1.首先登录搜狗网http://sa.sogou.com/new-weball/page/sgs/epidemic?type_page=pcpop
2.刷新找到数据https://lspengine.map.sogou.com/coronavirus/epidemic/search/area/info(爬取时填写的url)
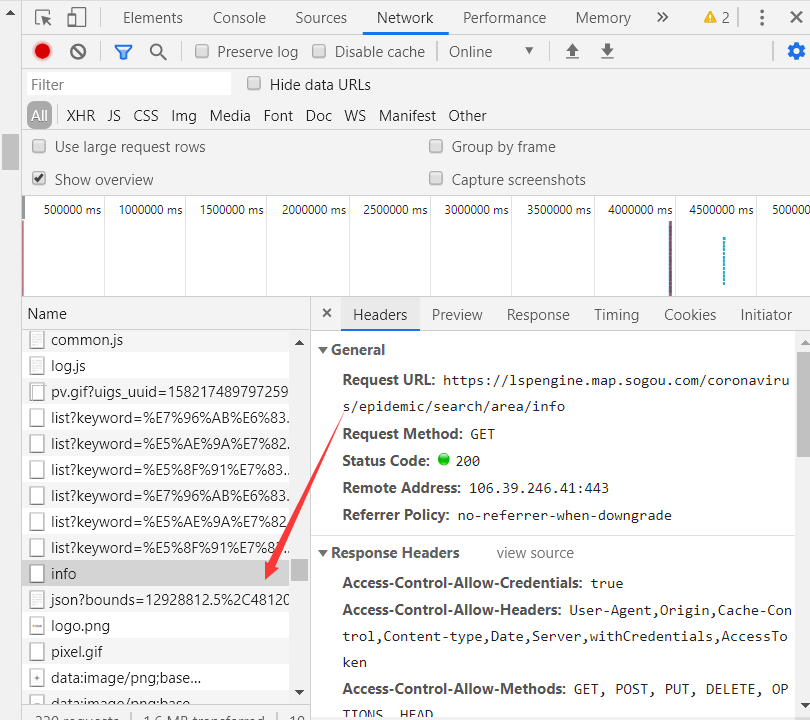
3.分析json数据结构:

4.清洗数据保存:
异常数据1:有的市没有“confirmedCount”,“suspectedCount”等属性

异常数据2:特别行政区不存在“cities”属性

源代码:
import requests #用于请求网页获取网页数据 import csv import os import json #创建csv outPath = 'D://yiqing_data.csv' if (os.path.exists(outPath)): os.remove(outPath) else: fp = open(outPath, 'wt', newline='', encoding='utf-8') # 创建csv writer = csv.writer(fp) writer.writerow(('provinceName', 'cityName', 'confirmedCount', 'curedCount', 'deadCount', 'suspectedCount')) #定义获取json数据的函数 def get_info(url): # 加入请求头 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36' } res = requests.get(url, headers=headers) # 将 JSON 对象转换为 Python 字典 json_data = json.loads(res.text) return json_data #处理json数据 def parse_data(data): for item in data['area']: print(item['provinceName']) writer.writerow((item['provinceName'], item['provinceName'], item['confirmedCount'], item['curedCount'], item['deadCount'], item['suspectedCount'])) if('cities' in item.keys()): for city in item['cities']: print(city['cityName']) if("suspectedCount" in city.keys()):#如果有确诊的,一定会有疑似的;那么没有疑似的则一定也没有确诊的 writer.writerow((item['provinceName'], city['cityName'], city['confirmedCount'], city['curedCount'], city['deadCount'], city['suspectedCount'])) else: writer.writerow((item['provinceName'], city['cityName'], '0', '0', '0', '0')) else:#排除类似特别行政区的 pass #程序主入口 if __name__ == '__main__': url = 'https://lspengine.map.sogou.com/coronavirus/epidemic/search/area/info' data=get_info(url) ''' for dict_data in data['area']: print(dict_data) ''' parse_data(data)
生成csv截图:
