第一部分有四篇文章,略微有些多
《Supervised Neural Networks for the Classification of Structures》
《Graphical-Based Learning Environments for Pattern Recognition》
《Graph Neural Networks for Ranking Pages》
《Neural Network for Graphs: A Contextual Constructive Approach》
点击右下角的目录按钮可以选择想要看的文章
如果有疑问欢迎和我交流 QQ:1181852700
《Supervised Neural Networks for the Classification of Structures》
文中有一些概念性的东西,先做一个声明:
valence:翻译过来是化合价,在文中作者定义为图中node的出度的最大值
supersource:直译是超级源节点,DAG可以转换为树模型,root节点就是这个supersource,而如果图中带环,导致没有root,可以自己手动加一个(我的理解是这样的)
图的数据结构在现实中应用广泛,最直观的就是化学分子式的描述了,几条杠杠,几个点点,不就恰好是图的形状嘛。
作者回顾了一下之前将图这种数据机构应用于神经网络的输入的范式,如下图所示
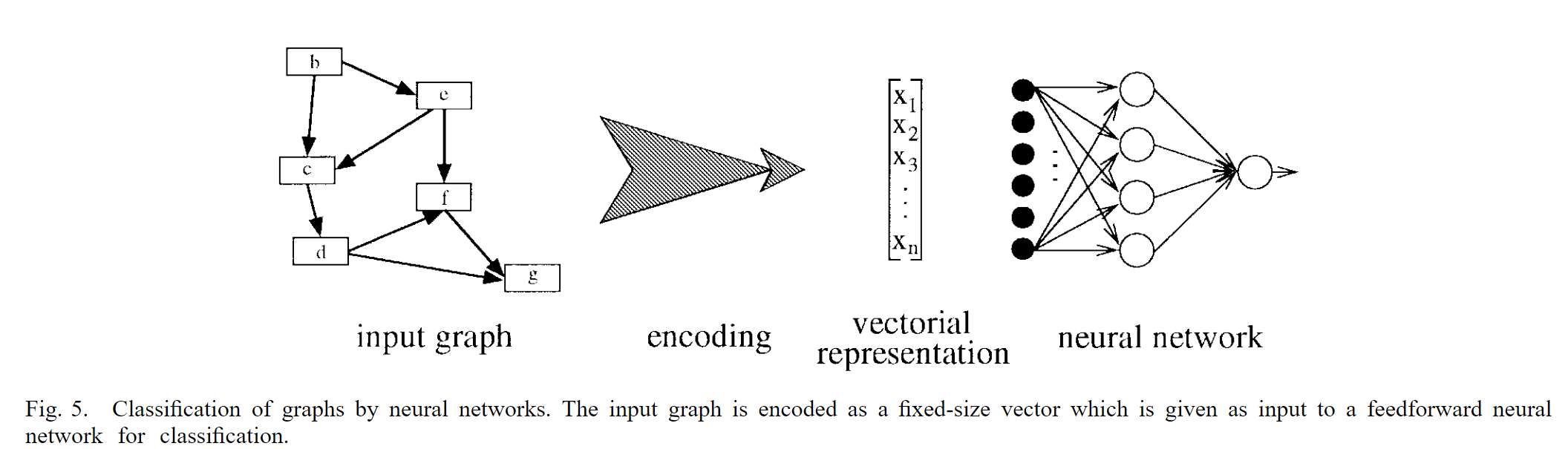
main idea就是将图通过encoding映射为一个向量表示,然后输入传统的神经网络继续进行其它的任务
Attention:这里的encoding应该算是人工encoding,而不是去学习一个embedding,所以对应着下面的两个缺点
然而这种方式存在着两个缺点(作者的观点):
- 从不同任务角度看,图中不同特征的相关性会由于不同的学习任务而发生巨大的改变
- 从单任务(以分类任务为例)角度看,由于编码的过程必须能够适用于任意的分类任务,为了应对不同的分类任务,每张图都会得到一个不同的表示,这可能会导致神经网络难以对其进行分类
为了改进以上的两个缺点,作者就想让神经网络去学习这个encoding的过程,提出了叫做Generalized Recursive Neuron的神经元
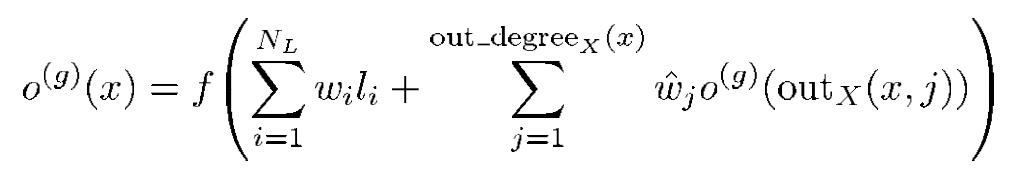
符号说明:
x表示当前节点,o(g)(x)表示神经元输出(至于为什么有一个g就不知道了graph的意思?),NL表示node x的标签label的维度,因此第一个求和符号相当于RNN中的对输入做一个Embedding
out_degreeX(x)表示的是在图X上的点x(注意大小写)对应的“出度“,outX(x,j)表示的是出去的边连接的第j个点,wj表示的是不同节点的连接权值,和RNN中的概念很相似,比照一下很容易理解的,顺便放一张RNN中neuron的计算公式
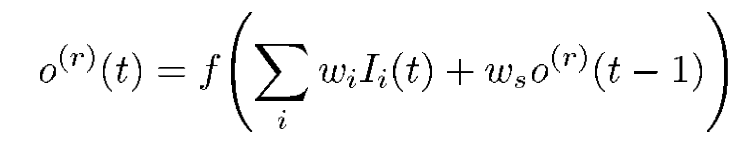
在来一张图对比RNN和作者提出的Generalized Recursive Neuron对比,更好理解作者的思想
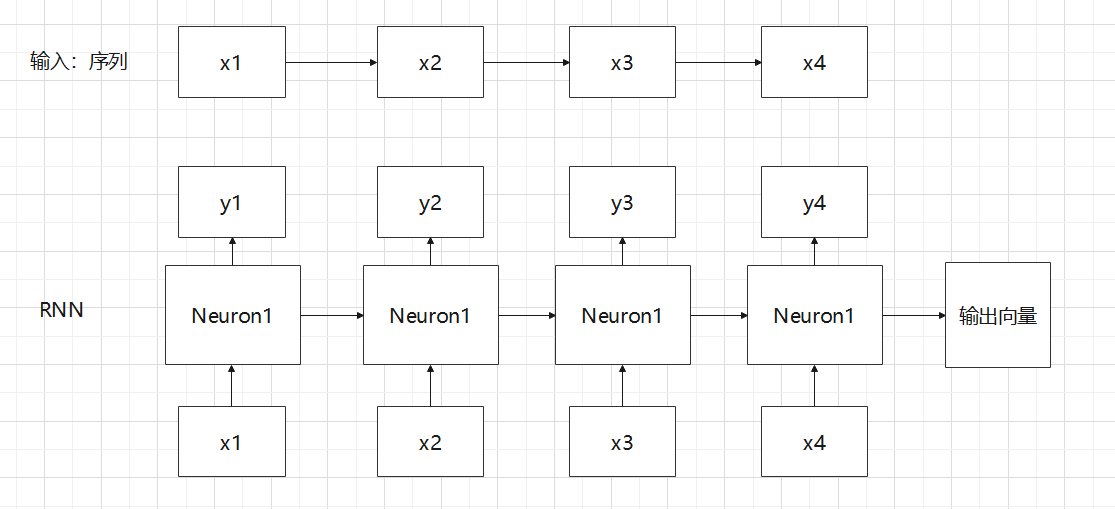
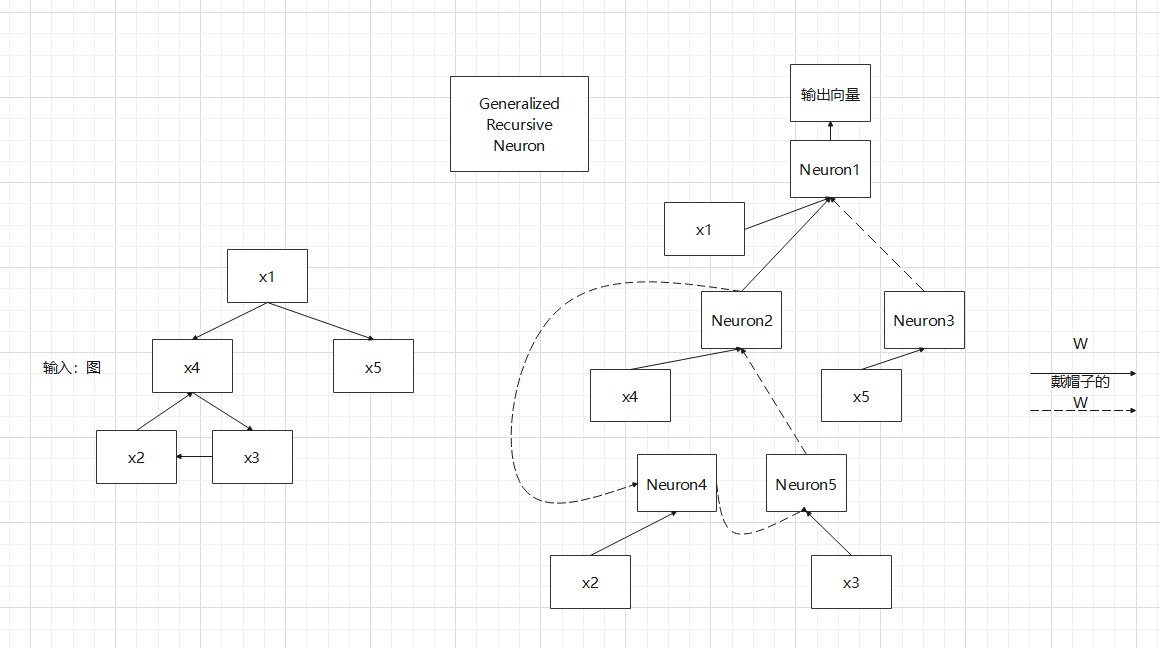
可以很明显看出来,作者将序列和图都用了差不多的方式输入神经网络,就像时间步一样一步一步输入网络的不同神经元,而不是将图作为一个整体结构输入
《Graphical-Based Learning Environments for Pattern Recognition》
根据图结构的应用层级,作者将其分为了两类:
- 关注整幅图的应用。以图片为例,一幅图可以表示为RAG(Region Adjacency Graph区域邻接图),在做分类任务的时候关心的是整张图的类别,比如这是一张阿猫还是阿狗的照片,而不会去考虑图中还有什么其它的零碎东西
- 关注node的应用。还是以图片为例,这个层级的应用最有代表性的就是目标检测和定位,要分析图片中是否存在某个物体,并将它定位出来,很明显需要每个节点的信息。
在关注整幅图的应用模型中,使用的方法是RNN编码,而关注node的应用模型中,使用的方法是随机游走技术。
然后作者总结了一下当下的图神经网络的主要缺点——它们几乎都是想要把图结构编码成一个实数向量,作者认为这会丢失每个图中每个节点的连接信息,这一步通常被称为squashing操作,对于图来说,优势就在于利用这些连接信息,可以更直观表示各个节点的关系,现在你给我整没了,我自然可以认为这样子会造成信息损耗,导致模型精度下降。
因此,自然而然地,作者提出了GNN,这是一个能够在关注graph和node灵活切换地模型,这篇应该就是后面的GNN的开山鼻祖了吧
在引入模型之前,作者引入了一条核心定理:不动点定理
一个有点反直觉的例子:取两张一样大小的白纸,在上面画好垂直的坐标系以及纵横的方格。将一张纸平铺在桌面,而另外一张随意揉成一个形状(但不能撕裂),放在第一张白纸之上,不超出第一张的边界。那么第二张纸上一定有一点正好就在第一张纸的对应点的正上方
公式表达:\(f可微并且存在一个数0<e<1,使得f(x)对x的导数的1-范数小于等于e,那么f就是一个压缩函数,f(x)=x存在唯一解\)
作者引入这个定理意图是什么?先看下面的计算公式
\(x_n = F_w (x_n, L_n, x_{ne[n]}, L_{co[n]}, L_{ne[n]}), 1 ≤n ≤r\)
xn代表了图中节点的状态,Ln代表了图中节点的标签,理解为特征可能更好;Lco表示边的标签,xne表示邻居节点,Lne表示邻居节点的标签,r表示图中节点的数量(原文中的公式里i和r这些下标很不明确,只能靠理解,我就不放上来了)
结合不动点定理的方程可以看出来,作者想要通过一步步的迭代,使得最后的xn收敛在某一个稳定的状态,然后再通过这个状态xn与自身的标签Ln获取输出on
\(o_n = O_w (x_n, L_n), 1 ≤n ≤r\)
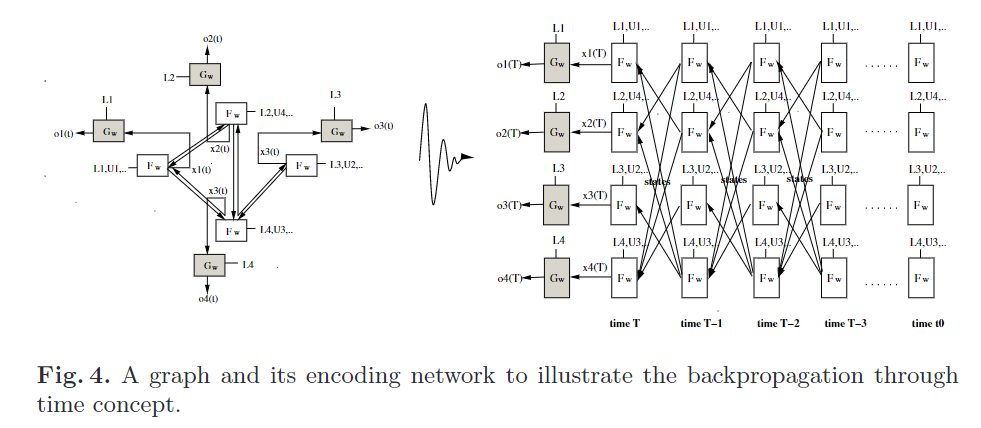
迭代的过程可以用上图表示,和RNN十分相似,为了更好表示这个迭代的过程,上面的状态方程更改为和时间相关的形式
\(x_n(t) = F_w (x_n(t −1), L_n, x_{ne[n]}(t −1), L_{co[n]}, L_{ne[n]})\)

为了满足不动点定理的要求,采用上述算法进行前向和反向传播
一点看完肯定会有的疑问:凭什么你能够保证forward的时候不跑飞?这个是涉及Fw参数的核心问题,作者肯定考虑到了,他证明在网络后面加Sigmoid激活函数的时候是能够保证存在不动点的,具体证明过程就不详细讲了,因为看不懂哈哈哈哈哈,而且,为了确保,作者还加了一层保险——惩罚项
最后,最为结尾,引用一段来自知乎的理解
GNN模型可以使用热扩散的原理去理解它。例如,在 \(t_0\)时刻,传递给图中某些结点一些热量,使得这些结点的温度升高,这些结点会通过相连的边向相邻的结点传导热量。因此,下一个时刻,某个结点的热量的流入为相邻结点传递热量的累加和。随着时间的推移,每个结点的热量流入会达到一个稳定状态。GNN最大的特点是存在一个稳定状态,因此 \(f_w\)需要满足固定点的理论。后面一些图网络,不需要满足这一条件,例如GCN,GGNN。
《Graph Neural Networks for Ranking Pages》
这篇文章和上面的GNN部分作者是相同的,是GNN在Page Rank的应用,算是模型的一种延续吧
直接来到实验部分
首先要处理的第一个问题是,有监督学习的GNN的target怎么获取?
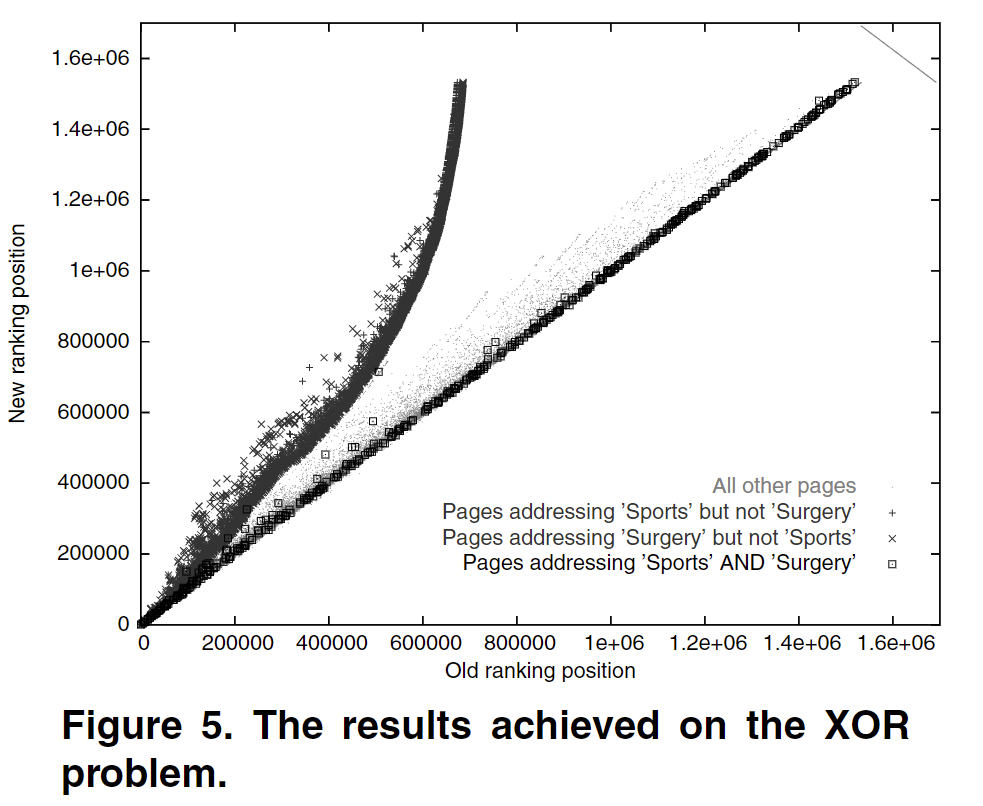
作者的做法很简单,直接将Google Page Rank算法得到的排名作为target,然后交给GNN去学习。然而,搜索的时候往往会有一个关键词,作者将带有关键词的页面所得到的target提升了一倍,用来表示它的重要性,得到了下面的结果。横轴表示PageRank算法得到的position,纵轴表示GNN得到的position。
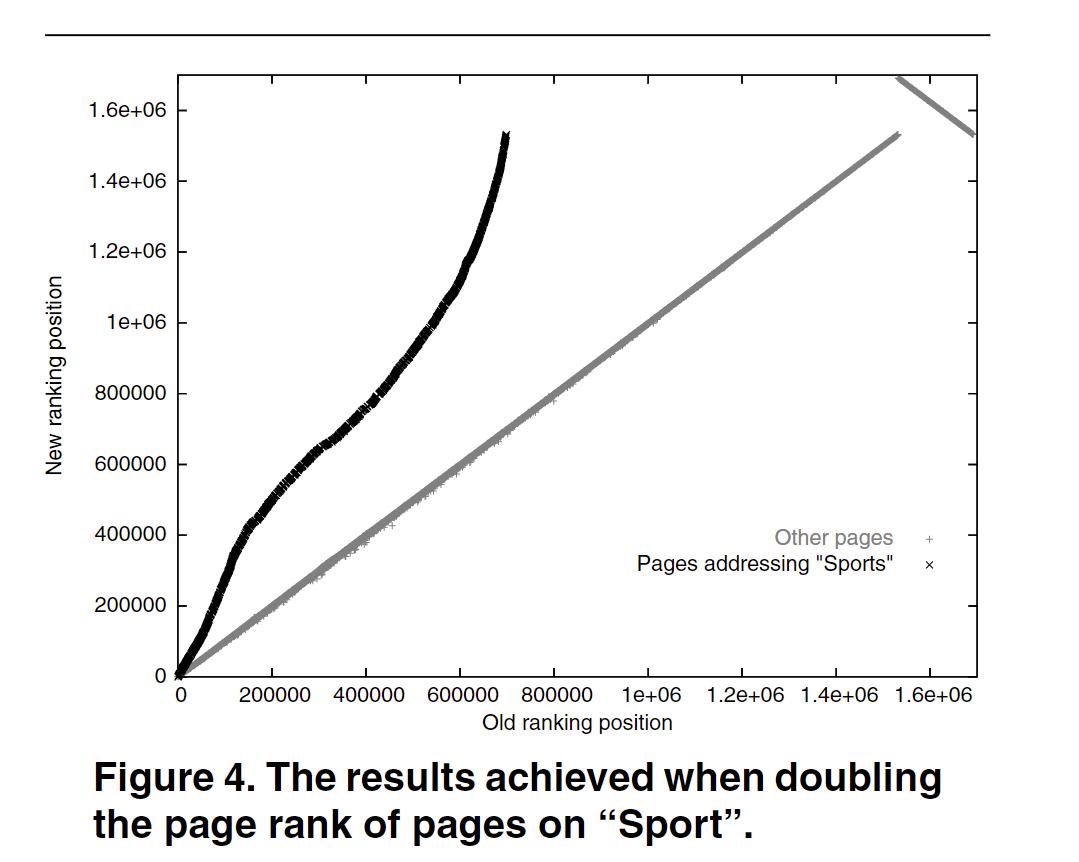
从上图可以看到,在重点强调Sports的时候,GNN的到的Sports的页面排名相较于PageRank算法得到排名要更高(图中的position有点混淆我们的理解,我认为此处作者意思就是position越高重要性高)
其次,如何应对需求是多个Topic的情况呢?
作者还是从target的赋值入手。将具有topic1或者topic2的网页的得分加倍,两者都有的网页则保持不变(这一步的做法作者可能考虑的是如果两个都有的话,这个网页是一个导航或者综合网页,类似于维基百科?反正就是,成为目标网页的概率不大),其它网页也保持不变
最后,page rank最终是要为用户服务的,他们并不能总是明确指出topic是什么,有时候只能模糊说个大概,因此也就难以像前面两种方法一样精准地对某种target进行加倍。作者的做法是——让用户提供一类样本,用户主动标记喜欢哪一类网页,不喜欢哪一类网页,从而获得用户的偏好。我们将用户喜欢的网页记为n,不喜欢的网页记为u,一种比较符合直觉的做法就是使得GNN的输出on要比ou大就行,于此同时,不要忘了我们的GNN也要符合另一个条件——输出的值和Page Rank出来的值要比较接近,将上述条件综合起来,得出下面的损失函数
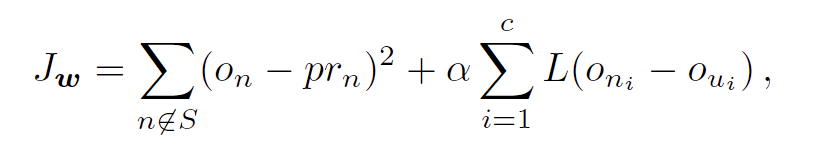
其中L是衡量on和ou差别的函数,类似于\(L(y)=y^2\),if $y < 0 $ and \(L(y) = 0\)
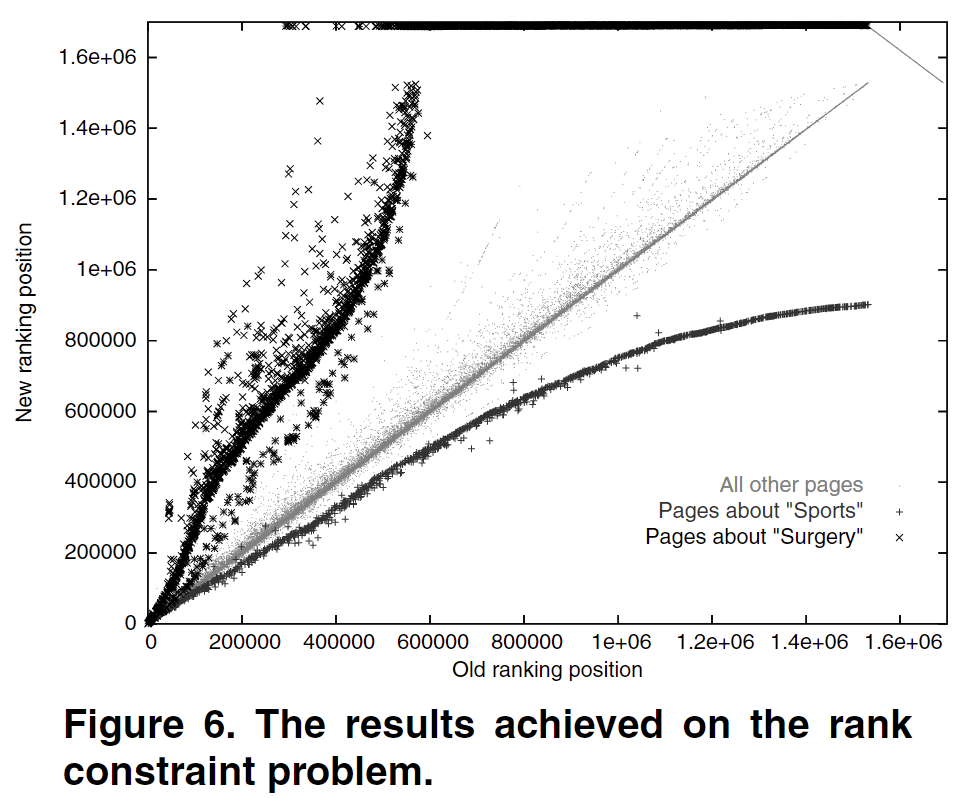
可以很明显看出来,我们想要sports的内容不想要surgery的内容时,这两类的position被很好地拉开了差距,做到了比较好的效果
一些小小的补充:作者提到了有时候模型会跑出来一些表现很差的案例,作者认为这是由于神经网络收敛到了局部最小值导致的,要通过重新设置初始化和重新训练来解决
《Neural Network for Graphs: A Contextual Constructive Approach》
写在前面
这篇文章有很多的专有名词,比如说subsymbolic,百度找不到解释,只能翻译成亚符号,再比如说提及的DPAG,叫做有向带position的无环图,同理,百度找不到,我姑且认为他和DAG差不多;还有后面的causality assumption 因果假设,看到这个第一反应是???我选错论文看了?后面才发现原来是将RNN换了一种高级的说法。。
尽管有这么多晦涩难懂的名词,模型和方法还是能够很简单理解的。
本文的开端作者直指当时处理图数据结构的神经网络存在的问题:
基本架构是RNN(Recursive和Recurrent是不同的,这里时Recursive,循环迭代的意思),输出依赖上一个时间步的输出,即
\(x(t)=f(x(t-1))\)的形式——作者将这种情况称为因果假设(causality assumption 我的理解是上一个时间点的输出认为是原因,当前时间点的输出认为是结果),然后根据图中箭头的走向逆向回去,在supersource处(上一篇论文中有提到,类似于tree的root概念)汇聚成一个整幅图的向量表示。以上做法作者认为,不适用于那些无向图(文中说是 tasks requiring contextual information, e.g., considering both possible directions in sequences or considering the neighborhood of each vertex in a structure,我寻思这不就是无向图嘛,无向图可以看作是双向的有向图啊),因为需要考虑graph的整体信息,上述方法只能得到每个点之间的流转信息,没能有一个纵观全局的信息表示。
为了避免陷入为了获得稳定的节点状态xn而陷入迭代,使得速度变慢,作者干脆把节点的状态计算交给了MLP去学习,避免了相互引用而陷入复杂的计算;同时为了能够获得图的整体信息,作者在堆叠几个Hidden Unit之后,把输出交给了Output Unit,用取平均或者求和的方式代表获得了整体信息。
经过第一个unit获得的状态的公式如下图所示,其中L表示label的维度
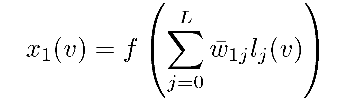
往上堆叠的unit的计算公式,其中i表示第i个unit,u表示v的邻居节点
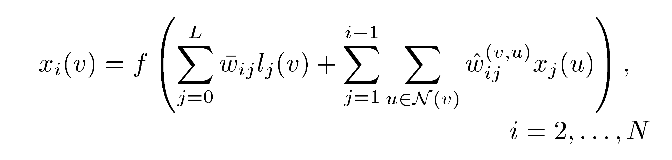
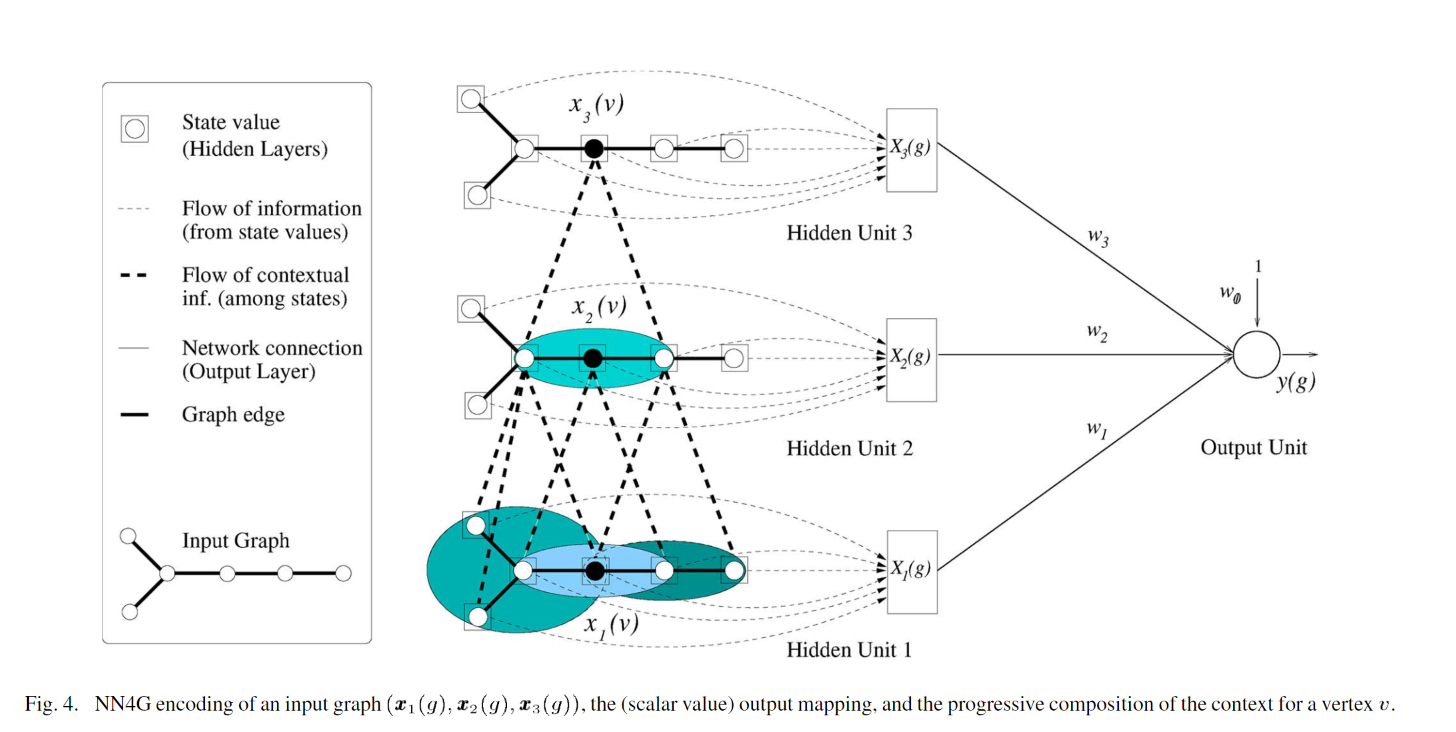
我相信,上图已经很明了告诉了我们计算的过程,就不赘述了。从此开始,作者摆脱了时间步的约束,以一种简洁的架构处理了图数据,但是也留下了一份遗憾,没有把edge的信息利用起来(文章中几乎没有提到利用边的信息,估计是当时处理起来比较棘手吧,没什么好方法哈哈哈)