每周一个机器学习小项目005-自动求导
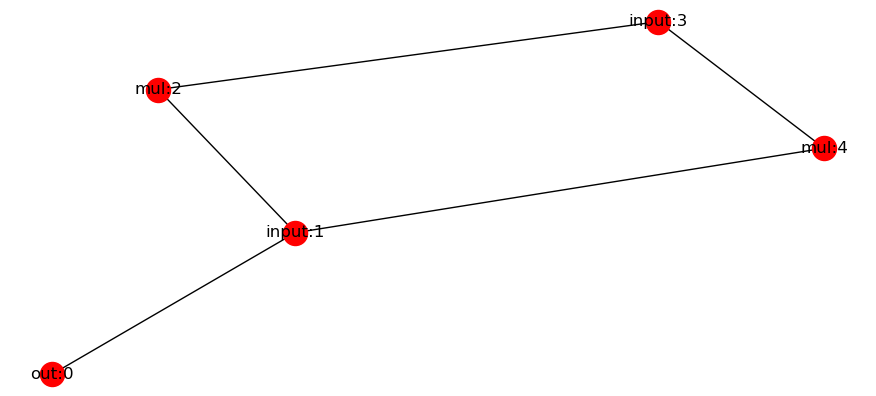
深度学习中实现一个自动求导实际上就是实现一个图算法。我们以一个简单的示例来说:
将上的关系绘制成图
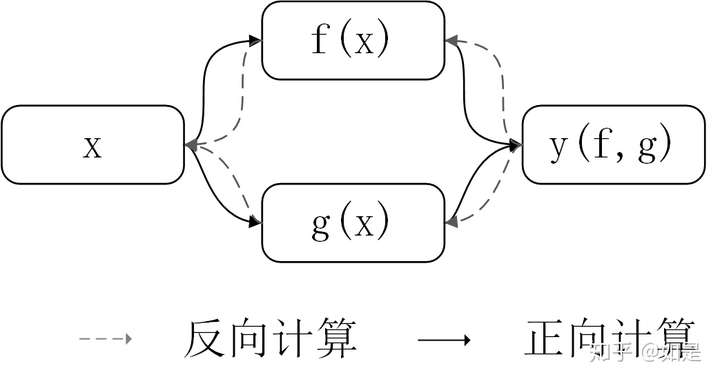
我们可以将所有的计算拆分为二元的计算方法:
对于每一步而言仅需计算其依赖的输入的偏导数即可(对于y来说是f和g)。之后递归的向前计算每一层的导数。因此在计算的过程中需要实现的类的功能为记录计算过程中的依赖的输入。 以一个仅有加法的示例来说,我们定义公式为:
我们在定义个Tensor类后需要完成导数的计算。
class Tensor:
def __init__(self, data, depend=[]):
"""初始化"""
self.data = data
self.depend = depend
self.grad = 0
def __mul__(self, data):
"""乘法"""
def grad_fn1(grad):
return grad * data.data
def grad_fn2(grad):
return grad * self.data
depend = [(self, grad_fn1), (data, grad_fn2)]
new = Tensor(self.data * data.data, depend)
return new
def __rmul__(self, data):
def grad_fn1(grad):
return grad * data.data
def grad_fn2(grad):
return grad * self.data
depend = [(self, grad_fn1), (data, grad_fn2)]
new = Tensor(self.data * data.data, depend)
return new
def __add__(self, data):
"""加法"""
def grad_fn(grad):
return grad
depend = [(self, grad_fn), (data, grad_fn)]
new = Tensor(self.data * data.data, depend)
return new
def __radd__(self, data):
def grad_fn(grad):
return grad
depend = [(self, grad_fn), (data, grad_fn)]
new = Tensor(self.data * data.data, depend)
return new
def __repr__(self):
return f"Tensor:{self.data}"
def backward(self,