
散列表介绍:
数组和链表都可以是有序的(即存储顺序与取出顺序一致),但这样是有代价的,需要遍历才可以寻找某一特定元素;
而还有另外的一些存储结构:不在意元素的顺序,能够快速的查找元素的数据
其中就有一种非常常见的:散列表
2.1散列表工作原理
散列表为每个对象计算出一个整数,称为散列码。根据这些计算出来的整数(散列码)保存在对应的位置上!
在Java中,散列表用的是链表数组实现的,每个列表称之为桶。
一个桶上可能会遇到被占用的情况(hashCode散列码相同,就存储在同一个位置上),这种情况是无法避免的,这种现象称之为:散列冲突
- 此时需要用该对象与桶上的对象进行比较,看看该对象是否存在桶子上了~如果存在,就不添加了,如果不存在则添加到桶子上
- 当然了,如果hashcode函数设计得足够好,桶的数目也足够,这种比较是很少的~
- 在JDK1.8中,桶满时会从链表变成平衡二叉树
如果散列表太满,是需要对散列表再散列,创建一个桶数更多的散列表,并将原有的元素插入到新表中,丢弃原来的表~
- 装填因子(load factor)决定了何时对散列表再散列~
- 装填因子默认为0.75,如果表中超过了75%的位置已经填入了元素,那么这个表就会用双倍的桶数自动进行再散列
平衡树:满足平衡条件的树;
AVL树,带有平衡条件的二叉排序树(平衡条件:每个节点的左子树和右子树的高度最多差 1);
红黑树:
在2-3树的理论基础上发明了红黑树(2-3-4树也是同样的道理,只是2-3树是最简单的一种情况,所以我就不说2-3-4树了)。
红黑树是对2-3查找树的改进,它能用一种统一的方式完成所有变换。
红黑树用的是也是两种方式来替代2-3树不断的节点交换操作:
- 旋转:顺时针旋转和逆时针旋转
- 反色:交换红黑的颜色
- 这个两个实现比2-3树交换的节点(合并,分解)要方便一些
红黑树为了保持平衡,还有制定一些约束,遵守这些约束的才能叫做红黑树:
- 红黑树是二叉搜索树。
- 根节点是黑色。
- 每个叶子节点都是黑色的空节点(NIL节点)。
- 每个红色节点的两个子节点都是黑色。(从每个叶子到根的所有路径上不能有两个连续的红色节点)
- 从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点(每一条树链上的黑色节点数量(称之为“黑高”)必须相等)。
-
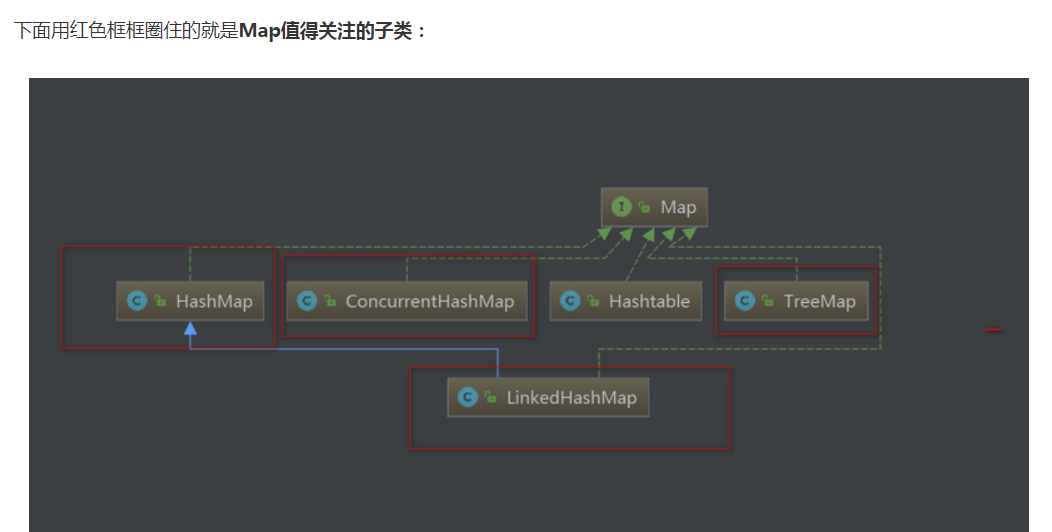
HashMap剖析
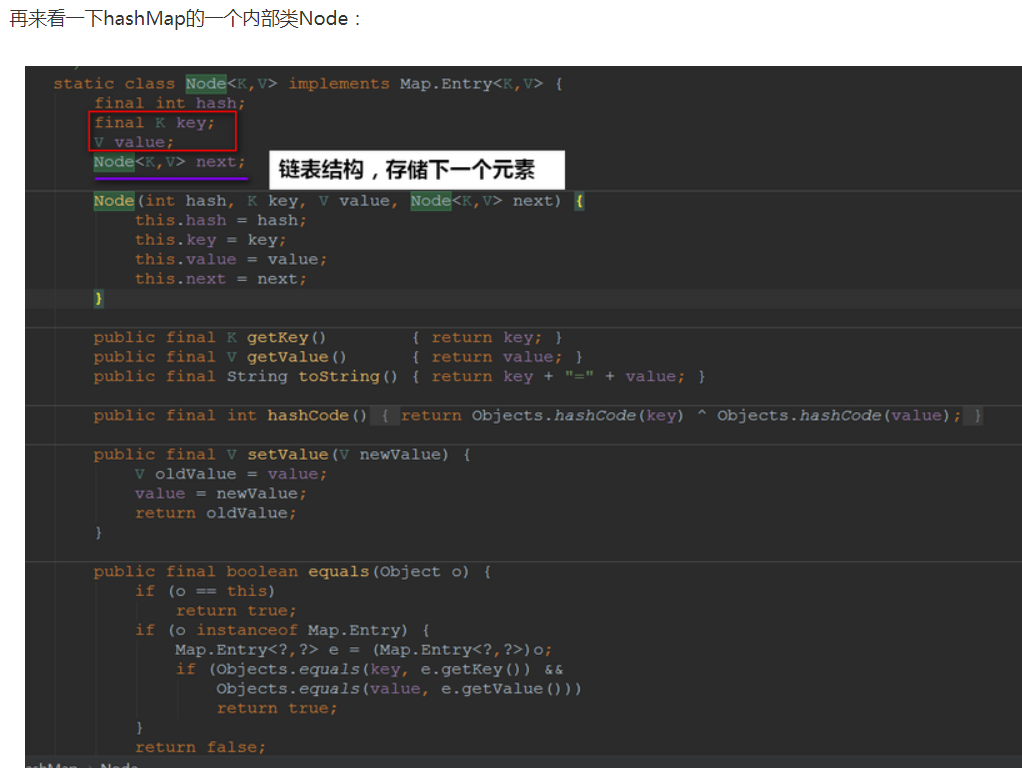
我们知道Hash存储的底层是散列表,而在Java中散列表的实现是通过数组+链表的~我
-
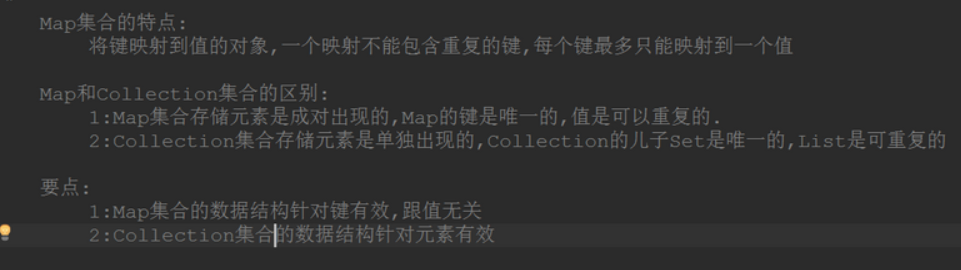
我们可以简单总结出HashMap:
- 无序,允许为null,非同步
- 底层由散列表(哈希表)实现
- 初始容量和装载因子对HashMap影响挺大的,设置小了不好,设置大了也不好
- 根据hash值确定key在数组中的索引:
-
我们是根据key的哈希值来保存在散列表中的,我们表默认的初始容量是16,要放到散列表中,就是0-15的位置上。也就是
tab[i = (n - 1) & hash]。可以发现的是:在做&运算的时候,仅仅是后4位有效~那如果我们key的哈希值高位变化很大,低位变化很小。直接拿过去做&运算,这就会导致计算出来的Hash值相同的很多。而设计者将key的哈希值的高位也做了运算(与高16位做异或运算,使得在做&运算时,此时的低位实际上是高位与低位的结合),这就增加了随机性,减少了碰撞冲突的可能性!
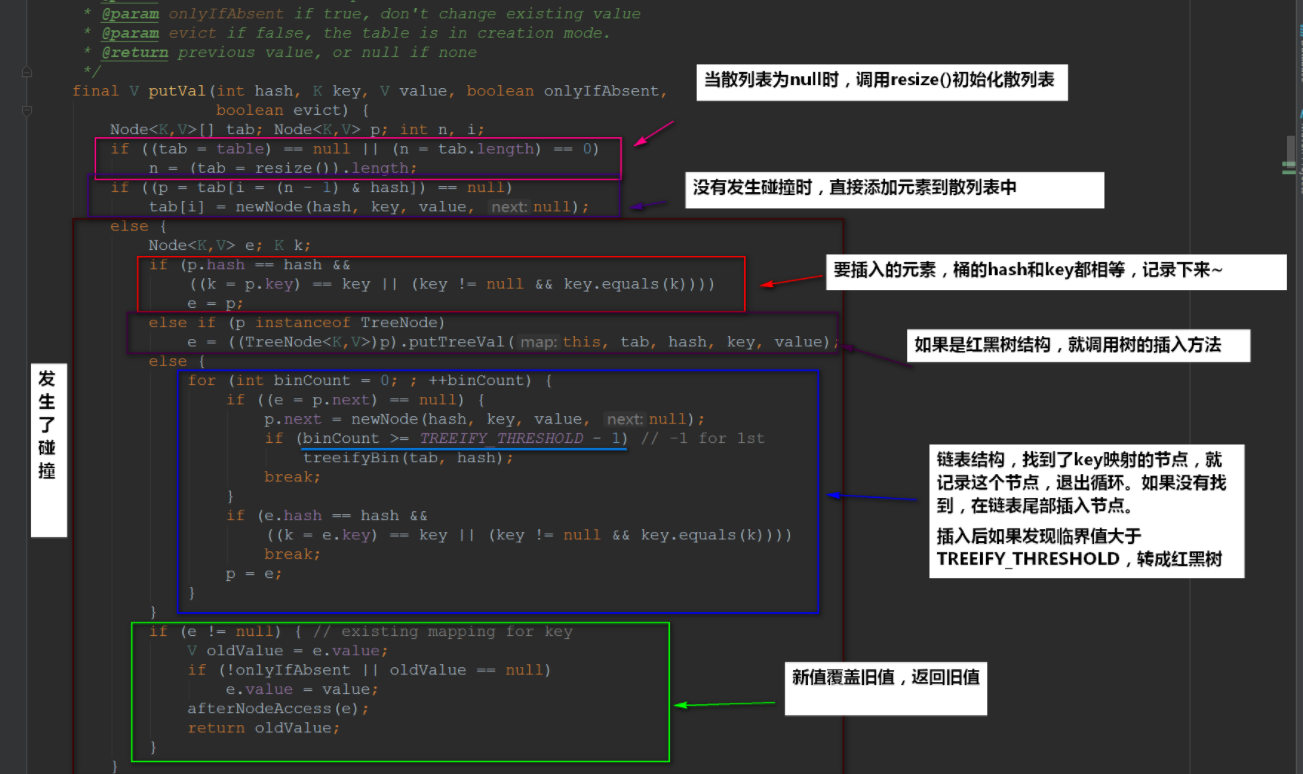
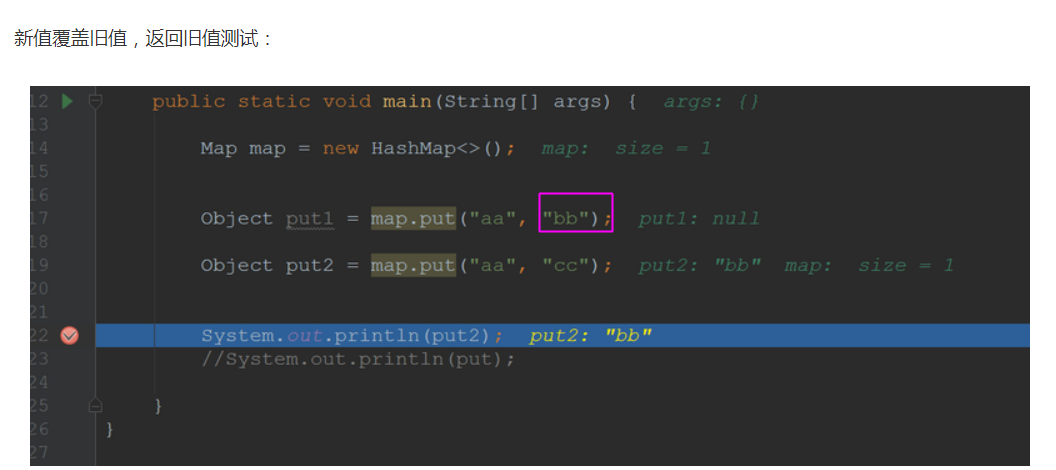
- put方法可以说是HashMap的核心,我们来看看: