本文主要通俗讲述WaveNet的基本模型和Keras代码理解,以帮助和我一样刚刚入坑并难以理解其代码的小白。
作者:SeanLiao
Blog:https://www.cnblogs.com/seanliao/
原创博文,转载请注明来源。
一. 什么是WaveNet?
简单来说,WaveNet是一种生成模型,类似VAE、GAN等,WaveNet最大的特点是可以直接生成raw audio的模型,由2017年DeepMind提出,在TTS(文字转语音)任务上可以达到state-of-art的效果。
此外WaveNet也可以用来做生成文字、生成图片、语音识别等。
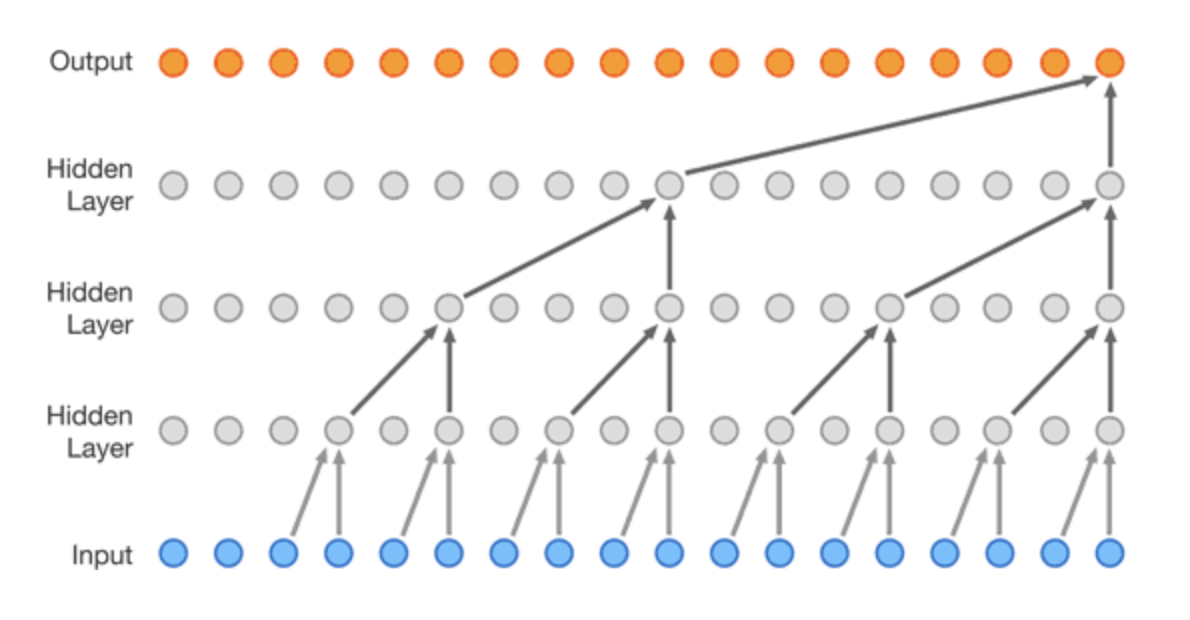
WaveNet的具体相关可以参考以下资料:
Ref :
窃以为,学习一种网络结构应该结合论文和代码,而理解模型的基础首先是知道模型的输入输出。但是这份代码最坑爹的地方是!没!有!注!释!
DeepMind博客上的动图非常清楚地展示了这个模型的工作过程。一定要看!体会!
WaveNet的网络结构并不复杂,说白了其实就是一类变种CNN。但是介绍WaveNet的各种文章只对WaveNet的结构夸夸其谈,丝毫没有涉及模型的输入输出到底是什么,对小白非常不友好。
本文着重介绍WaveNet keras实现代码中的输入数据组织。
二. 模型的运作过程
这里不谈模型的原理和结构(实际上只要理解了CNN,理解WaveNet非常容易)。我们先谈谈WaveNet到底“做了什么”?
由于我不知道怎么上传动图,大家可以到DeepMind博客上查看那张动图。再结合下图论文的原文:
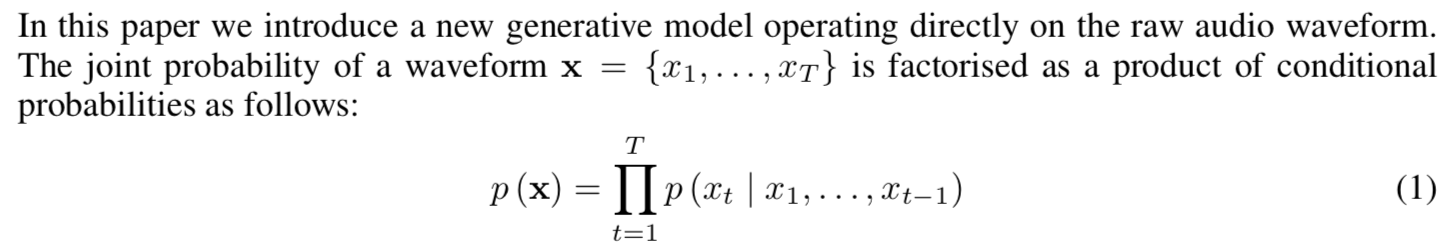
简单来说,模型的核心是 对给定的输入序列(x_1, x_2, x_3, x_4, ..., x_n) , 每次要根据之前的x_1 ~ x_n来预测x_n+1。然后将x_n+1添加在输入序列,再由x_2 ~ x_n+1得到 x_n+2。
由此 我们就可以由一个原始的序列(x_1, x_2, x_3, x_4, ..., x_n) 作为输入,按此模型进行构建,可以生成任意长度的序列!
那么疑问来了,代码怎么实现呢?博主实在讨厌冗长的Tensorflow代码,于是在github上找到了这个比较多Star的Keras版本代码,clone下来并成功运行后开始分析。
三. Keras代码中数据的组织
本文开头引用给出的Keras代码写得非常好,尤其是自定义层部分。由于封装得比较高级,对小白而言看懂还是有点困难的。下面我就拿其代码来进行简单的分析。
首先我们要注意到论文中的这部分。

这样的话,代码就应该很明白了。 还是不懂? 没关系,下面举个简单的例子。
对于一个序列 “我是超级大帅哥”。 假如取长度为2 步长为1 作为数据进行输入和训练。
则训练时第一次输入模型的数据:x1 = 我是 , 输出y1 = 是超
第二次:x2 = 是超, y2 = 超级;
第三次: x3 = 超级, y3 = 级大
……
而当训练完毕,使用训练好的模型生成数据时,送入x1 = 我是,理想情况是得到y1 = 是超
只要不断的将输出送到输入再进行预测,就有可能得到一个完整的序列“我是超级大帅哥”!
(别跟我你到这里还搞不懂模型的输入输出是什么......)
那么对于图片和文字的情况呢?这里不做讲解(因为我也还没去看啊喂...),大家可以看看论文原文和github上的tensorflow代码。
如果到这部分都看懂了,好的,其实代码实现也很容易理解,读者请先简单地阅读一遍所有代码,下面对输入输出数据的组织做简单的分析总结。
模型的输入
一段长度为fragment_length的音频数据, 设为audio[begin : begin + fragment_length]
模型的输出
相邻于输入数据的下一段fragment_length长的音频序列。步长为fragment_stride,输出为audio[ begin + fragment_stride : begin + fragment_stride + fragment_length ]
输入数据的处理
1. 对单个音频的处理有:
a) 读取音频。
b) 声道处理(原代码为单声道音频)。
c) 转化为浮点数(这里应该是进行了一个缩放到0~1之间),代码如下:
1 def wav_to_float(x): 2 try: 3 max_value = np.iinfo(x.dtype).max 4 min_value = np.iinfo(x.dtype).min 5 except: 6 max_value = np.finfo(x.dtype).max 7 min_value = np.iinfo(x.dtype).min 8 x = x.astype('float64', casting='safe') 9 x -= min_value 10 x /= ((max_value - min_value) / 2.) 11 x -= 1. 12 return x
d) 转化为ulaw编码,使用ulaw编码的原因是原始音频数据是16bit的,则生成的时候一个帧音频有2^16个输出值(输出节点数),再进行softmax取值,这样的话代价高昂而且数据点取值范围太大会影响准确率。所以对原始的音频数据进行了ulaw编码(可参考:https://blog.csdn.net/wzying25/article/details/79398055)
e) resample到目标采样率。
f) 转化为uint8数据, 代码如下:
1 def float_to_uint8(x): 2 x += 1. 3 x /= 2. 4 uint8_max_value = np.iinfo('uint8').max 5 x *= uint8_max_value 6 x = x.astype('uint8') 7 return x
单个音频处理的完整代码如下:
1 def process_wav(desired_sample_rate, filename, use_ulaw): 2 # print('reading wavfile...',filename) 3 with warnings.catch_warnings(): 4 # warnings.simplefilter("error") # 提升警告等级?会导致np.fromstring报错 5 channels = scipy.io.wavfile.read(filename) 6 file_sample_rate, audio = channels 7 audio = ensure_mono(audio) 8 audio = wav_to_float(audio) 9 if use_ulaw: 10 audio = ulaw(audio) 11 audio = ensure_sample_rate(desired_sample_rate, file_sample_rate, audio) 12 audio = float_to_uint8(audio) 13 return audio
2. 组织成模型的输入数据
a) 将同一个说话人的音频经过1中的处理后进行拼接,形成一个full_sequences。
b) 划分测试集,代码中将full_sequences按9 : 1进行切分,后0.1部分加入测试集。
c) 对full_sequences,以fragment_stride进行分割,长度为fragment_length(这里只记录序列开始的坐标。得到若干个音频子序列。代码如下:
1 def fragment_indices(full_sequences, fragment_length, batch_size, fragment_stride, nb_output_bins): 2 for seq_i, sequence in enumerate(full_sequences): 3 for i in range(0, sequence.shape[0] - fragment_length, fragment_stride): 4 yield seq_i, i 5 # i为input sequence的起点 seq_i为音频文件的id
d) 生成batch。由c得到一个full_sequence的全部子序列列表。然后按batch_size进行划分。
batches = cycle(partition_all(batch_size, indices)) # indices为列表 for batch in batches: if len(batch) < batch_size: continue yield np.array( [one_hot(full_sequences[e[0]][e[1]:e[1] + fragment_length]) for e in batch], dtype='uint8'), np.array( [one_hot(full_sequences[e[0]][e[1] + 1:e[1] + fragment_length + 1]) for e in batch], dtype='uint8')
e) 此时数据点的取值为0~255,转换为onehot编码,则输入数据变成了一个二维张量,此时喂入模型即可。相邻的两个子序列前者为输入,后者为输出。
model的定义和原理待续。
还有一个简单的实现Keras WaveNet Demo正在赶工……完成后会附上
实际上,用代码实现模型最头疼的部分就是输入数据的组织,本文以上已经介绍完毕。对于Keras而言已经把网络结构搭建简化得非常容易了。只要理解了模型的原理,实现起来就很容易了。