1、频率派概率和贝叶斯概率
概率论使能够我们能够提出不确定性的声明以及在不确定性存在的情况下进行推理。概率论最初的发展是为了分析事件发生的频率。有一类事件是可以重复的(比如投掷一枚硬币,观察硬币落到正面还是反面),当我们说一个结果发生的概率为p,则如果我们进行无数次的反复实验,有p的比例会导致这样的结果。而另一类事件是不能重复的,比如医生根据病人的症状判断病人有40%的概率患有流感,在这个例子中,概率用来表示一种信任度,1表示非常肯定病人患有流感,0表示非常肯定病人没有流感。前面的一种概率,直接与时间发生的频率相联系,称之为频率派概率(frequentist probability);而后者则涉及到确定性水平,叫做贝叶斯概率(Bayesian probability)。
2、随机变量
一个事件的所有可能结果组成这个事件的样本空间,其中的每一种结果叫做样本点。如果对于每一个样本点,都有一个唯一的实数与之对应,则就产生了一个样本点到唯一实数之间的函数,我们称该函数为随机变量。通俗地讲,随机变量就是将随机事件的结果量化。比如同时投掷两枚骰子,观察两枚骰子的点数,则样本空间共有36个样本点组成({(i,j)|i=1,2...,6; j=1,2,...,6}),这里可以构造多个随机变量,比如随机变量x用来计算两个骰子点数之和,则x={2,3,...,12},这里就将每一个实验结果和一个实数映射了起来;再比如投掷一枚硬币,可能出现正面和反面,我们将正面映射到1,反面映射到0,则x(正面)=1,x(反面)=0,所以有(P({
m x}=1)=0.5,P({
m x} = 0)=0.5)。所以,随机变量实质上是函数。随机变量中的每一个取值及取值的概率被称为概率分布。
随机变量可以是离散的,也可以是连续的。如果一个随机变量的全部可能取值,只有有限多个或可列无穷多个,则称它是离散型随机变量,比如上面的计算两个骰子点数之和。相反,如果随机变量的取值为连续的(如全部实数,一段区间),则称它为连续型随机变量。
离散型随机变量对应的常见分布有:
- 两点分布
- 二项分布
- 几何分布
- 超几何分布
- 均匀分布
- 泊松分布
连续型随机变量对应的常见分布有:
我们通常用无格式字体 (plain typeface) 中的小写字母来表示随机变量本身,而用手写体中的小写字母来表示随机变量能够取到的值。例如,(x_1) 和 (x_2) 都是随机变量 x 可能的取值,对于向量值变量,我们会将随机变量写成 x,它的一个可能取值为 (x)。
3、离散型随机变量及其分布律
离散型随机变量的概率分布可以用分布律来描述(或者称为概率质量函数,probability mass function, PMF )。我们通常用大写字母(P)来表示离散型随机变量的分布律,如(P()x())表示离散型随机变量x的分布律。
分布律将随机变量中的每个取值映射到该取值的概率。x = (x)的概率用(P()x(=x))来表示。有时我们会先定义一个随机变量x,然后使用符号~来说明它遵循的分布:x~(P()x())。
分布律可以作用于多个随机变量,这种多个随机变量的概率分布被称为联合概率分布(joint probability distribution),如(P()x=(x), y(=y))表示x=(x),y=(y)同时发生的概率,有时可以简写为(P(x,y))。
如果P是一个随机变量的分布律,则要满足下面几个条件:
- (P)的定义域是 x 的所有可能取值的集合。
- 对(∀x∈
m x,0≤P(x)≤1)。不可能事件概率为0,必然事件概率为1。
- (Σ_{x∈
m x}P(x)=1),也就是(P(x))的所有取值之和为1,我们称这条性质为归一化的(normalized)。
4、连续型随机变量及其概率密度函数
连续型随机变量的概率分布可以使用概率密度函数(probability density function, PDF)来描述。如果一个函数(p)是概率密度函数,则(p)需要满足以下几条性质:
- (p)的定义域是 x 的所有可能取值的集合。
- 对(∀x∈
m x,p(x)≥0),注意,这里并不要求(p(x)≤1),因为(p(x))只是概率密度函数,对(p(x))积分才是概率分布律。
- (P(a<{
m x}≤b) = int^b_a p(x){
m d}x),含义是(x)落到区间(a,b]的概率((a,b),[a, b], (a,b], [a, b)均满足这个公式)。
- (int p(x){
m d}x=1)
下面用一个例子来解释上面的几条性质。
考虑在区间[a, b]上的均匀分布,我们用(u(x;a,b))表示该分布的概率密度函数,(x)表示以(x)为参数,a,b是区间的端点且b>a,也就是({
m x})~(u(x;a,b)),则该均匀分布的概率密度曲线如下:
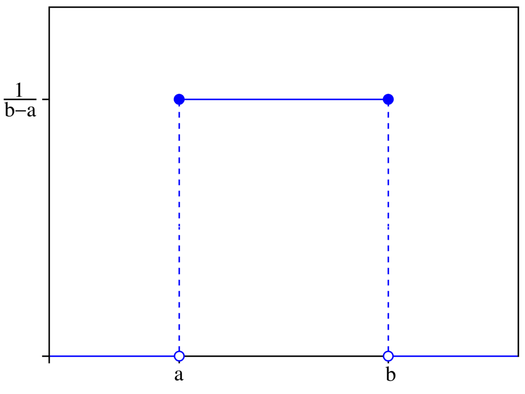
可以看到$u(x;a,b)={frac{1}{b-a}}$,而且该函数的任一点都是非负的,且在[a, b]上对$u(x;a,b)$积分的结果为1。
### 5、边缘概率分布
有时候,我们知道了一组变量的**联合概率分布**,但我们想了解某一个子集的概率分布,则这种定义在子集上的概率分布被称为**边缘概率分布**(marginal probability distribution)。
为什么叫**边缘**概率分布呢? 举个例子,假如有两个随机变量x, y的二维联合概率分布如下表:
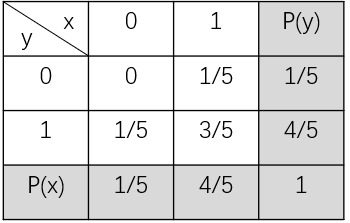
其中$P(x)$和$P(y)$为分别考虑随机变量x和y时的概率,我们通常将其写在表格的边缘处,故称之为边缘概率。
从上表可以看出,$P({
m x}=0)$的概率为x=0时对y的各概率相加,也就是0+1/5=1/5,用公式表示为:
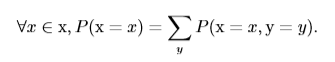
这称为**求和法则**(sum rule)。
上面的例子中的随机变量为离散型的,若随机变量为连续型的,我们需要用积分代替求和:

该公式为x的边缘概率分布,对x积分可得y的边缘概率分布。
### 6、条件概率
在很多情况下,我们感兴趣的是一个事件已经发生的情况下,另一个事件发生的概率,这种概率叫做**条件概率**。在事件x已经发生的情况下,事件y发生的概率表示为$P({
m y}=y|{
m x}=x)$,可通过下面的公式计算:

其中$P({
m y}=y,{
m x}=x)$为$x$和$y$同时发生的概率(也就是联合概率分布)。条件概率只在$P({
m x}=x)>0$时有意义。
### 7、条件概率的链式法则
从上节的条件概率公式可以知道两个事件b,c同时发生的概率:$$P(b, c)=P(b|c)P(c)$$,则三个事件a,b,c同时发生的概率为:$$P(a,b,c)=P(a|b,c)P(b,c)=P(a|b,c)P(b|c)P(c)$$,由数学归纳法可以得到:
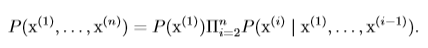
含义是任何多维随机变量的联合概率分布,都可以分解成只有一个变量的条件概率相乘的形式。这个规则被称为**链式法则**或**乘法法则**。
### 8、独立性和条件独立性
#### 8.1、独立性
如果两个随机变量(事件)x,y同时发生的概率等于这两个变量(事件)单独发生的概率乘积,则称这两个随机变量是独立的,即:
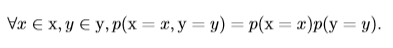
也就是x和y的联合概率分布等于两个边缘概率分布之积。
#### 8.2、条件独立性
如果在随机变量(事件)z已经发生的情况下,随机变量(事件)x和y同时发生的概率等于x和y在z已发生的情况下分别发生的概率乘积,即:
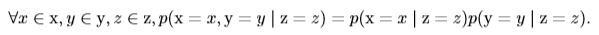
我们称之为x和y在给定z的情况下是**条件独立**的。
有一种简化表示:x⊥y表示x和y相互独立,x⊥y|z表示x和y在给定z时条件独立。
### 9、期望、方差和协方差
#### 9.1、期望
**期望**(expectation)就是随机变量取值的平均值。设$f(x)$是随机变量x的函数,则对于离散型随机变量x,f(x)的期望可以通过求和得到(比如我们知道x的分布,求$f(x)=x^2$的期望):
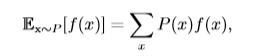
对于连续型随机变量x,f(x)的期望通过积分得到:
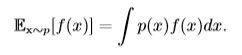
$mathbb{E}_x[f(x)]$表示f(x)的期望,当期望作用的随机变量很明显时,我们可以不写脚标,简写为$mathbb{E}[f(x)]$。默认地,我们假设$mathbb{E}[·]$对方括号内的所有随机变量的值取平均值,当没有歧义时,我们还可以省略方括号。
**期望是线性的**,如:
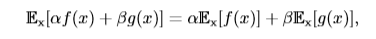
#### 9.2、方差
期望反映了随机变量分布的平均取值,但在实际问题中,我们不仅关心随机变量的平均取值,还关心随机变量的取值与平均取值(期望)的偏离程度,**方差**(variance)就是用来衡量这种偏离程度的,也就是衡量随机变量x取值的差异性。设f(x)是随机变量x的函数,则f(x)方差的计算公式如下:
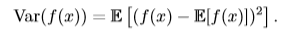
方差越小,则f(x)的值越接近f(x)的期望值。方差的平方根被称为**标准差**(standard deviation)。
#### 9.3、协方差
**协方差**(covariance)在某种意义上给出了两个随机变量之间的相关程度的大小。如随机变量x和y相互独立,则x与y的协方差Cov(x, y)=0。设f(x)是x的函数,g(y)是y的函数,则f(x)和g(y)的协方差计算方法为:
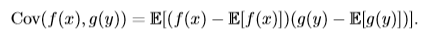
协方差的**绝对值**如果很大则意味着变量值变化很大并且它们同时距离各自的均值很远。如果协方差是正的,那么两个变量都倾向于同时取得相对较大的值。如果协方差是负的,那么其中一个变量倾向于取得相对较大的值的同时,另一个变量倾向于取得相对较小的值,反之亦然。其他的衡量指标如**相关系数**(correlation)将每个变量的贡献归一化,为了只衡量变量的相关性而不受各个变量尺度大小的影响。
协方差和相关性是有联系的,但实际上是不同的概念。它们是有联系的,因为两个变量如果相互独立那么它们的协方差为零,如果两个变量的协方差不为零那么它们一定是相关的。然而,独立性又是和协方差完全不同的性质。两个变量如果协方差为零,它们之间一定没有线性关系。独立性比零协方差的要求更强,因为独立性还排除了非线性的关系。两个变量相互依赖但具有零协方差是可能的。
随机向量(由多个随机变量组成的向量)$x∈mathbb{R}^n$的**协方差矩阵**(covariance matrix)是一个nxn的矩阵,并且满足:
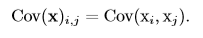
协方差矩阵的对角元是方差:
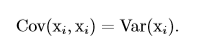
### 10、常见的分布
#### 10.1、伯努利分布(Bernoulli distribution)
一般把只有两个对立结果的实验叫做**伯努利实验**,如投硬币就是一个伯努利实验,因为投掷的结果只有正面和反面。把伯努利实验在相同条件下重复进行n次,且这n次实验相互独立,则称这n次实验为**n重(次)伯努利实验**,或称为**伯努利概型**,对应的概率分布叫做**二项分布**。当n=1时,二项分布变为**伯努利分布**(又称**两点分布**,或者**0-1分布**),也就是说伯努利分布是只进行1次伯努利试验的概率分布。伯努利分布适用于离散型随机变量。
伯努利分布由单个参数Φ∈[0,1]控制,Φ给出了随机变量x等于1(如硬币正面)的概率,则P(x=0)=1-Φ。伯努利分布具有如下性质:
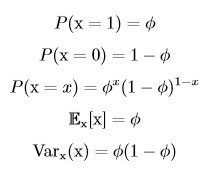
#### 10.2、多项式分布(multinoulli distribution)
在10.1中介绍了**二项分布**,指在每次实验中,实验结果只有两个状态(投硬币)。若每次实验的实验结果有k个状态(投骰子),进行n次相互独立的实验对应的概率分布叫做**多项式分布**,或者**范畴分布**。多项式分布由向量$p∈[0, 1]^{k-1}$参数化,其中$p_i$表示第i个状态发生的概率,最后第k个状态的概率可以通过$1-1^Tp$求出。多项式分布适用于离散型随机变量。
伯努利分布和多项式分布足够用来描述在它们领域内的任意分布。它们能够描述这些分布,不是因为它们特别强大,而是因为它们的领域很简单;它们可以对那些能够将所有的状态进行枚举的离散型随机变量进行建模。当处理的是连续型随机变量时,会有不可数无限多的状态,所以任何通过少量参数描述的概率分布都必须在分布上加以严格的限制。
#### 10.3、正态分布(normal distribution)
实数上最常用的分布就是**正态分布**(normal distribution),也称为**高斯分布** (Gaussian distribution):
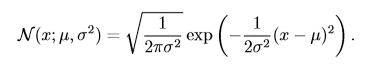
下图为正态分布的概率密度函数:
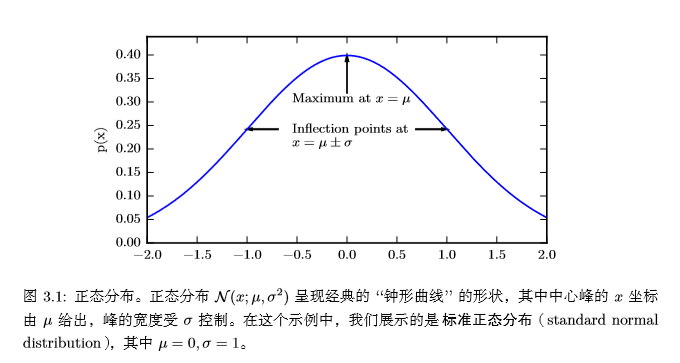
在曲线形状上,若固定μ,σ越小,曲线越瘦高;σ越大,曲线越矮胖。
正态分布由两个参数控制:$μ∈mathbb{R}$和$σ∈(0,+infty)$。σ表示正态变量取值的集中或分散程度,σ越大,取值也就越分散;而参数μ则反映了正态变量的平均取值和取值的集中位置。实际上,$μ$和$σ^2$分别是正态变量的均值和方差。
当我们要对概率密度函数求值时,我们需要对 σ 平方并且取倒数。当我们需要经常对不同参数下的概率密度函数求值时,一种更高效的参数化分布的方式是使用参数 β ∈ (0,∞),来控制分布的**精度**(precision)(或方差的倒数):
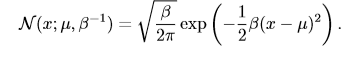
当我们由于缺乏关于某个实数上分布的先验知识而不知道该选择怎样的形式时,正态分布是默认的比较好的选择。
正态分布也可以扩展到n维空间,这种情况被称为**多维正态分布**,它的参数是一个正定矩阵**Σ**(特征值均为正数):
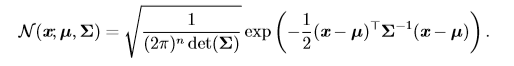
参数 **µ** 仍然表示分布的均值,只不过现在是向量值。参数 **Σ** 给出了分布的协方差矩阵。我们常常把协方差矩阵固定成一个对角阵。一个更简单的版本是**各向同性** (isotropic)高斯分布,它的协方差矩阵是一个标量乘以单位阵。
#### 10.4、指数分布和Laplace分布
在深度学习中,我们经常会需要一个在 x = 0 点处取得**边界点**(sharp point) 的分布。我们可以使用**指数分布**来达到这一目的:
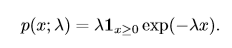
一个联系紧密的概率分布是**Laplace分布**(Laplace distribution,拉普拉斯分布),它允许我们 在任意一点 µ 处设置概率质量(分布律)的峰值 :
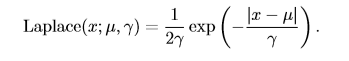
#### 10.5、Dirac分布和经验分布
#### 10.5.1、Dirac分布
在一些情况下,我们希望概率分布中的所有质量都集中在一个点上。这可以通过**Dirac delta 函数**(Dirac delta function,狄拉克函数)δ(x) 定义概率密度函数来实现: $$p(x)=σ(x)$$
狄拉克函数可以被描述成在原点处无限高,无限窄的曲线,并且它的积分为1,也就是说该函数在原点处取值为$+infty$,其他点处为0。通过把 p(x) 定义成 δ 函数左移 −µ 个单位,我们得到了一个在 x = µ 处具有无限窄也无限高的峰值的概率密度函数:$$p(x)=σ(x-μ)$$
#### 10.5.2、经验分布
Dirac 分布经常作为**经验分布**(empirical distribution)的一个组成部分出现:
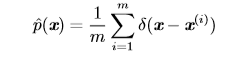
经验分布将概率密度 1/m 赋给 m 个点 $x^{(1)},...,x^{(m)}$ 中的每一个,这些点是给定的数据集或者采样的集合。只有在定义连续型随机变量的经验分布时,Dirac delta 函数才是必要的。对于离散型随机变量,情况更加简单:经验分布可以被定义成一 个 Multinoulli 分布,对于每一个可能的输入,其概率可以简单地设为在训练集上那个输入值的**经验频率**(empirical frequency)。
当我们在训练集上训练模型时,我们可以认为从这个训练集上得到的经验分布指明了我们采样来源的分布。关于经验分布另外一种重要的观点是,它是训练数据的似然最大的那个概率密度函数 。
### 11、分布的混合
通过组合一些简单的概率分布来定义新的概率分布也是很常见的。一种通用的组合方法是构造**混合分布**(mixture distribution)。混合分布由一些组件 (component) 分布构成。我们在上一节中已经看过一个混合分布的例子了:实值变量的**经验分布**对于每一个训练实例来说,就是以 Dirac 分布为组件的混合分布。
### 12、常用函数的有用性质
#### 12.1、logistic sigmoid函数
**logistic sigmoid函数**的表示如下:
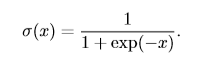
logistic sigmoid 函数通常用来**产生伯努利分布中的参数 ϕ**,因为它的范围是 (0,1),处在 ϕ 的有效取值范围内。下面是logistic sigmoid函数的曲线:
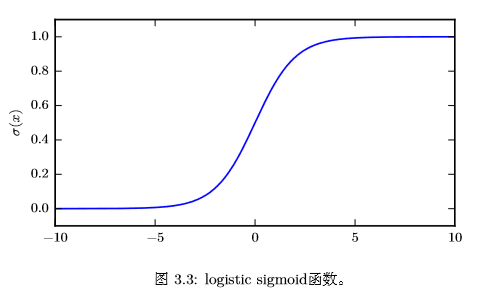
sigmoid函数在变量取绝对值非常大的正值或负值时会出现饱和(saturate)现象,意味着函数会变得很平,并且对输入的微小改变会变得不敏感。
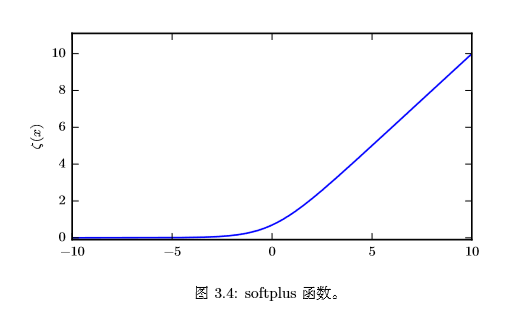
#### 12.2、softplus函数
**softplus函数**的表示如下:
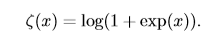
softplus 函数可以用来**产生正态分布的 β 和 σ 参数**,因为它的范围是 (0,∞)。softplus的函数名来源于它是另一个函数的平滑形式,这个函数是:
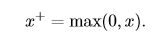
该函数被称为**正部函数**。
softplus的函数曲线如下图所示:
#### 12.3、有用的性质
关于logistic sigmoid函数和softplus函数有一些非常有用的性质:
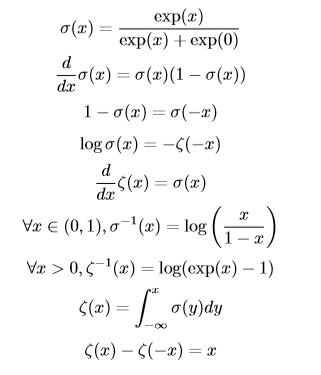
### 13、贝叶斯规则
我们经常会在已知$P(y|x)$的时候来计算$P(x|y)$,这时我们可以使用下面的公式:$$P(x|y)=frac{P(x,y)}{P(y)}=frac{P(x)P(y|x)}{P(y)}$$,但$P(y)$有时是不知道的,我们可以使用公式$P(y) = Σ_xP(y|x)P(x)$来计算。
### 14、结构化概率模型
机器学习的算法经常涉及到在非常多的随机变量上的概率分布,通常这些随机变量中的直接相互作用只牵扯到非常少的变量。使用单个函数来描述整个联合概率分布是非常低效的,这时,我们可以把单个函数分解成因子相乘的形式。比如,有三个随机变量a,b,c,a影响b的取值,b影响c的取值,但a和c在b给定的情况下是独立的,则$$p(a,b,c)=p(b)p(a,c|b)=p(b)p(a|b)p(c|b)$$
这种分解可以极大地减少描述一个分布的参数数量。
我们还可以使用图论中的图来表示这种分解,随机变量代表图中的结点,边表示随机变量间是否有联系。假设有5个随机变量a,b,c,d,e,它们对应的图如下:
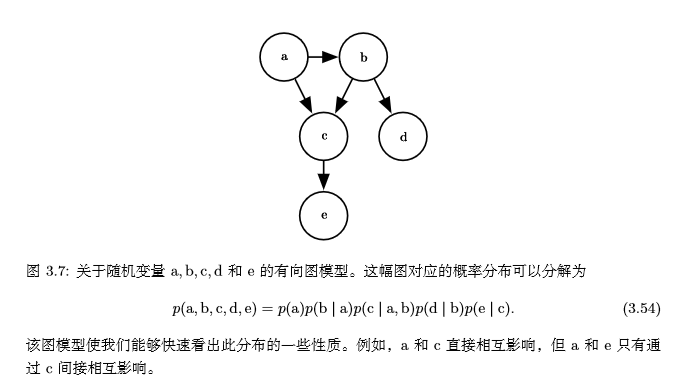
当我们用图来表示联合概率分布的分解时,我们把它称为**结构化概率模型**(structured probabilistic model)或者**图模型** (graphical model)。
有两种主要的结构化概率模型:**有向的**和**无向的**。两种图模型都使用图 G,其中 图的每个节点对应着一个随机变量,连接两个随机变量的边意味着概率分布可以表示成这两个随机变量之间的直接作用。
上面的例子是**有向模型**(directed),它们使用条件概率来表示分解,另一种是**无向模型**。无向模型使用带有无向边的图,它们将分解表示为函数,通常这些函数并不是任何类型的概率分布。在图G中,如果一个子图中的结点两两互连,则称该子图为**团**,记为$C^(i)$。无向模型中的每个团$C^(i)$都伴随着一个因子$Φ^(i)(C^(i))$,这些因子仅仅是函数,不是概率分布,每个因子的输出都必须是**非负的**,因子的和或者积分不要求为1。一个无向模型的例子:
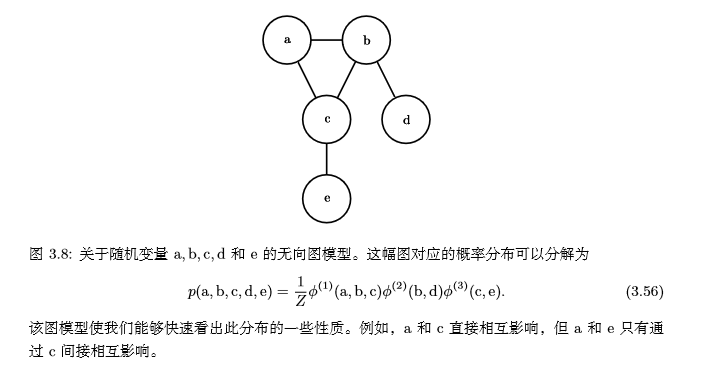
请记住,这些图模型表示的分解仅仅是描述概率分布的一种语言。它们不是互相排斥的概率分布族。有向或者无向不是概率分布的特性,它是概率分布的一种特殊**描述**(description)所具有的特性,而任何概率分布都可以用这两种方式进行描述。
### 15、参考
#### 15.1、《深度学习》中文版