Result文件数据说明:
Ip:106.39.41.166,(城市)
Date:10/Nov/2016:00:01:02 +0800,(日期)
Day:10,(天数)
Traffic: 54 ,(流量)
Type: video,(类型:视频video或文章article)
Id: 8701(视频或者文章的id)
文件部分如下:
1.192.25.84 2016-11-10-00:01:14 10 54 video 5551
1.194.144.222 2016-11-10-00:01:20 10 54 video 3589
1.194.187.2 2016-11-10-00:01:05 10 54 video 2212
1.203.177.243 2016-11-10-00:01:18 10 6050 video 7361
1.203.177.243 2016-11-10-00:01:19 10 72 video 7361
1.203.177.243 2016-11-10-00:01:22 10 6050 video 7361
1.30.162.63 2016-11-10-00:01:46 10 54 video 3639
1.84.205.195 2016-11-10-00:01:12 10 54 video 1412
1.85.61.18 2016-11-10-00:01:31 10 54 video 6578
1.85.61.37 2016-11-10-00:01:36 10 54 video 7212
101.200.101.13 2016-11-10-00:01:06 10 524288 video 11938
101.200.101.201 2016-11-10-00:01:03 10 4468 article 4779
101.200.101.204 2016-11-10-00:01:10 10 4468 article 11325
101.200.101.207 2016-11-10-00:01:08 10 4468 article 11325
流程:
数据清洗:按照进行数据清洗,并将清洗后的数据导入hive数据库中。
两阶段数据清洗:
(1)第一阶段:把需要的信息从原始日志中提取出来
ip: 199.30.25.88
time: 10/Nov/2016:00:01:03 +0800
traffic: 62
文章: article/11325
视频: video/3235
(2)第二阶段:根据提取出来的信息做精细化操作
ip--->城市 city(IP)
date--> time:2016-11-10 00:01:03
day: 10
traffic:62
type:article/video
id:11325
(3)hive数据库表结构:(将清洗出来的文件导入hive表中)
create table if not exists data(
mip string,
mtime string,
mday string,
mtraffic bigint,
mtype string,
mid string)
row format delimited fields terminated by ' ' lines terminated by '
';//导入数据以' '分隔,'
'换行
源代码:
import java.io.IOException;
import java.lang.String;
import java.util.*;
import java.text.SimpleDateFormat;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
public class Dataclean{
public static final SimpleDateFormat FORMAT = new SimpleDateFormat("d/MMM/yyyy:HH:mm:ss", Locale.ENGLISH); //原时间格式
public static final SimpleDateFormat FORMAT = new SimpleDateFormat("d/MMM/yyyy:HH:mm:ss", Locale.ENGLISH); //原时间格式
public static final SimpleDateFormat dateformat1 = new SimpleDateFormat("yyyy-MM-dd-HH:mm:ss");//现时间格式
private static Date parseDateFormat(String string) { //转换时间格式
Date parse = null;
try {
parse = FORMAT.parse(string);
} catch (Exception e) {
e.printStackTrace();
}
return parse;
}
public static String[] parse(String line) {
String ip = parseIP(line); //ip
String time = parseTime(line); //时间
String day=parseDay(line);//天数
String day=parseDay(line);//天数
String type = parseType(line); //视频video或文章article
String id = parseId(line); //视频或者文章的id
String traffic = parseTraffic(line);//流量
return new String[] { ip, time,day,traffic,type,id};
return new String[] { ip, time,day,traffic,type,id};
}
private static String parseIP(String line) { //ip
private static String parseIP(String line) { //ip
String ip = line.split(",")[0].trim();//str.trim(); 去掉首尾空格
return ip;
return ip;
}
private static String parseTime(String line) { //时间
private static String parseTime(String line) { //时间
final int first = line.indexOf(",");
final int last = line.indexOf(" +0800,");
String time = line.substring(first + 1, last).trim();
Date date = parseDateFormat(time);
return dateformat1.format(date);
}
private static String parseDay(String line) { //天数
private static String parseDay(String line) { //天数
String day = line.split(",")[2].trim();
return day;
return day;
}
private static String parseTraffic(String line) { //流量,转为int型
private static String parseTraffic(String line) { //流量,转为int型
String traffic= line.split(",")[3].trim();
return traffic;
return traffic;
}
private static String parseType(String line) {
private static String parseType(String line) {
String day = line.split(",")[4].replace(" ", "");
return day;
return day;
}
private static String parseId(String line) {
private static String parseId(String line) {
String day = line.split(",")[5].replace(" ", "");//去掉所有空格
return day;
return day;
}
public static class Map extends Mapper<Object, Text, Text, NullWritable> {
public static Text word = new Text();
public void map(Object key, Text value, Context context)throws IOException, InterruptedException {
public static class Map extends Mapper<Object, Text, Text, NullWritable> {
public static Text word = new Text();
public void map(Object key, Text value, Context context)throws IOException, InterruptedException {
// 将输入的纯文本文件的数据转化成String
String line = value.toString();
String arr[] = parse(line);
word.set(arr[0]+" "+arr[1]+" "+arr[2]+" "+arr[3]+" "+arr[4]+" "+arr[5]+" ");//一定用' ',空格容易乱会有意想不到的问题
context.write(word,NullWritable.get());
}
}
public static class Reduce extends Reducer<Text, NullWritable, Text, NullWritable> {
String line = value.toString();
String arr[] = parse(line);
word.set(arr[0]+" "+arr[1]+" "+arr[2]+" "+arr[3]+" "+arr[4]+" "+arr[5]+" ");//一定用' ',空格容易乱会有意想不到的问题
context.write(word,NullWritable.get());
}
}
public static class Reduce extends Reducer<Text, NullWritable, Text, NullWritable> {
// 实现reduce函数
public void reduce(Text key, Iterable<NullWritable> values,Context context) throws IOException, InterruptedException {
context.write(key, NullWritable.get());
}
}
public static void main(String[] args) throws Exception {
Configuration conf=new Configuration();
System.out.println("start");
Job job=Job.getInstance(conf);
job.setJarByClass(Dataclean.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);//设置map的输出格式
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
Path in = new Path("hdfs://localhost:9000/mapReduce/mymapreduce1/result.txt");
Path out = new Path("hdfs://localhost:9000/mapReduce/mymapreduce1/out");
FileInputFormat.addInputPath(job,in );
FileOutputFormat.setOutputPath(job,out);
boolean flag = job.waitForCompletion(true);
System.out.println(flag);
System.exit(flag? 0 : 1);
}
}
}
public static void main(String[] args) throws Exception {
Configuration conf=new Configuration();
System.out.println("start");
Job job=Job.getInstance(conf);
job.setJarByClass(Dataclean.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);//设置map的输出格式
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
Path in = new Path("hdfs://localhost:9000/mapReduce/mymapreduce1/result.txt");
Path out = new Path("hdfs://localhost:9000/mapReduce/mymapreduce1/out");
FileInputFormat.addInputPath(job,in );
FileOutputFormat.setOutputPath(job,out);
boolean flag = job.waitForCompletion(true);
System.out.println(flag);
System.exit(flag? 0 : 1);
}
}
清洗所得部分结果如下:
1.192.25.84 2016-11-10-00:01:14 10 54 video 5551 1.194.144.222 2016-11-10-00:01:20 10 54 video 3589 1.194.187.2 2016-11-10-00:01:05 10 54 video 2212 1.203.177.243 2016-11-10-00:01:18 10 6050 video 7361 1.203.177.243 2016-11-10-00:01:19 10 72 video 7361 1.203.177.243 2016-11-10-00:01:22 10 6050 video 7361 1.30.162.63 2016-11-10-00:01:46 10 54 video 3639 1.84.205.195 2016-11-10-00:01:12 10 54 video 1412 1.85.61.18 2016-11-10-00:01:31 10 54 video 6578 1.85.61.37 2016-11-10-00:01:36 10 54 video 7212
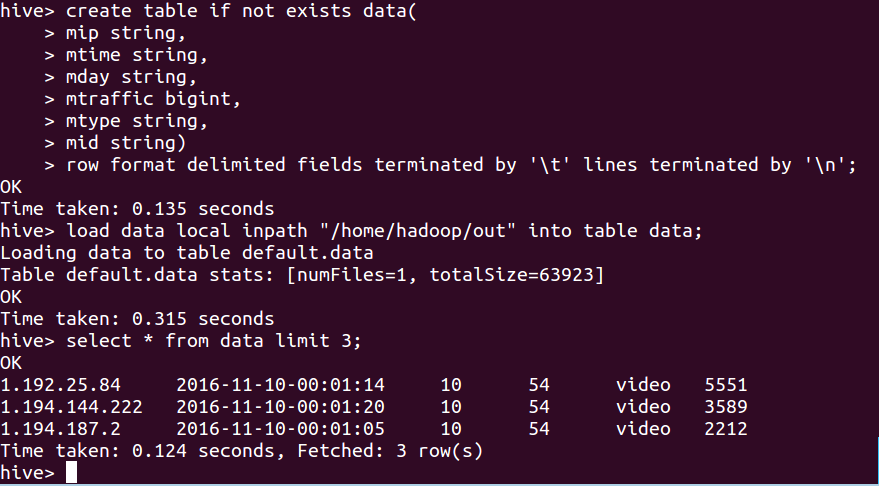
将清洗文件导入hive数据库表:
hive> create table if not exists data(
> mip string,
> mtime string,
> mday string,
> mtraffic bigint,
> mtype string,
> mid string)
> row format delimited fields terminated by ' ' lines terminated by ' ';
OK
Time taken: 0.135 seconds
hive> load data local inpath "/home/hadoop/out" into table data; //注:table后边的data是表名,前一个data不用动
Loading data to table default.data
Table default.data stats: [numFiles=1, totalSize=63923]
OK
Time taken: 0.315 seconds
hive> select * from data limit 3;
OK
1.192.25.84 2016-11-10-00:01:14 10 54 video 5551
1.194.144.222 2016-11-10-00:01:20 10 54 video 3589
1.194.187.2 2016-11-10-00:01:05 10 54 video 2212
Time taken: 0.124 seconds, Fetched: 3 row(s)
hive>
查看数据库表数据: