',tags() {return this.belongsToMany(Tag)}})const Tag = bookshelf.model('Tag', {tableName: 'tags'})new User({id: 1}).fetch({withRelated: ['posts.tags']}).then((user) => {console.log(user.related('posts').toJSON())}).catch((error) => {console.error(error)})
另外,一个比较独特的地方是bookshelf支持了插件机制,其他ORM通常通过hook或者subscriber的方式实现类似的功能,如密码存入时进行一次加密、TPS计算、等。
ORM的Data Mapper与Actice Record模式
如果你去看了上面列举的ORM文档,你会发现MikroORM的简介中包含这么一句话:TypeScript ORM for Node.js based on Data Mapper,而TypeORM的简介中则是TypeORM supports both Active Record and Data Mapper patterns。
先来一个问题,使用ORM的过程中,你是否了解过 Data Mapper 与 Active Record 这两种模式的区别?
先来看看TypeORM中分别是如何使用这两种模式的:
Active Record:
import { BaseEntity, Entity, PrimaryGeneratedColumn, Column } from "typeorm";
@Entity()
export class User extends BaseEntity {
@PrimaryGeneratedColumn()
id: number;
@Column()
name: string;
@Column()
isActive: boolean;
}
const user = new User();
user.name = "不渡";
user.isActive = true;
await user.save();
const newUsers = await User.find({ isActive: true });
TypeORM中,Active Record模式下需要让实体类继承BaseEntity类,这样实体类上就具有了各种方法,如save remove find方法等。Active Record模式最早由 Martin Fowler 在 企业级应用架构模式 一书中命名,这一模式使得对象上拥有了相关的CRUD方法。在RoR中就使用了这一模式来作为MVC中的M,即数据驱动层。如果你对RoR中的Active Record有兴趣,可以阅读 全面理解Active Record(我不会Ruby,因此就不做介绍了)。
Data Mapper:
import { Entity, PrimaryGeneratedColumn, Column } from "typeorm";
@Entity()
export class User {
@PrimaryGeneratedColumn()
id: number;
@Column()
name: string;
@Column()
isActive: boolean;
}
const userRepository = connection.getRepository(User);
const user = new User();
user.name = "不渡";
user.isActive = true;
await userRepository.save(user);
await userRepository.remove(user);
const newUsers = await userRepository.find({ isActive: true });
可以看到在Data Mapper模式中,实体类不再能够自己进行数据库操作,而是需要先获取到一个对应到表的“仓库”,然后再调用这个“仓库”上的方法。
这一模式同样由Martin Fowler最初命名,Data Mapper更像是一层拦在操作者与实际数据之间的访问层,就如上面例子中先获取具有访问权限(即相应方法)的对象,再进行数据的操作。
对这两个模式进行比较,很容易发现Active Record模式要简单的多,而Data Mapper模式则更加严谨。那么何时使用这两种模式就很清楚了,如果你在开发比较简单的应用,直接使用Active Record模式就好了,因为这确实会减少很多代码。但是如果你在开发规模较大的应用,使用Data Mapper模式则能够帮助你更好的维护代码(实体类不再具有访问数据库权限了,只能通过统一的接口(getRepository getManager等)),一个例子是在Nest、Midway这两个IoC风格的Node框架中,均使用Data Mapper模式注入Repository实例,然后再进行操作。
最后,NodeJS中使用Data Mapper的ORM主要包括Bookshelf、MikroORM、objection.js以及本文主角Prisma等。
Query Builder
实际上除了ORM与原生SQL以外,还有一种常用的数据库交互方式:Query Builder(以下简称QB)。
QB和ORM其实我个人觉得既有相同之处又有不同之处,但是挺容易搞混,比如 MQuery (MongoDB的一个Query Builder)的方法是这样的:
mquery().find(match, function (err, docs) {
assert(Array.isArray(docs));
})
mquery().findOne(match, function (err, doc) {
if (doc) {
// the document may not be found
console.log(doc);
}
})
mquery().update(match, updateDocument, options, function (err, result){})
是不是看起来和ORM很像?但我们再看看其他的场景:
mquery({ name: /^match/ })
.collection(coll)
.setOptions({ multi: true })
.update({ $addToSet: { arr: 4 }}, callback)
在ORM中,通常不会存在这样的多个方法链式调用,而是通过单个方法+多个参数的方式来操作,这也是Query Builder和ORM的一个重要差异。再来看看TypeORM的Query Builder模式:
import { getConnection } from "typeorm";
const user = await getConnection()
.createQueryBuilder()
.select("user")
.from(User, "user")
.where("user.id = :id", { id: 1 })
.getOne();
以上的操作其实就相当于userRepo.find({ id: 1 }),你可能会觉得QB的写法过于繁琐,但实际上这种模式要灵活的多,和SQL语句的距离也要近的多(你可以理解为每一个链式方法调用都会对最终生成的SQL语句进行一次操作)。
同时在部分情境(如多级级联下)中,Query Builder反而是代码更简洁的那一方,如:
const selectQueryBuilder = this.executorRepository
.createQueryBuilder("executor")
.leftJoinAndSelect("executor.tasks", "tasks")
.leftJoinAndSelect("executor.relatedRecord", "records")
.leftJoinAndSelect("records.recordTask", "recordTask")
.leftJoinAndSelect("records.recordAccount", "recordAccount")
.leftJoinAndSelect("records.recordSubstance", "recordSubstance")
.leftJoinAndSelect("tasks.taskSubstance", "substance");
以上代码构建了一个包含多张表的级联关系的Query Builder。
级联关系如下:
- Executor
- tasks -> Task
- relatedRecord -> Record
- Task
- substances -> Substance
- Record
- recordTask -> Task
- recordAccount -> Account
- recordSubstance -> Substance
再看一个比较主流的Query Builder knex,我是在尝鲜strapi的过程中发现的,strapi底层依赖于knex去进行数据库交互以及连接池相关的功能,knex的使用大概是这样的:
const knex = require('knex')({
client: 'sqlite3',
connection: {
filename: './data.db',
},
});
try {
await knex.schema
.createTable('users', table => {
table.increments('id');
table.string('user_name');
})
.createTable('accounts', table => {
table.increments('id');
table.string('account_name');
table
.integer('user_id')
.unsigned()
.references('users.id');
})
const insertedRows = await knex('users').insert({ user_name: 'Tim' })
await knex('accounts').insert({ account_name: 'knex', user_id: insertedRows[0] })
const selectedRows = await knex('users')
.join('accounts', 'users.id', 'accounts.user_id')
.select('users.user_name as user', 'accounts.account_name as account')
const enrichedRows = selectedRows.map(row => ({ ...row, active: true }))
} catch(e) {
console.error(e);
};
可以看到knex的链式操作更进了一步,甚至可以链式创建多张数据库表。
Prisma
接下来就到了我们本篇文章的主角:Prisma 。Prisma对自己的定义仍然是NodeJS的ORM,但个人感觉它比普通意义上的ORM要强大得多。这里放一张官方的图,来大致了解下Prisma和ORM、SQL、Query Builder的能力比较:
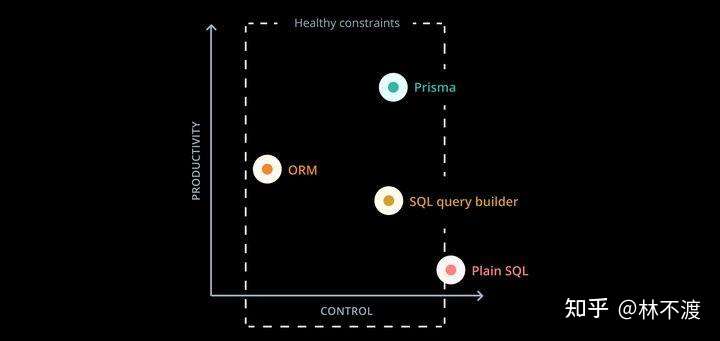
你也可以阅读方方老师翻译的这篇Why Prisma?来了解更多。
独特的Schema定义方式、比TypeORM更加严谨全面的TS类型定义(尤其是在级联关系中)、更容易上手和更贴近原生SQL的各种操作符等,很容易让初次接触的人欲罢不能(别说了,就是我)。
简单的介绍下这些特点:
- Schema定义,我们前面看到的ORM都是使用JS/TS文件来定义数据库表结构的,而Prisma不同,它使用
.prisma后缀的文件来书写独特的Prisma Schema,然后基于schema生成表结构,VS Code有prisma官方提供的高亮、语法检查插件,所以不用担心使用负担。
同时,这也就意味着围绕Prisma Schema会产生一批generator功能的生态,如typegraphql-prisma就能够基于Prisma Schema生成TypeGraphQL的Class定义,甚至还有CRUD的基本Resolver,类似的还有palJS提供的基于Prisma Schema生成Nexus的类型定义与CRUD方法(所以说GraphQL和Prisma这种都是SDL-First的工具真的是天作之合)。
TypeGraphQL、Resolver属于GraphQL相关的工具/概念,如果未曾了解过也不要紧。
一个简单的schema.prisma可能是这样的:
datasource db { provider = "sqlite" url = env("SINGLE_MODEL_DATABASE_URL") } generator client { provider = "prisma-client-js" output = "./client" } model Todo { id Int @id @default(autoincrement()) title String content String? finished Boolean @default(false) createdAt DateTime @default(now()) updatedAt DateTime @updatedAt }
是不是感觉即使你没用过,但还是挺好看懂。 - TS类型定义,可以说Prisma的类型定义是全覆盖的,查询参数、操作符参数、级联参数、返回结果等等,比TypeORM的都更加完善。
- 更全面的操作符,如对字符串的查询,Prisma中甚至提供了contains、startsWith、endsWith这种细粒度的操作符供过滤使用(而TypeORM中只能使用ILike这种方法来全量匹配)。(这些操作符的具体作用我们会在后面讲到)
在这一部分的最后,我们来简单的介绍下Prisma的使用流程,在正文中,我们会一步步详细介绍Prisma的使用,包括单表、多表级联以及Prisma与GraphQL的奇妙化学反应。
环境配置在下一节,这里我们只是先感受一下使用方式
- 首先,创建一个名为
prisma的文件夹,在内部创建一个schema.prisma文件
如果你使用的是VS Code,可以安装Prisma扩展来获得.prisma的语法高亮 - 在schema中定义你的数据库类型、路径以及你的数据库表结构,示例如下:
model Todo { id Int @id @default(autoincrement()) title String } - 运行
prisma generate命令,prisma将为你生成Prisma Client,内部结构是这样的:
- 在你的文件中导入
Prisma Client即可使用:
import { PrismaClient } from "./prisma/client";
const prisma = new PrismaClient();
async function createTodo(title: string, content?: string) {
const res = await prisma.todo.create({
data: {
title,
content,
},
});
return res;
}
每张表都会被存放在prisma.__YOUR_MODEL__的命名空间下。
如果看完简短的介绍你已经感觉这玩意有点好玩了,那么在跟着本文完成实践后,你可能也会默默把手上的项目迁移到Prisma(毕设也可以安排上)~
上手Prisma
你可以在 Prisma-Article-Example 找到完整的示例,以下的例子我们会从一个空文件夹开始。
项目初始化
- 创建一个空文件夹,执行
npm init -y
yarn、pnpm同理 - 全局安装
@prisma/cli:npm install prisma -g@prisma/cli包已被更名为prisma
全局安装@prisma/cli是为了后面执行相关命令时方便些~ - 安装必要的依赖:
npm install @prisma/client sqlite3 prisma -S
npm install typescript @types/node nodemon ts-node -D
安装prisma到文件夹时会根据你的操作系统下载对应的Query Engine:

- 执行
prisma version,确定安装成功。
- 执行
prisma init,初始化一个Prisma项目(这个命令的侵入性非常低,只会生成prisma文件夹和.env文件,如果.env文件已经存在,则会将需要的环境变量追加到已存在的文件)。
- 查看
.env文件
# Environment variables declared in this file are automatically made available to Prisma. # See the documentation for more detail: https://pris.ly/d/prisma-schema#using-environment-variables # Prisma supports the native connection string format for PostgreSQL, MySQL and SQLite. # See the documentation for all the connection string options: https://pris.ly/d/connection-strings DATABASE_URL="postgresql://johndoe:randompassword@localhost:5432/mydb?schema=public"
你会发现这里的数据库默认使用的是postgresql,在本文中为了降低学习成本,我们全部使用SQLite作为数据库,因此需要将变量值修改为file:../demo.sqlite
如果你此前没有接触过SQLite,可以理解为这是一个能被当作数据库读写的文件(.sqlite后缀),因此使用起来非常容易,也正是因为它是文件,所以需要将DATABASE_URL这一变量改为file://协议。
同样的,在Prisma Schema中我们也需要修改数据库类型为sqlite:
// This is your Prisma schema file, // learn more about it in the docs: https://pris.ly/d/prisma-schema datasource db { provider = "sqlite" url = env("DATABASE_URL") } generator client { provider = "prisma-client-js" }
创建数据库
在上面的Prisma Schema中,我们只定义了datasource和generator,它们分别负责定义使用的数据库配置和客户端生成的配置,举例来说,默认情况下prisma生成的client会被放置在node_modules下,导入时的路径也是import { PrismaClient } from "@prisma/client",但你可以通过client.output命令更改生成的client位置。
generator client {
provider = "prisma-client-js"
output = "./client"
}这一命令会使得client被生成到prisma文件夹下,如:

将client生成到对应的prisma文件夹下这一方式使得在monorepo(或者只是多个文件夹的情况)下,每个项目可以方便的使用不同配置的schema生成的client。
我们在Prisma Schema中新增数据库表结构的定义:
datasource db {
provider = "sqlite"
url = env("SINGLE_MODEL_DATABASE_URL")
}
generator client {
provider = "prisma-client-js"
output = "./client"
}
model Todo {
id Int @id @default(autoincrement())
title String
content String?
finished Boolean @default(false)
createdAt DateTime @default(now())
updatedAt DateTime @updatedAt
}简单解释下相关语法:
- Int、String等这一类标量会被自动基于数据库类型映射到对应的数据类型。标量类型后的
?意味着这一字段是可选的。 @id意为标识此字段为主键,@default()意为默认值,autoincrement与now为prisma内置的函数,分别代表自增主键与字段写入时的时间戳,类似的内置函数还有uuid、cuid等。
客户端生成与使用
现在你可以生成客户端了,执行prisma generate:
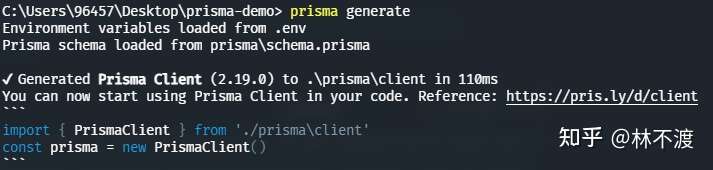
还没完,我们的数据库文件(即sqlite文件)还没创建出来,执行prisma db push
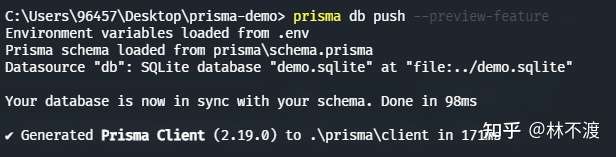
这个命令也会执行一次prisma generate,你可以使用--skip-generate跳过这里的client生成。
现在根目录下就出现了demo.sqlite文件。
在根目录下创建index.ts:
// index.ts
import { PrismaClient } from "./prisma/client";
const prisma = new PrismaClient();
async function main() {
console.log("Prisma!");
}
main();
从使用方式你也可以看出来PrismaClient实际上是一个类,所以你可以继承这个类来进行很多扩展操作,在后面我们会提到。
在开始使用前,为了后续学习的简洁,我们使用nodemon + ts-node,来帮助我们在index.ts发生变化时自动重新执行。
{
"name": "Prisma2-Explore",
"restartable": "r",
"delay": "500",
"ignore": [
".git",
"node_modules/**",
"/prisma/*",
],
"verbose": true,
"execMap": {
"": "node",
"js": "node --harmony",
"ts": "ts-node "
},
"watch": ["./**/*.ts"],
}
并将启动脚本添加到package.json:
{
"scripts": {
"start": "nodemon index.ts"
}
}
执行npm start:
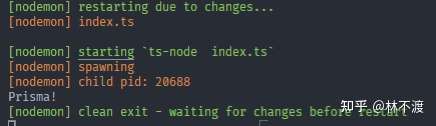
Prisma单表初体验
环境配置
接下来就到了正式使用环节,上面的代码只是一个简单的开发工作流示范,本文接下来的部分不会使用到(但是你可以基于这个工作流自己进一步的探索Prisma)。
在接下来,你所需要的相关环境我已经准备完毕,见Prisma-Article-Example,clone仓库到本地,运行配置完毕的npm scripts即可。在这里简单的介绍下项目中的npm scripts,如果在阅读完毕本部分内容后觉得意犹未尽,可以使用这些scripts直接运行其他部分如多表、GraphQL相关的示例。简单介绍部分scripts:
yarn flow:从零开始完整的执行 生成客户端 - 构建项目 - 执行构建产物 的流程。yarn dev:**:在开发模式下运行项目,文件变化后重启进程。yarn generate:**:为项目生成Prisma Client。- 使用
yarn gen:client来为所有项目生成Prisma Client。
yarn setup:**:为构建完毕的项目生成SQLite文件。yarn invoke:**:执行构建后的JS文件。- 使用
yarn setup执行所有构建后的JS文件。
本部分(Prisma单表示例)的代码见 single-model,相关的命令包括:
$ yarn dev:single
$ yarn generate:single
$ yarn setup:single
$ yarn invoke:single
在开始下文的CRUD代码讲解时,最好首先运行起来项目。首先执行yarn generate:single,生成Prisma Client,然后再yarn dev:single,进入开发模式,如下:
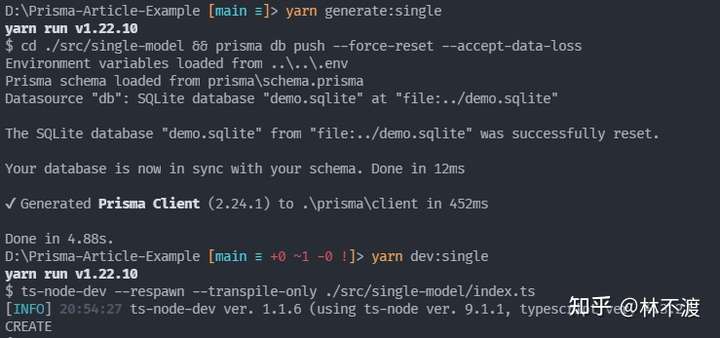
我直接一顿CRUD
根据前面已经提到的使用方式,首先引入Prisma Client并实例化:
import { PrismaClient } from "./prisma/client";
const prisma = new PrismaClient();
Prisma将你的表类(Table Class)挂载在prisma.MODEL下,MODEL值直接来自于schema.prisma中的model名称,如本例是Todo,那么就可以在prisma.todo下获取到相关的操作方法:
因此,简单的CRUD完全可以直接照着API来,
创建:
async function createTodo(title: string, content?: string) {
const res = await prisma.todo.create({
data: {
title,
content: content ?? null,
},
});
return res;
}
create方法接受两个参数:
- data,即你要用来创建新数据的属性,类型定义由你的schema决定,如这里content在schema中是可选的字符串(
String?),其类型就为string|null,所以需要使用??语法来照顾参数未传入的情况。 - select,决定create方法返回的对象中的字段,如果你指定
select.id为false,那么create方法的返回值对象中就不会包含id这一属性。这一参数在大部分prisma方法中都包含。
读取:
async function getTodoById(id: number) {
const res = await prisma.todo.findUnique({
where: { id },
});
return res;
}
findUnique方法类似于TypeORM中的findOne方法,都是基于主键查询,在这里将查询条件传入给where参数。
读取所有:
async function getTodos(status?: boolean) {
const res = await prisma.todo.findMany({
orderBy: [{ id: "desc" }],
where: status
? {
finished: status,
}
: {},
select: {
id: true,
title: true,
content: true,
createdAt: true,
},
});
return res;
}
在这里我们额外传入了orderBy方法来对返回的查询结果进行排序,既然有了排序,当然也少不了分页。你还可以传入cursor、skip、take等参数来完成分页操作。
cursor-based 与 offset-based 实际上是两种不同的分页方式。
类似的,更新操作:
async function updateTodo(
id: number,
title?: string,
content?: string,
finished?: boolean
) {
const origin = await prisma.todo.findUnique({
where: { id },
});
if (!origin) {
throw new Error("Item Inexist!");
}
const res = await prisma.todo.update({
where: {
id,
},
data: {
title: title ?? origin.title,
content: content ?? origin.content,
finished: finished ?? origin.finished,
},
});
return res;
}
这里执行的是在未查询到主键对应的数据实体时抛出错误,你也可以使用upsert方法来在数据实体不存在时执行创建。
批量更新:
async function convertStatus(status: boolean) {
const res = await prisma.todo.updateMany({
where: {
finished: !status,
},
data: {
finished: {
set: status,
},
},
});
return res;
}
注意,这里我们使用set属性,来直接设置finished的值。这一方式和直接设置其为false是效果一致的,如果这里是个number类型,那么除了set以外,还可以使用increment、decrement、multiply以及divide方法。
最后是删除操作:
async function deleteTodo(id: number) {
const res = await prisma.todo.delete({
where: { id },
});
return res;
}
async function clear() {
const res = await prisma.todo.deleteMany();
return res;
}
你可以自由的在以上这些例子以外,借助良好的TS类型提示花式探索Prisma的API,也可以提前看看其它部分的例子来早一步感受Prisma的强大能力。
尾声 & 下篇预告
以上使用到的Prisma方法(如create)与操作符(如set)只是一小部分,目的只是为了让你大致感受下Prisma与其他传统ORM相比新奇的使用方式。在下篇中,我们将会介绍:
- Prisma多张数据表的级联关系处理
- 多个Prisma Client协作
- Prisma与其他ORM的协作
- 和上一项一样都属于
- Prisma + GraphQL 全流程实战
- Prisma的展望:工作原理、一体化框架
敬请期待~