上一篇:二进制安装Prometheus
 下面准备在监控的流程中呈现到告警到企微
下面准备在监控的流程中呈现到告警到企微
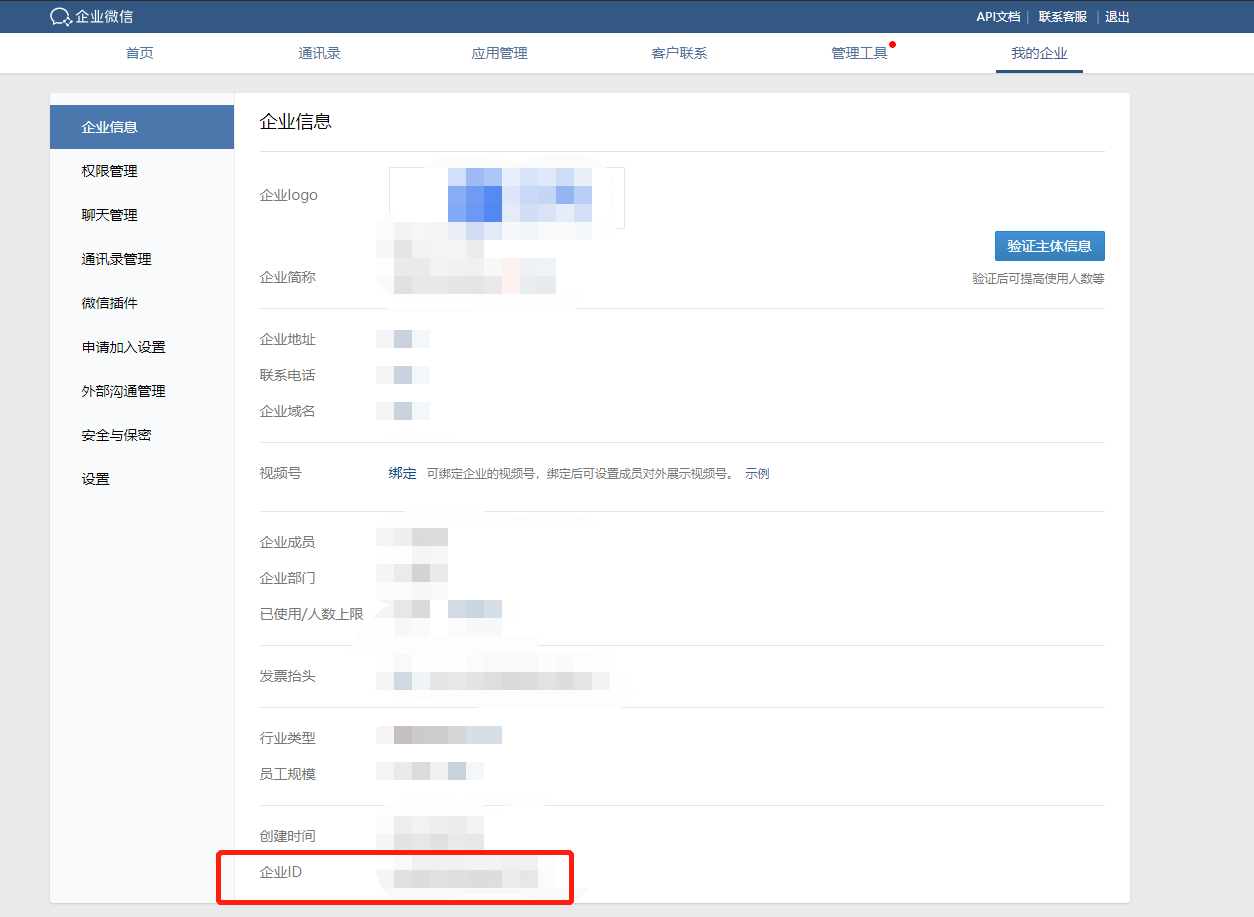
查看企业ID,用于后续配置文件
四、安装Alertmanager
1、准备安装的包
--选择上面链接给的Linux的tar包
alertmanager-0.22.2.linux-amd64.tar.gz wget https://github.com/prometheus/alertmanager/releases/download/v0.22.2/alertmanager-0.22.2.linux-amd64.tar.gz
2、下载完之后直接解压并放到/usr/local/prometheus目录,便于管理
[root@zhoujt prometheus]# tar -zxvf alertmanager-0.22.2.linux-amd64.tar.gz [root@zhoujt prometheus]# cp -r alertmanager-0.22.2.linux-amd64 /usr/local/prometheus/alertmanager [root@zhoujt prometheus]# cd /usr/local/prometheus/alertmanager/ [root@zhoujt alertmanager]# ls alertmanager alertmanager.yml amtool LICENSE NOTICE [root@zhoujt alertmanager]# ./alertmanager --version alertmanager, version 0.22.2 (branch: HEAD, revision: 44f8adc06af5101ad64bd8b9c8b18273f2922051) build user: root@b595c7f32520 build date: 20210602-07:50:37 go version: go1.16.4 platform: linux/amd64
3、配置alertmanager
[zhoujt@zhoujt alertmanager]$ cat alertmanager.yml global: #每五分钟检查一次是否恢复 resolve_timeout: 5m # SMTP的相关配置 # smtp_smarthost: smtp.263.net:587 # smtp_from: no-reply@xxx.com # smtp_auth_username: no-reply@xxx.com # smtp_auth_password: xxx # 路由的根节点,每个传进来的报警从这里开始 route: group_by: ['alertname'] # 将传入的报警中有这些标签的分为一个组 group_wait: 10s # 第一次触发报警的延时 group_interval: 10s # 自第一次告警等待多久发送压缩的警报 repeat_interval: 1m # 重复告警发送间隔 receiver: 'wechat' # 定义告警接收的对象 receivers: # 告警接收对象 - name: 'wechat' #告警接收名称,与route的receiver对应 wechat_configs: - corp_id: 'wwfaxxxxxxxxxxxx' # 企业微信唯一ID,我的企业--企业信息 to_party: '1' # 告警需要发送的组 to_user: '1' # 告警发送的用户ID agent_id: '1000002' # 自己创建应用的ID api_secret: 'o22cBPAm3xxxxxxxxxxxxxxxxxxx' # 应用密钥 send_resolved: true # 告警解决后是否发送通知 inhibit_rules: # 告警抑制规则,比如阈值告警,达到critical肯定也达到了warning了,没必要发送两个告警 - source_match: severity: 'major' target_match: severity: 'warning' equal: ['alertname', 'dev', 'instance'] templates: #告警消息模板 - '/usr/local/prometheus/alertmanager/*.tmpl'
配置完成之后有自带的工具用于检查文件里面的语法
[zhoujiangtao@root alertmanager]$ ./amtool check-config alertmanager.yml Checking 'alertmanager.yml' SUCCESS Found: - global config - route - 1 inhibit rules - 1 receivers - 1 templates SUCCESS
4、配置告警信息模板
注意:配置这些配置文件时,一定要是utf-8的形式,否则无法启动服务
- file filename # 查看文件属性
UTF-8 Unicode text
- set fileencoding=utf-8
ps: 模板的时间切记不要改,这个是go语言定义的一月二号下午三点四分五秒,06年时区是-7
{{ define "wechat.default.message" }}
{{- if gt (len .Alerts.Firing) 0 -}}
{{- range $index, $alert := .Alerts -}}
======== 异常告警 ========
告警名称:{{ $alert.Labels.alertname }}
告警级别:{{ $alert.Labels.severity }}
告警机器:{{ $alert.Labels.instance }} {{ $alert.Labels.device }}
告警详情:{{ $alert.Annotations.summary }}
告警时间:{{ $alert.StartsAt.Format "2006-01-02 15:04:05" }}
========== END ==========
{{- end }}
{{- end }}
{{- if gt (len .Alerts.Resolved) 0 -}}
{{- range $index, $alert := .Alerts -}}
======== 告警恢复 ========
告警名称:{{ $alert.Labels.alertname }}
告警级别:{{ $alert.Labels.severity }}
告警机器:{{ $alert.Labels.instance }}
告警详情:{{ $alert.Annotations.summary }}
告警时间:{{ $alert.StartsAt.Format "2006-01-02 15:04:05" }}
恢复时间:{{ $alert.EndsAt.Format "2006-01-02 15:04:05" }}
========== END ==========
{{- end }}
{{- end }}
{{- end }}
5、测试告警是否正常,首先编辑告警触发规则
groups:
- name: mem-rule
rules:
- alert: "内存报警"
expr: (node_memory_MemTotal_bytes - (node_memory_MemFree_bytes+node_memory_Buffers_bytes+node_memory_Cached_bytes )) / node_memory_MemTotal_bytes * 100 > 10
for: 30s
labels:
severity: warning
annotations:
summary: "服务名:{{$labels.alertname}} 内存报警"
description: "{{ $labels.alertname }} 内存资源利用率大于 10%"
value: "{{ $value }}"
- name: node-up
rules:
- alert: "节点状态"
expr: up{job="node-exporter"} == 0 #测试的话可以把节点改为1,不方便停止节点的时候
for: 5s
labels:
severity: ERROR
level: error
annotations:
summary: "{{ $labels.instance }} 已停止15s!"
description: "{{ $labels.instance }} 检测到异常!请重点关注!!!"
value: "{{ $value }}"
- name: node_health
rules:
- alert: HighMemoryUsage
expr: node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes > 0.9
for: 1m
labels:
severity: warning
annotations:
summary: High memory usage
- alert: HighDiskUsage
expr: node_filesystem_free_bytes{mountpoint='/'} / node_filesystem_size_bytes{mountpoint='/'} > 0.7
for: 1m
labels:
severity: major
annotations:
summary: High Disk usage
- alert: HighDiskUsage
expr: node_filesystem_free_bytes{mountpoint='/'} / node_filesystem_size_bytes{mountpoint='/'} > 0.71
for: 1m
labels:
severity: warning
annotations:
summary: High Disk usage
6、配置systemd对应服务,便于自启动和管理
[zhoujt@zhoujt rules]$ cat /usr/lib/systemd/system/alertmanager.service [Unit] Description=altermanager After=network.target [Service] ExecStart=/usr/local/prometheus/alertmanager/alertmanager --config.file=/usr/local/prometheus/alertmanager/alertmanager.yml ExecReload=/bin/kill -s HUP $MAINPID Restart=on-failure [Install] WantedBy=multi-user.target [zhoujt@zhoujt prometheus]$ cat /usr/lib/systemd/system/prometheus.service [Unit] Description=Prometheus Documentation=https://prometheus.io/ After=network.target [Service] # Type设置为notify时,服务会不断重启 Type=simple User=prometheus # --storage.tsdb.path是可选项,默认数据目录在运行目录的./data目录中
# --web.enable-lifecycle 用于重载Prometheus的,要么改下配置文件就要重启一下不是理想状态 ExecStart=/usr/local/prometheus/prometheus --config.file=/usr/local/prometheus/prometheus.yml --storage.tsdb.path=/home/prometheus/prometheus-data --web.enable-lifecycle #ExecStart=/usr/local/prometheus/prometheus --config.file=/usr/local/prometheus/prometheus.yml --storage.tsdb.path=/home/prometheus/prometheus-date --web.listen-address=:9099 Restart=on-failure [Install] WantedBy=multi-user.target
7、配置Prometheus的配置文件,使用alertmanager
# Alertmanager configuration #alerting: # alertmanagers: # - static_configs: # - targets: # - 127.0.0.1:9093 alerting: alertmanagers: - static_configs: - targets: ['localhost:9093']
8、基本配置已完成,开始启动服务,查看端口
- 重载Prometheus: curl -X POST http://localhost:9090/-/reload 或者: systemctl reload prometheus - 启动Alertmanager: systemctl enable alertmanager&& systemctl start alertmanager tcp6 0 0 :::9090 :::* LISTEN 11401/prometheus tcp6 0 0 :::9093 :::* LISTEN 30974/alertmanager tcp6 0 0 :::9094 :::* LISTEN 30974/alertmanager 访问 9090 9093 可以查看当前状态
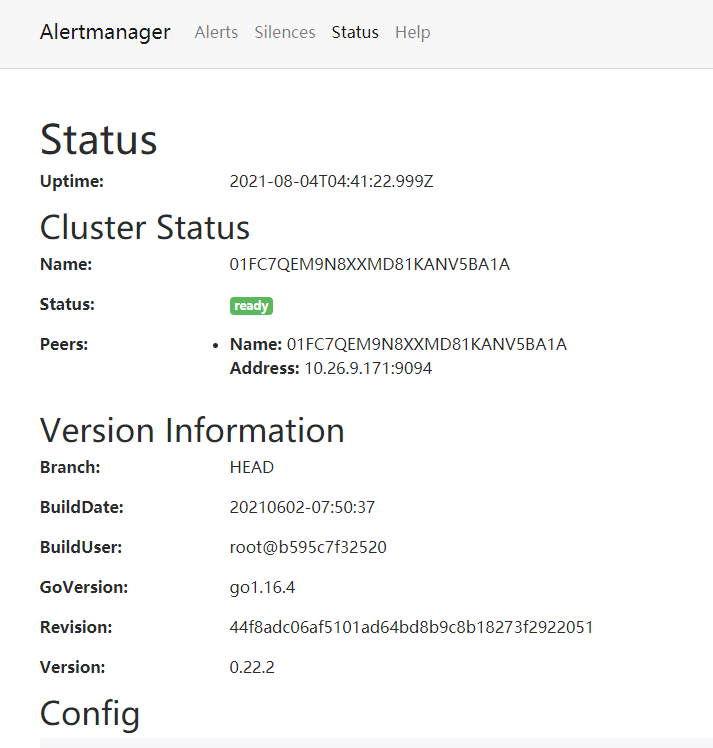
9、服务启动成功
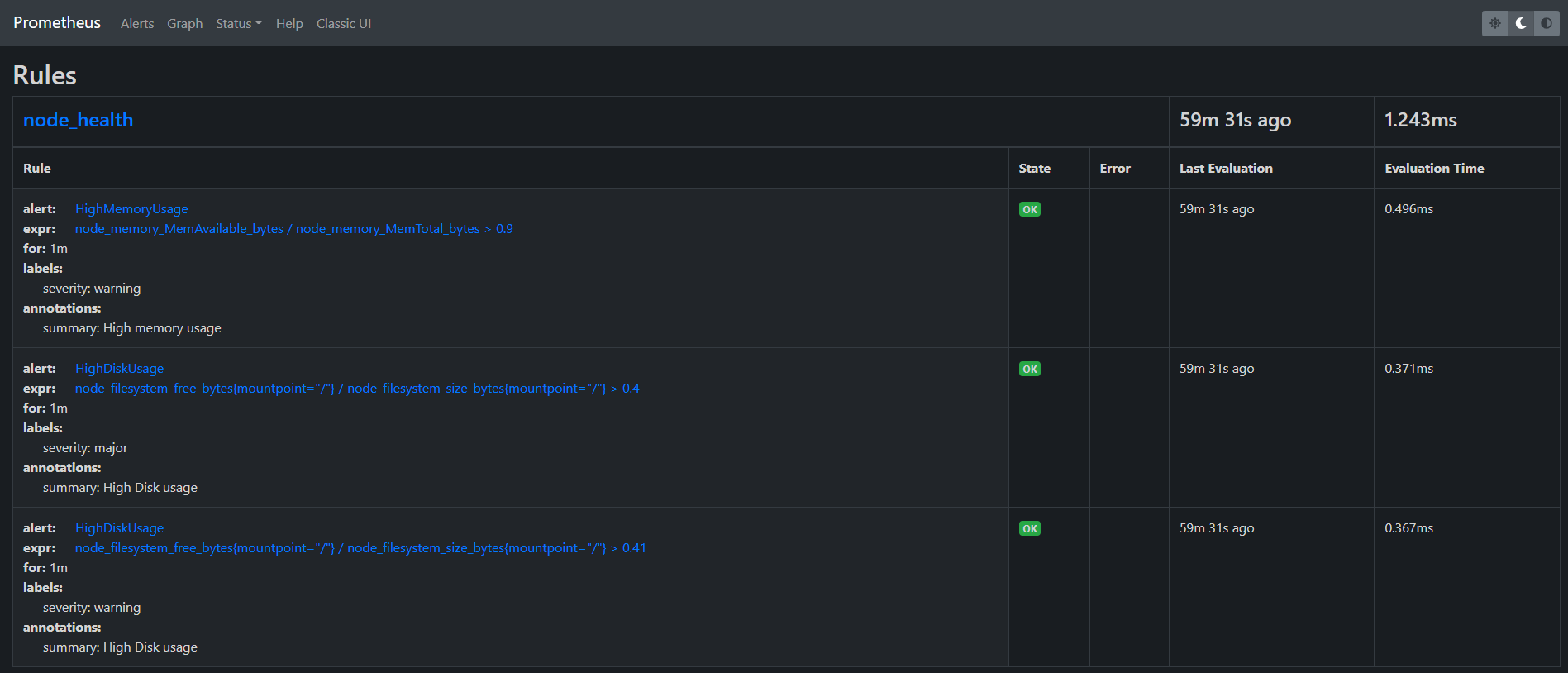
10、测试的话,将rule里面改几个参数,
告警时:
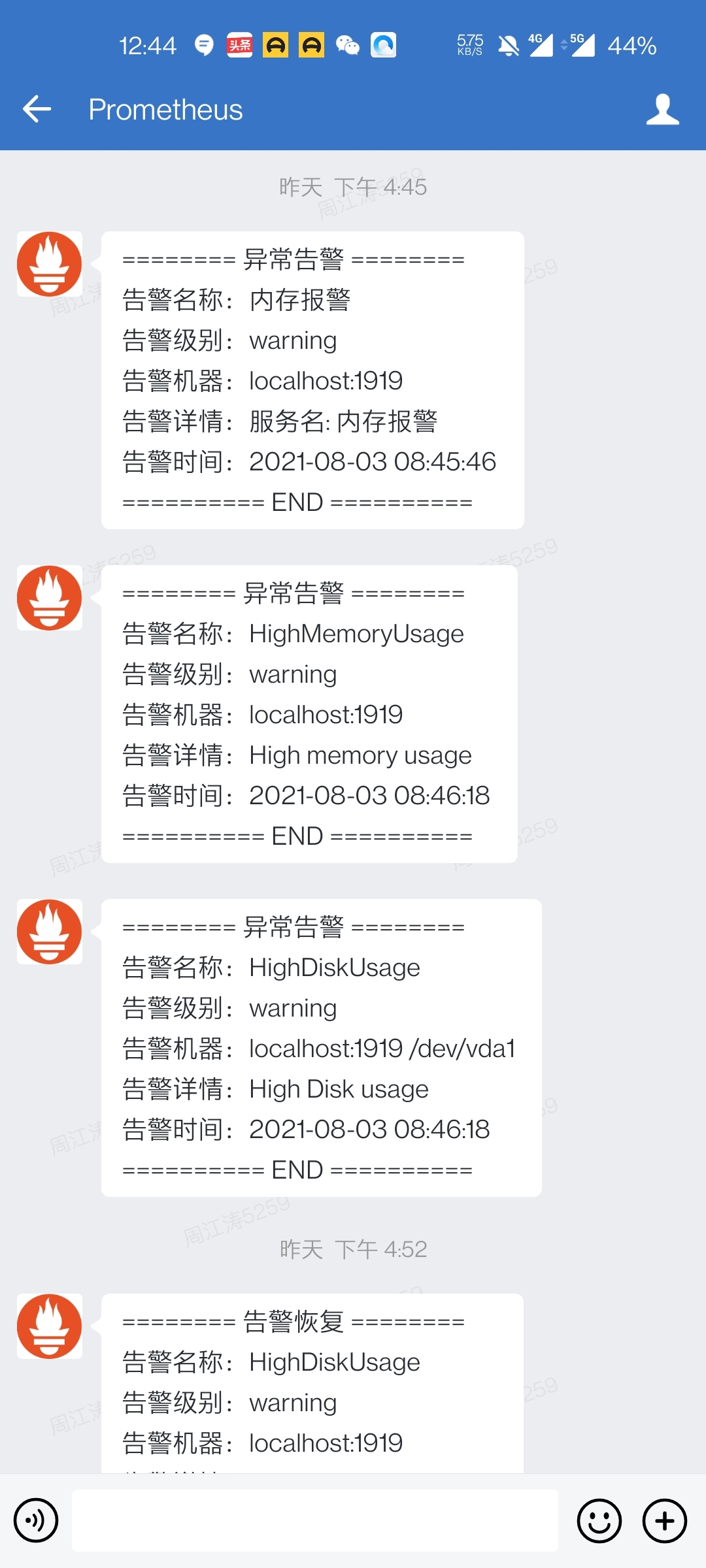
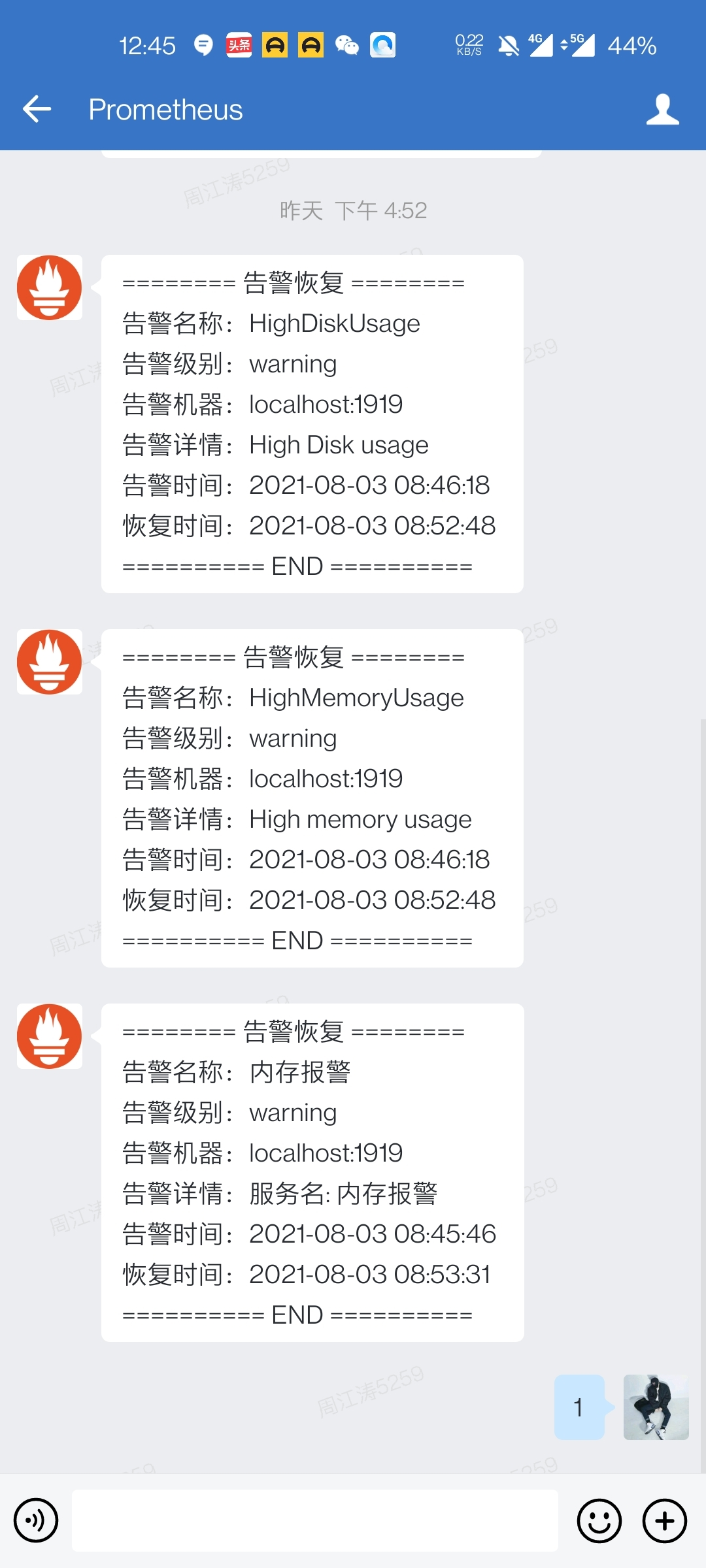
这里除了监控节点是否存活外,还可以监控很多很多指标,例如 CPU 负载告警、Mem 使用量告警、Disk 存储空间告警、Network 负载告警等等,这些都可以通过自定义 PromQL 表达式验证值来定义一些列的告警规则,来丰富日常工作中需要的各种告警
到这里,企微告警已完成,后续可以配置邮件告警,在配置文件中注释掉了