一、open文件打开和with open as 文件打开的区别
1 file= open("test.txt","r") 2 try: 3 for line in file.readlines(): 4 print(line) 5 except: 6 print("error") 7 finally: 8 file.close()
1 with open("test.txt","r") as file: 2 for line in file.readlines(): 3 print(line)
用with语句的好处,就是到达语句末尾时,会自动关闭文件,即便出现异常。
with语句实际上是一个非常通用的结构,允许你使用所谓的上下文管理器。上下文管理器是支持两个方法的对象:__enter__和__exit__。
方法__enter__不接受任何参数,在进入with语句时被调用,其返回值被赋给关键字as后面的变量。
方法__exit__接受三个参数:异常类型、异常对象和异常跟踪。它在离开方法时被调用(通过前述参数将引发的异常提供给它)。如果__exit__返回False,将抑制所有的异常。
文件也可用作上下文管理器。它们的方法__enter__返回文件对象本身,而方法__exit__关闭文件
with语句作用效果相当于上面的try-except-finally
二、csv文件的读取
1 with open('test.csv', 'r') as csv_file: 2 reader = csv.reader(csv_file) 3 #print(list(reader)) 4 for item in reader: #按行读取 5 print (item)
>>> list(reader)---> [['name','age'], ['Bob','14'], ['Tom','23'], ...]
>>> item -->
['name','age']
['Bob','14']
['Tom','23']
...
三、csv文件的写入
1 import csv 2 header = ['name','age'] 3 data = [ 4 ['Bob',14], 5 ['Tom',23], 6 ['Jerry',18] 7 ] 8 with open('test.csv', 'w', newline='')as csv_file: 9 csv_writer = csv.writer(csv_file) 10 csv_writer.writerow(header) 11 # csv_writer.writerows(data) # 写入多行 12 for row in data: 13 csv_writer.writerow(row) # 单行写入
指定newline='',则可以避免每写入一行就写入一空行。
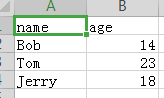
四、DictReader和DictWriter操作csv
使用DictReader可以像操作字典那样获取数据,把表的第一行(一般是标头)作为key。可访问每一行中那个某个key对应的数据。
1 with open('test.csv', 'r')as csv_file: 2 dict_reader = csv.DictReader(csv_file) 3 name_list = [row['name'] for row in dict_reader] 4 print(name_list) 5 print(len(list(dict_reader)))
>>> ['Bob', 'Tom', 'Jerry']
>>> 0
dict_reader只能迭代一次
1 header = ['name', 'age'] 2 data = [ 3 {'name': 'Bob', 'age': 14}, 4 {'name': 'Tom', 'age': 23}, 5 {'name': 'Jerry', 'age': 18} 6 ] 7 with open('test.csv', 'w', newline='')as csv_file: 8 dict_writer = csv.DictWriter(csv_file, header) 9 dict_writer.writeheader() 10 dict_writer.writerows(data) # 写入多行 11 for row in data: 12 dict_writer.writerow(row) # 单行写入