背景
最近在使用EFCore2.2进行查询后并排序的过程中发现了一个问题,就是查询的过程使用了Include后代码生成的SQL不符合预期,并且性能上面有很大的问题,借此写一篇文章来进行分析。
1.1 EFCore语句
LinQ语句 _ = _repairContractRepository.GetAll().Include(r => r.RepairContractWorkItems).OrderByDescending(r => r.CreateTime).Take(20).ToList();
在上面的例子中_repairContractRepository表示的是实体RepairContract的仓储,在代码中的定义是:private readonly IRepository<RepairContract, Guid> _repairContractRepository;另外一个RepairContract对应多个RepairContractWorkItem,两个实体之间是一对多的关系,在EFCore中通过Include方法来一次性查询出关联的对象,后面我们将查询的结果按照主单的CreateTime进行排序并取前20条,我们来看看这条语句生成的SQL是否符合预期。
1.2 生成的SQL语句
SELECT TOP (20) r.* FROM [RepairContract] AS [r] ORDER BY [r].[CreateTime] DESC, [r].[Id]
明明只是按照CreateTime进行排序,为什么后面会加一个[r].[Id],这个问题该怎么解释,多了一个按照主单Id升序排列到底有什么影响,我们来看看具体的统计信息。
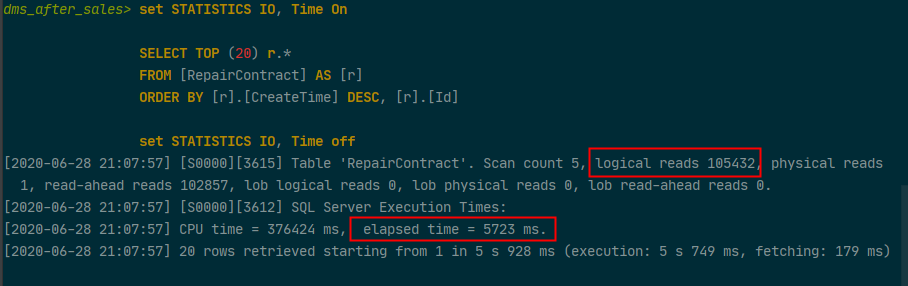
图一 加了导航属性生成SQL及部分参数统计
在我们的数据库中主单RepairContract大概有26万条数据,我们已经在CreateTime上面创建了索引,按照道理不会这么慢,那我们试着去掉[r].[Id]来看看到底有什么差别。
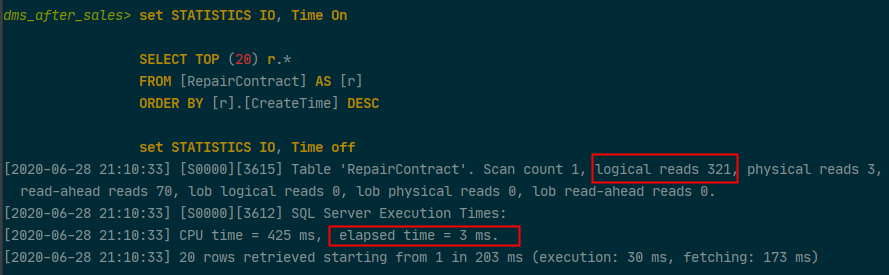
图二 未加导航属性生成SQL及部分参数统计
结果查询的时间从5723毫秒一下子降到了3毫秒,性能产生了巨大的提升,为什么会产生这个原因呢?事后发现是因为在查询的过程中使用了导航属性Include,去掉这个导航属性之后就能够生成符合我们预期的SQL语句了,所以在使用Include查询并进行排序的过程中一定要注意看最终生成的SQL是否符合预期,至于为什么加了导航属性后进行排序会多出一部分排序,这个也没有发现原因。
结论
其实对于这个问题早在EF框架的时候就有这个问题,你可以看看这篇文章,现阶段的解决方式只有在使用导航属性后尽量不要去Order By操作,如果真要进行排序操作,那么就不要使用Include的导航属性来直接进行操作,这个在使用EFCore2.2版本的时候需要特别注意。