使用 Pandas 进行数据探索
实验楼教程
pandas基于numpy的一种工具
- 使用类似SQL的方式对.csv,.tsv,.xlsx等格式的数据进行分析
- 树妖使用的数据结构是series和dataframe类
- series是一种类似于一维数组的对象,由一组数据(各种 NumPy 数据类型)及一组与之相关的数据标签(即索引)组成
- dataframe二维数据结构,即一张表格每列数据的类型相同(可以看成由series实例构成的字典)
import warnings
warnings.filterwarnings('ignore')
控制警告是否显示 使用warnings.filterwarnings来抑制第三方警告
read_csv():读取数据
head():查看5行数据
import numpy as np
import pandas as pd
import warnings
warnings.filterwarnings('ignore')
# 读取数据
df = pd.read_csv('https://labfile.oss.aliyuncs.com/courses/1283/telecom_churn.csv')
# 查看前5行数据
df.head()
# 查看一下该数据库的维度、特征名称和特征类型。
df.shape
# 打印列名
df.columns
# 输出dataframe的信息
df.info()
# 更改列的类型 astype()
df['Churn'] = df['Churn'].astype('int64')
# 显示数值特征(int64和float64)的基本统计学特性
df.describe()
# 通过 include 参数显式指定包含的数据类型,可以查看非数值特征的统计数据。
df.describe(include=['object', 'bool'])
# 查看类别(类型为 object )和布尔值(类型为 bool )特征
df['Churn'].value_counts()
# 排序
# 据某个变量的值(也就是列)排序
df.sort_values(by = 'Total day charge',ascending = False).head()
# 根据多个列的数值排列
df.sort_values(by=['Churn', 'Total day charge'],
ascending=[True, False]).head()
# 索引和获取数据
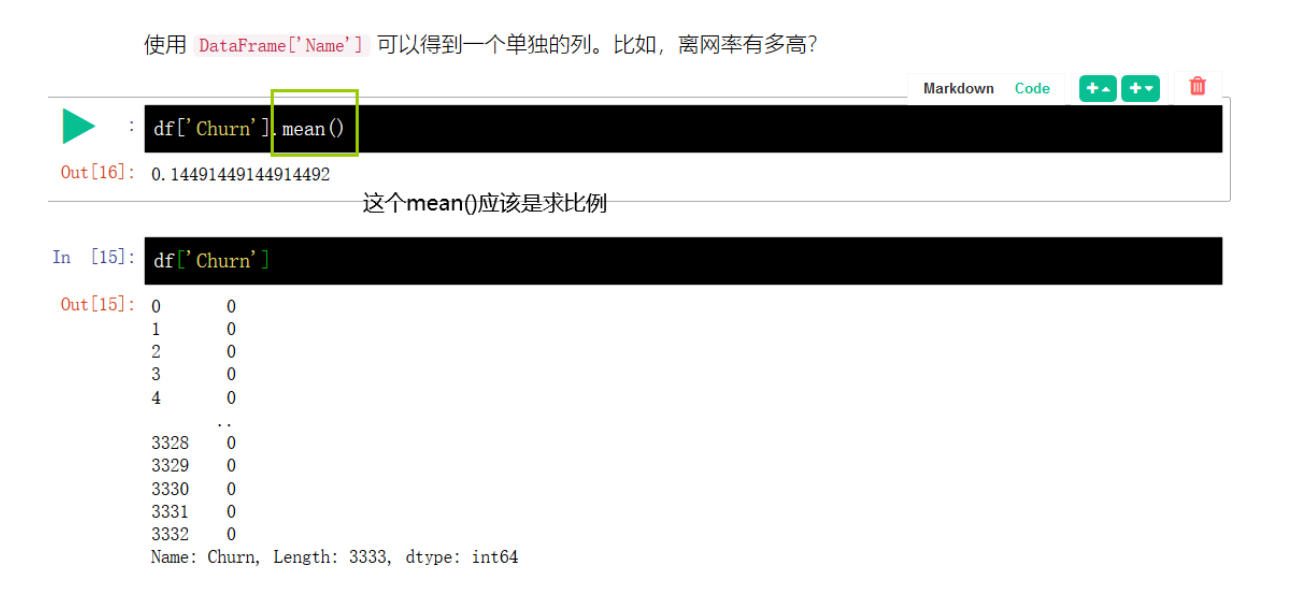
# 使用 DataFrame['Name'] 可以得到一个单独的列
df['Churn'].mean()
# 布尔值索引
df[df['Churn'] == 1].mean()
# DataFrame 可以通过列名、行名、行号进行索引。loc 方法为通过名称索引,iloc 方法为通过数字索引
df.loc[0:5, 'State':'Area code']
df.iloc[0:5, 0:3]
# 应用函数到单元格、列、行
# 通过apply()方法应用到函数max至每一列
df.apply(np.max)
# 替换一列中的值
d = {'No': False, 'Yes': True} # 字典
df['International plan'] = df['International plan'].map(d)
df.head()
# 或者使用replace()方法
df = df.replace({'Voice mail plan': d})
df.head()
# 分组
columns_to_show = ['Total day minutes', 'Total eve minutes',
'Total night minutes']
df.groupby(['Churn'])[columns_to_show].describe(percentiles=[])











汇总表
Markdown Code
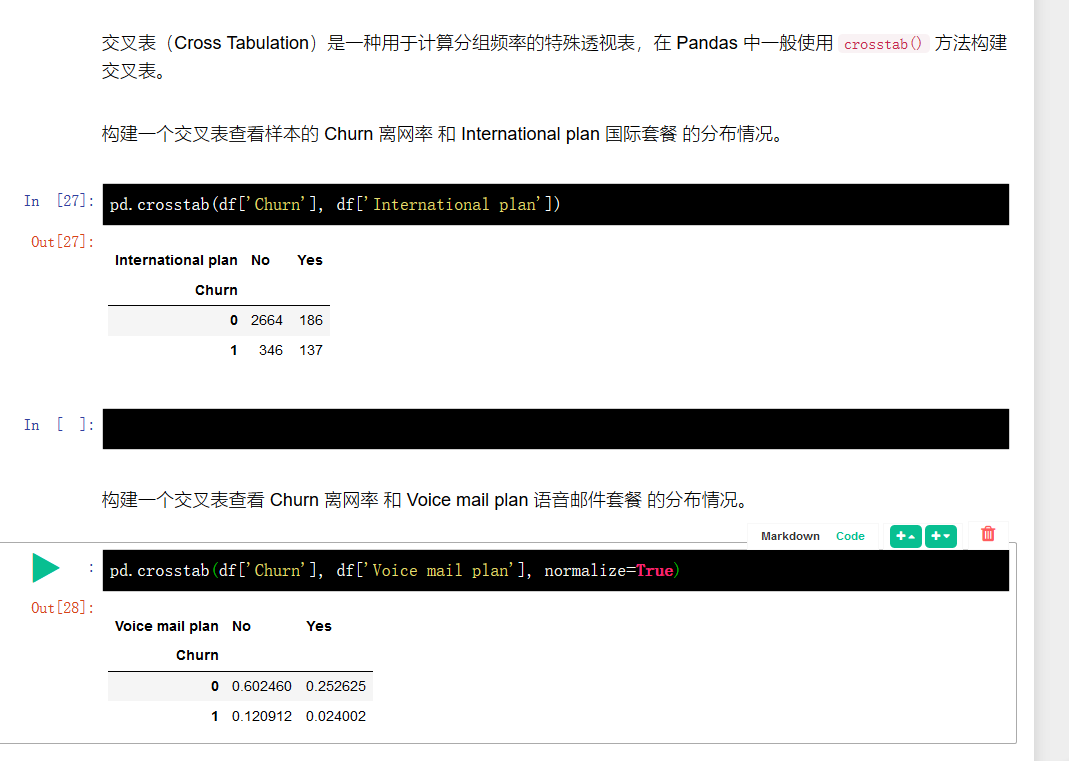
Pandas 中的透视表定义如下:
透视表(Pivot Table)是电子表格程序和其他数据探索软件中一种常见的数据汇总工具。它根据一个或多个键对数据进行聚合,并根据行和列上的分组将数据分配到各个矩形区域中。
通过 pivot_table() 方法可以建立透视表,其参数如下:
values 表示需要计算的统计数据的变量列表
index 表示分组数据的变量列表
aggfunc 表示需要计算哪些统计数据,例如,总和、均值、最大值、最小值等。


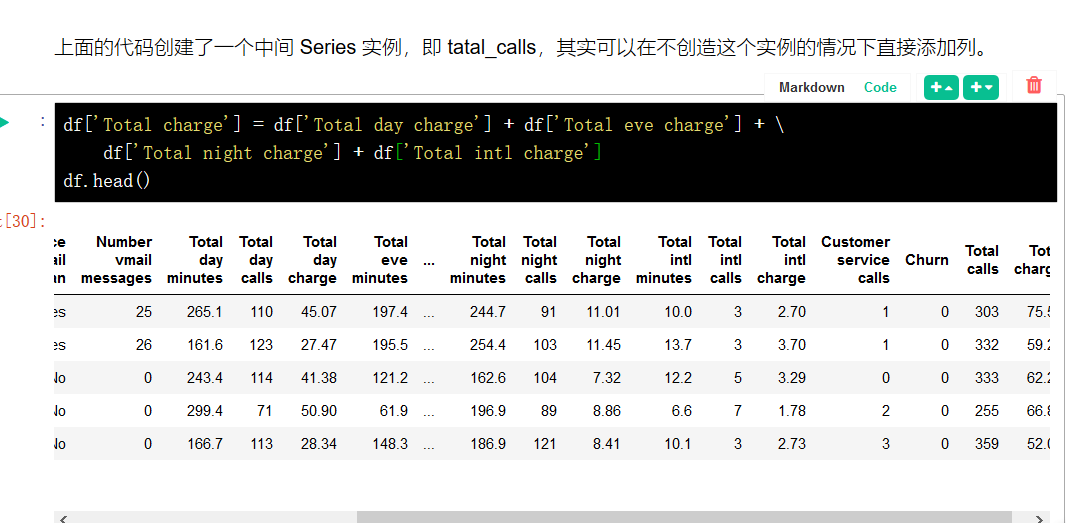

将相应的索引 ['Total charge', 'Total calls'] 和 axis 参数(1 表示删除列,0 表示删除行,默认值为 0)传给 drop。
inplace 参数表示是否修改原始 DataFrame (False 表示不修改现有 DataFrame,返回一个新 DataFrame,True 表示修改当前 DataFrame)。