导语
扒房源数据进入线索模块,客户端(浏览器)接收数据,使用了异步消息推送设计。数据来源是搜索团队,他们通过爬虫,将数据抓取后,将数据粗略去重后扔到 Kafka 里,司南通过接入 Kafka,监听消息队列。数据抵达后,数据首先进行二次清洗,数据保存后,扔到 Redis 队列。各个服务器监听 Redis 队列,订阅消息。单机监听到消息后,将数据推送给客户端。
扒房源架构图
下图是扒房源的后端架构设计图,步骤如下:
- 将抓取到的数据保存到 mongoDB。抓取房365、58同城、赶集网的房源数据。使用 mongoDB 存储,是利用其特定自动判定房源是否更新,因为有的房源会不定时更新,而抓取程序是定时全量抓取,无法群分,利用 mongoDB 的更新则变更时间戳特性判定是否更新。
- 将 mongoDB 数据发布到 Kafka,增量更新。
- Kafka 集群将服务注册到 zookeeper 上。
- 司南服务器集群查阅 zookeeper 上的服务,找到指定 topic 下的 kafka 服务器 broker 列表。
- 司南服务器消费 Kafka 消息,不同服务器不会重复消费。
- 司南将获取到的消息进行去重处理,规则详见 jira,将符合条件的消息转为线索,持久化到 Mysql。
- 司南将持久化后的线索 publish 到 Redis 队列。
司南的服务器集群,监听 Redis 队列消息。每台服务器收到的消息都一模一样。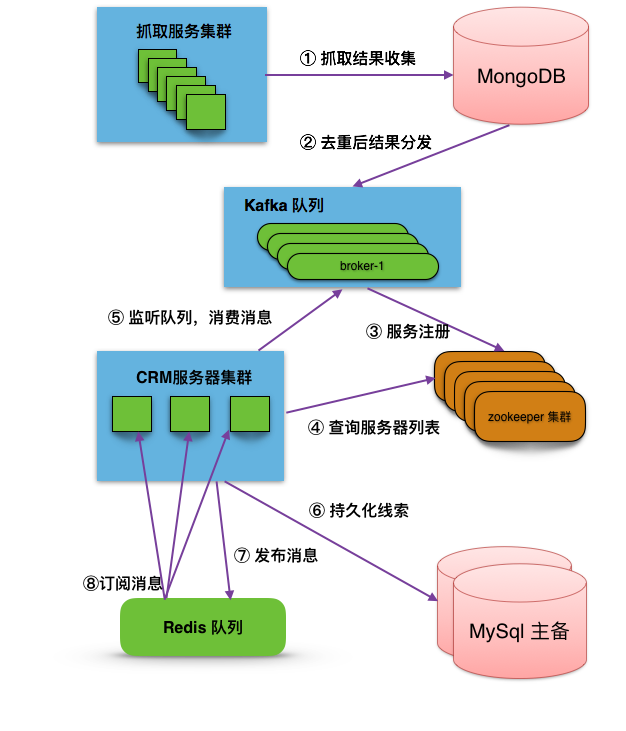
消息推送
继上面单台司南服务器接收到线索消息后,进行消息推送,其处理序列图如下。
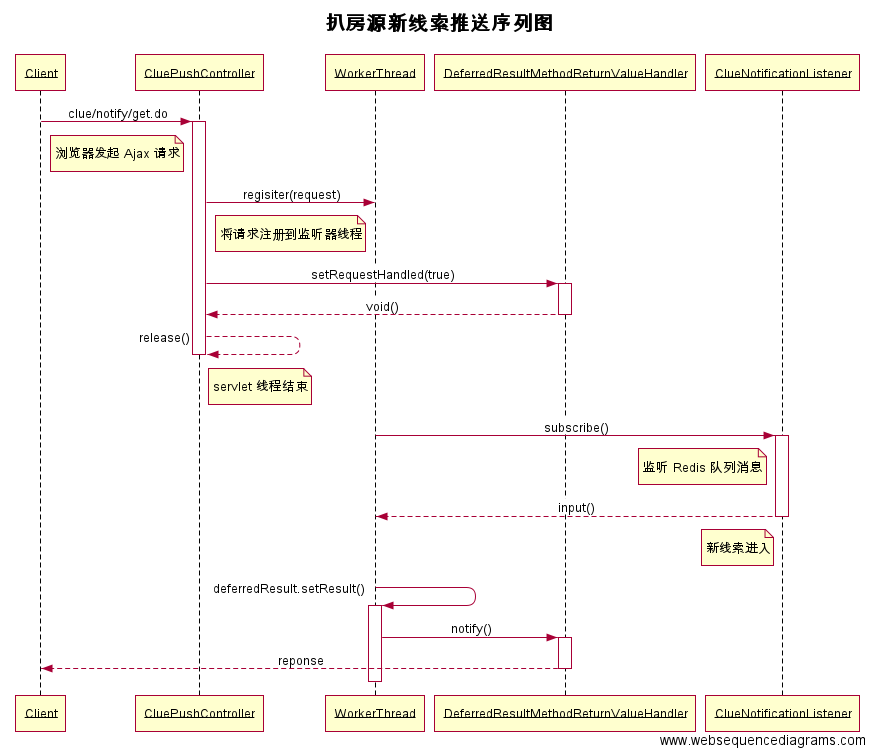
时间窗口设计
采用长连接的方式实现消息推送,涉及到几个时间点。
- request 超时设计。公司 nginx 代理服务,是 30 秒超时,因此一次长连接超时时间需小于 30 秒,项目中设置为 20 秒。
- Kafka 消息定时获取。需要配置 poller,目前设计是 10 毫秒推送一次,一次数据最多为 5 条,即最大处理能力为 500 MPS(messages per second)
- 消息推送最小时间间隔。司南 workerThread 监听到 redis 消息后,并不会遍历持有的 request Map 并返回。如果监听到消息立即返回,会造成在服务端抓取数据量很大时,客户端频繁调用服务端的问题。为解决这个问题,我给 workerThread 持有的每一个 request 分配一个计数器。计数器的功能是必须满足如下任一条件,request 才返回客户端:
- 计数器已经计数超过指定时间 minimalSyncTime,目前设置值为 10 秒。
- 计数器 count 值已经达到阈值 messageSize,目前设置为 250。
- Redis 消息监听目前未设置时间点,数据都是即时送达的。