做了半年的CNN算法移植,有时候需要回避一些东西,所以写的东西不能太多。简单提一下自己的总结,既是笔记,又是与网友们交流讨论。
CNN兴起,深圳这个躁动的城市很多人就想趁着这个机会捞一笔风投。于是各种基于CNN的在GPU上的demo出现后立马就成立公司,招FPGA工程师或者ARM 等嵌入式工程师,希望通过他们进行产品落地。毕竟GPU功耗高,散热不好,价格不便宜。于是有些公司招聘FPGA工程师,就问:你会做算法优化吗?
基于FPGA的CNN算法移植误区一:FPGA工程师做算法优化。
嗯,已经很不错了,知道将CNN移植到嵌入式平台需要做优化。可是百度一下CNN优化策略,那些基于tensorflow,caffe的东西是FPGA干的活儿吗(为啥不是算法工程师要懂FPGA呢,为难一下算法工程师)? 当然有人说作为FPGA工程师对算法一无所知没有核心竞争力,我想说CNN的算法压缩是在它原有的开发平台上进行的,不是在FPGA上进行的,愿意学CNN的算法开发平台的同学当然好,只是难度很大。还有一点,作为FPGA工程师目前形势很严峻,我们自身有太多东西要学,因为现在FPGA都往SOC发展了,xilinx推出的一大堆工具等待着我们去熟悉。还有一种思维那就是觉得xilinx很可能也走不远,所以趁早转行了的。
基于FPGA的CNN算法移植误区二:FPGA工程师先做demo再慢慢优化。
有些公司稍微好点,最后明白了算法优化是算法工程师干的事情。后面要求FPGA工程师按照目前这个样子做一款Demo出来,性能不好没关系,后面再慢慢优化。姑且不论HLS ,SDsoc的实现方法对于不同的算法差异有多大,因为这两个工具我才刚玩,可是基于HDL设计的硬件架构,算法改动一点点可能导致整个FPGA项目推倒重来。所以对于FPGA的工程,要不就是目前这个样子出结果。要不就是推倒重来。—— 或许HLS,SDsoc不是,你可以不断的选择优化策略。
基于FPGA的CNN算法移植误区三:性能不好怪FPGA工程师硬件架构不好?
这个我只能说或许,可是一般的FPGA工程师能去定制架构水平也不会太差,不至于胡拼乱凑一个工程出来,特别对于庞大的CNN想胡拼乱凑都难。你必须思路清晰,结构清晰。还有一个主要的,对于CNN算法移植FPGA硬件上真的开不出花儿,这个观点知乎上也有大牛提到了。所以深鉴公开DPU 架构,google公开TPU 架构,为何?因为硬件就是这么玩的,没啥新意。

这个是深鉴科技的 笛卡尔架构。对于FPGA工程师是不是很熟悉,就是典型的zynq架构,谁都会这么去设计。深鉴还有一款 亚里士多德 架构,把AXI4换成更高速的,外面再加一个处理器,和英伟达的GPU 架构类似。总结起来就是input buffer,处理,outputbuffer。只是inputbuffer和outputbuffer的数据怎么来怎么去,处理的时候有多少资源可以充分利用。例如google推出TPU的“脉动”结构,FPGA工程师一板子甩他脸上:你脉动个XX,不就是我们经常挂嘴边的流水线处理嘛。
基于FPGA的CNN算法移植误区四:算法实现了,剩下FPGA去实现就行
唉,真的好伤心,为啥这个锅要FPGA工程师背。前面说了,做算法移植是要优化后才能移植,不能直接移植,除非很小的算法(CNN 有小的吗?)可是算法工程师不懂硬件啊(是啊,为何要求我们硬件工程师懂算法呢),他优化的方法不一定正确,还有就是这里优化了,那里问题又出来了。所以算法demo出来后要不断的沟通如何去优化,FPGA工程师不断的去评估性能得出移植瓶颈反馈给算法工程师。如此反反复复。
误会解除了,与算法工程师沟通好了那么就要做FPGA架构了(我这个是纯HDL的方式)。查主芯片有多少资源可以用,可以并行加速多少路,如何实现数据交互。这些定制下来了你就可以列一个表格,去算你的项目latency了,这就是你的性能。性能达不到就去看看DSP 是不是充分利用了,尽量不要闲置。性能还达不到,就要反馈给算法算法移植瓶颈了,对于CNN通常是中间结果太大,就是缓存太大。FPGA工程师可以并行N路进行加速,可是DDR送数速率只够N/3路并行计算 —— 对,这就是典型的CNN算法移植瓶颈。
补充一点:做FPGA架构当然要去看软件的架构了。很多纯算法工程师不懂硬件,看下表。他们由下表就认为选择SqueezeNet网络作为项目算法网络结构,因为运算量MACC最小,参数也小,精度过的去。可是这个SqueezeNet目前没有找到一个效果不错的项目。这个表格是一个硕士他在做分类网络的时候给出的,他不懂FPGA,最后他选择了SqueezeNet,并且把MACC从8.6亿次优化到了5.3亿次。可是最终他的项目性能是 0.51帧(best)的速度

这里给大家看两个案例,看MACC ,案例2的MACC巨大,可是在7045上却可以实现17.53帧。因为SqueezeNet和YOLO网络的相差太大了,称之为 架构的魅力 (记住我说的是软件)
图1 是YOLO的软件算法架构,很简洁。HLS 也喜欢
图 2 是SqueezeNet 结构

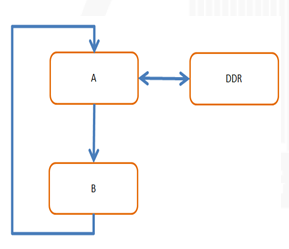
图 1
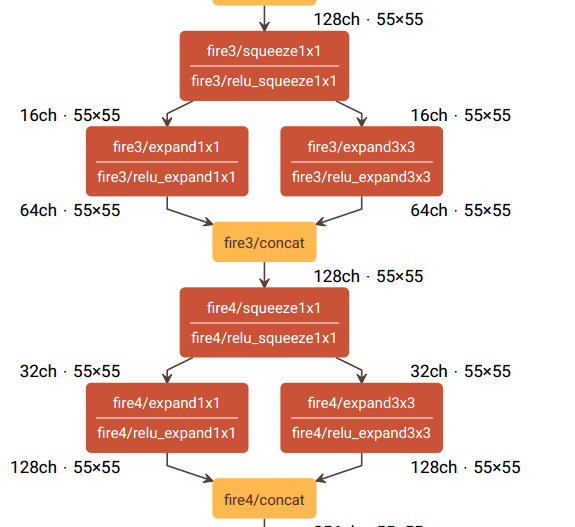
图 2
个人水平有限,以上言论抛砖引玉,有什么总结不当的地方欢迎及时指出来一起讨论。
。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。
。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。
作者:清霜一梦
欢迎加入: FPGA广东交流群:162664354