1. 如何判定是否需要创建索引
- 较频繁的作为查询条件的字段应该创建索引
- 唯一性 太差的字段不适合单独创建索引,即使频繁作为查询条件
- 更新非常频繁的字段不适合创建索引
- 不会出现在where子句中的字段不该创建索引
2.单键索引还是组合索引
我们创建组合索引并不是说需要将查询条件中的所有字段都放在一个索引中,还应该尽量让一个索引被多个query语句所利用,尽量减少同一个表上面索引的数量,减少因为数据更新所带来的索引更新成本,同时还可以减少因为索引所消耗的存储空间。
- 对于单键索引,尽量选择针对当前query过滤性更好的索引
- 在选择组合索引的时候,当前query中过滤性最好的字段在索引字段顺序中排列越靠前越好
- 在选择组合索引的时候,尽量选择可以能够包含当前query的where子句中更多字段的索引
- 尽可能通过分析统计信息和调整query的写法来达到选择合适索引的目的而减少通过使用Hint人为控制索引的选择,因为这会使后期的维护成本增加,同时增加维护带来的潜在风险
3. Mysql总索引的限制
在使用索引的同时,我们还应该了解在mysql中索引存在的限制,以便在索引应用中尽可能地避开限制所带来的问题
- MyISAM存储引擎索引键长度总和不能超过1000字节
- MBLOB和Text类型的列只能创建前缀索引
- Mysql目前不支持函数索引
- 使用不等于(!或<>)的使用mysql无法使用索引
- 过滤条件使用了函数运算后(如abs(column)),mysql无法使用索引
- join语句中join条件字段类型不一致的时候,mysql无法使用索引
- 使用like操作的时候如果条件以通配符‘%’开始,mysql无法使用索引
- 使用非等值查询的时候,mysql无法使用hash索引
4. Mysql Explain功能中展示的各种信息的解释
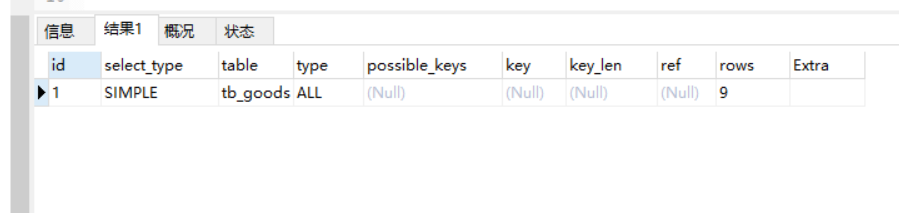
- ID:query Optimizer所选定的执行计划中查询的序列号
- select_type:所使用的查询类型,主要有以下几种查询类型
- dependent subquery:子查询中内层的第一个select,依赖于外部查询的结果集
- dependent union: 子查询中的union,且为union中从第二个select开始的后面所有select,同样依赖于外部查询的结果
- primary:子查询中最外层查询,注意并不是主键查询
- simple: 子查询或union之外的其他查询
- subqyery:子查询内层查询的第一个select,结果不依赖于外部查询结果集
- uncacheable subquery结果集无法缓存的子查询
- union:union语句中第二个select开始的后面所有select,第一个select为primary
- union result:union中的合并结果
- table:显示这一步所访问的数据库中的表的名称
- Type:告诉我们对表所使用的访问方式
- all:全表扫描
- const:读常量,且最多只会有一个条记录匹配,由于是常量,所以实际上只需要读一次
- eq_ref:最多只会有一条匹配结果,一般是通过主键或唯一键索引来访问
- index:全索引扫描
- Possible_keys:该查询可以利用的索引,如果没有如何索引可以使用,就会显示null,这一项内容对于优化时候索引的调整非常的重要
- key:mysql query optimizer从possible_keys中所选择使用的索引
- key_len:被选择索引的索引键长度
- ref:列出通过常量(const)还是某个表的某个字段来过滤的
- rows:mysql query optimizer通过系统收集到的统计信息估算出来的结果集记录条数
- extra:查询中每一步实现的额外细节信息
5. query语句优化基本思路和原则
- 优化更需要优化的query
- 定位优化对象的性能瓶颈
- 明确优化目标
- 从explain入手
- 多使用profile
- 永远用小结果集驱动大的结果集
- 尽可能在索引中完成排序
- 只取出自己需要的columns
- 仅仅使用最有效的过滤条件
- 尽可能避免复杂的join和子查询
1. 明确优化目标
在拿到一条需要优化的query后,我们首先需要判断出这个Query的瓶颈到底是IO还是CPU,到底是因为数据访问消耗太多的时间还是在数据的运算(如分组排序等)方面花费了太多的资源。
在mysql5.0和mysql5.1正式版中已经非常容易做到,那就是通过Query profile功能。
mysql --> set profiling=1;//开启Query profile功能
mysql --> select * from test_table order by name;//开启Query profile功能之后,Mysql就会自动记录所有执行的query的profile信息咯。
mysql --> show profiles;//显示profile概要信息;
mysql -->show profile cpu, block io for query 6;//获取单个query详细的profile信息
上面的例子中是获取 CPU 和 Block IO 的消耗,非常清晰,对于定位性能瓶颈非常适用。
2.如何设定优化目标
一般来说,我们首先需要清楚的了解数据库目前的整体状态(数据库所能承受的最大压力,能够接受的最悲观的情况),同时也要清楚的知道数据库中与该query相关的数据库对象的各种信息
(最理想状况下需要消耗多少资源,最糟糕又需要消耗多少资源),而且还要了解该query在整个应用系统中所实现的功能(可以大概分析该query可以占用的系统资源比例,
该query的效率给客户带来的体验影响到底又多大)。