多线程和多进程概述:
当计算机运行程序时,就会创建包含代码和状态的进程。这些进程会通过计算机的一个或多个CPU执行。不过,同一时刻一个CPU只能执行一个进程,然后在不同进程间快速切换,这样就给人以多个程序同时运行的感觉。同理,在一个进程中,程序的执行也是在不同线程间进行切换的,每个线程执行程序的不同部分。
例如,一个工厂(网络爬虫)有多个车间(进程)负责不同的功能,一个车间又有多个车间工人(线程)协同合作,效率大大提升。
from multiprocessing import Pool pool=Pool(processes= num)#创建进程池,num为进程个数 pool.map(func,iterable)#func为爬虫函数,iterable为迭代参数,爬虫中,可为多个url列表进行迭代
实例:爬取酷狗歌单(做测试只返回不储存)
import requests #用于请求网页获取网页数据 from bs4 import BeautifulSoup #解析网页数据 import time #time库中的sleep()方法可以让程序暂停 import csv from multiprocessing import Pool ''' 爬虫测试_多进程 酷狗top500数据 写入csv文件 ''' ''' fp = open('D://kugou.csv','wt',newline='',encoding='utf-8')#创建csv writer = csv.writer(fp) writer.writerow(('rank','singer','song','time')) ''' #加入请求头 headers = { 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36' } #定义获取信息的函数 def get_info(url): wb_data = requests.get(url,headers=headers)#get方法加入请求头 soup = BeautifulSoup(wb_data.text,'html.parser')#对返回结果进行解析 #定位元素位置并通过selector方法获取 ranks = soup.select('span.pc_temp_num') titles = soup.select('div.pc_temp_songlist > ul > li > a') times = soup.select('span.pc_temp_tips_r > span') for rank,title,time in zip(ranks,titles,times): data = { 'rank':rank.get_text().strip(), 'singer':title.get_text().split('-')[0], 'song':title.get_text().split('-')[0],#通过split获取歌手和歌曲信息 'time':time.get_text().strip()#get_text()获取文本内容 } #writer.writerow((rank.get_text().strip(),title.get_text().split('-')[0],title.get_text().split('-')[0],time.get_text().strip())) # 获取爬取信息并按字典格式打印 #print(data) return data #程序主入口 if __name__ == '__main__': urls = ['http://www.kugou.com/yy/rank/home/{}-8888.html'.format(str(i)) for i in range(1,50)]#构造多页url start1=time.time() for url in urls: get_info(url)#循环调用 #time.sleep(1)#每循环一次,睡眠1秒,防止网页浏览频率过快导致爬虫失败 end1=time.time() print('串行爬虫用时',end1-start1) start2 = time.time() pool=Pool(processes= 2)#创建进程池 pool.map(get_info,urls) pool.close() end2 = time.time() print('两个进程用时', end2 - start2) start3 = time.time() pool = Pool(processes=4) pool.map(get_info, urls) pool.close() end3 = time.time() print('四个进程用时', end3 - start3)
运行结果:
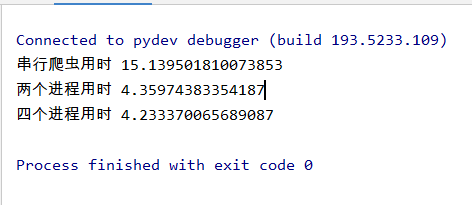
页数越多,效果越明显:
urls = ['http://www.kugou.com/yy/rank/home/{}-8888.html'.format(str(i)) for i in range(1,500)]
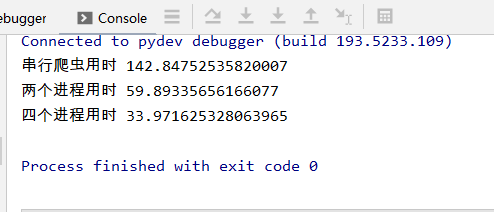
改为爬取10页:
urls = ['http://www.kugou.com/yy/rank/home/{}-8888.html'.format(str(i)) for i in range(1,10)]

页数少的情况下,完全没必要开启多进程