容错设计又叫弹力设计,其中着眼于分布式系统的各种“容忍”能力,包括容错能力(服务隔离、异步调用、请求幂等性)、可伸缩性(有 / 无状态的服务)、一致性(补偿事务、重试)、应对大流量的能力(熔断、降级)。可以看到,在确保系统正确性的前提下,系统的可用性是弹力设计保障的重点(无论是调用别人还是被别人调用都最大限度维持可用)。
举例:如果你是一个支行的行长如何应对如下情况:客流暴增,营业员请假,总行的系统挂
一个服务的抽象:生产者+消费者+队列(银行)

提高性能加快处理:

代码层面(打比方就是业务员练内功)http://t.cn/RuRPFMn
高并发下取消偏向锁,增大AutoBox
禁止统计数据PerfDisableSharedMem(无法使用jps,jstat等)
日志写入/dev/shm(http://calvin1978.blogcn.com/articles/latency2.html)
应用服务器其他进程导致(flume等导致进程抢占)
数据就近原则:堆内Guava-堆外缓存OHC-集中式缓存,时间间隔小的可以使用Sticky Session结合内存缓存
对象复用线程池-不可变对象-指定集合大小较少resize
缩短锁:ReadWriteLock(AbstractCacheMap)-分离锁(BlockingQueue)-分段锁
无锁设计:CAS-ThreadLocal-CopyWriteList,ConcurrentLinkedQueue
事务:减少事务范围以及不要在事务内进行RPC调用等
使用静态Throwable变量而不是每次创建(Netty)
保证可用性(尽量保证自己的可用性):
通过服务注册发现,服务负载均衡等实现了分布式调用提高了系统的整体吞吐和可用性,但是仍然存在流量徒增超载,网络抖动的问题。
如果是在网络抖动或者服务方不可用的场景下Hystrix使用资源隔离,超时限制,熔断降级等对调用方进行较好的自我保护,但仍然存在导致服务方过载的场景:
1,官方推荐的超时时间是TP90加一个均值(允许重试),线程池个数是目标QPS除以RT,随着机器数的变化如调用方机器变多一倍可能压垮服务方
2,服务方不能控制客户端配置的值,如果调用方对一个非核心服务配置了较大值且消耗了大量资源则降低了核心服务的可用性,现实中多以业务模块拆分,从开发维护成本考虑要达到核心接口和非核心的完全拆分不可能实现
3,对于A->B->C的场景,A调用B设置的超时时间比B调用C短的话会在A已经放弃调用的场景后续调用仍在进行导致浪费
业界方案:
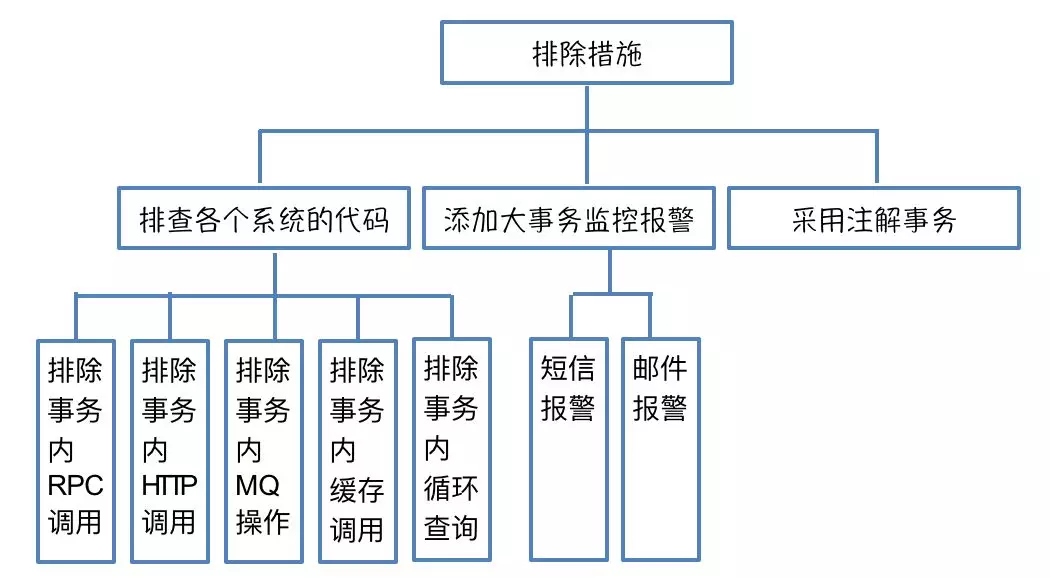
1)应用服务器队列控制(服务端隔离与限流):如果每个接口设置限流值配置麻烦且根据机器个数变动等不在有效。根据优先级区分处理队列中阻塞较久的请求,低优先级的可以FailFast保证高优先级的可用性,优点是服务端可用性在请求量变化大时可用性有所保证,缺点是优先级的定义在调用方和服务方都有不合适的场景(服务端无法区分调用端的业务要求,调用端偏向设置过高需要服务方与调用方接入时协商)。
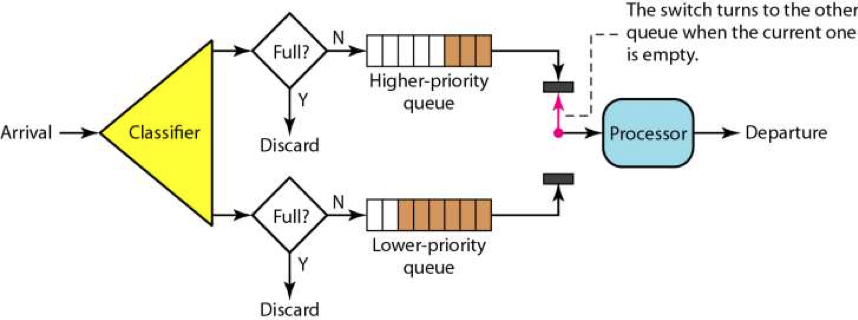
2)网关队列控制(http://t.cn/Run06Ua):从入口区分优先级使用不同的队列,使用先进后出LIFO如果处理的慢则抛弃(https://blogs.dropbox.com/tech/2018/03/meet-bandaid-the-dropbox-service-proxy/)。在网关设置核心请求和非核心请求发送不同的应用服务器进行隔离。缺点是网关配置要根据后端服务变化而调整,并发值过大导致后面压垮或者太小没有使用后端性能,仍然需要拿到阈值然后不断的调正。
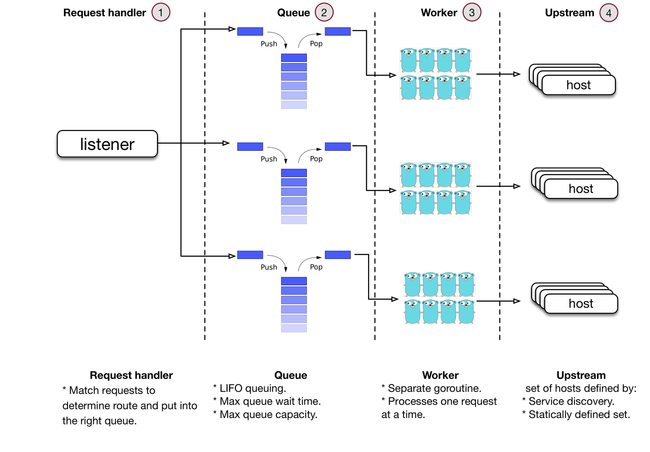
3)调用方服务方协同(拥塞控制算法):
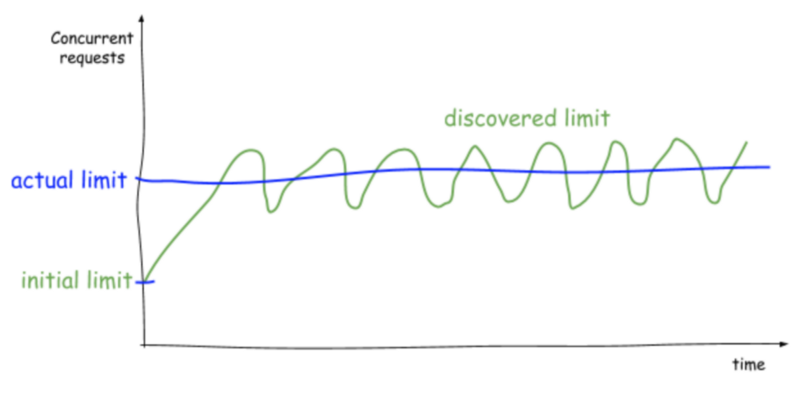
如何防止并发数设置的过小浪费机器资源,设置的过大触发延迟,客户端从小的并发数开始不断的加大并发数如果延迟没有变高则继续加大并发数,如果延迟变高则减少并发
问题:在业务量少的时候这个值较小,也不是实际的Limit,随着请求增加提高并发数提高如果因为基础中间导致被调用方变慢如何触发降低并发数???然后延迟统计的维度是每个接口还是整体
JAVA实现: https://github.com/Netflix/concurrency-limits
https://medium.com/@NetflixTechBlog/performance-under-load-3e6fa9a60581
一些想法:
压测常规化获取核心服务和非核心服务的最大并发数或者完全资源隔离,通过zk结合ratelimiter限流同时监控队列延迟
入口定义超时时间和优先级(SRE),在调用链路上优先服务高优先级进行隔离,同时在调用链路上跟踪处理时间,如果超时则快速失败,减少后续计算浪费(例如一次抖动导致慢但是入口已经TimeOut),在进行重试时控制间隔和重试次数
PS:Google SRE说使用平滑Load来决定是否服务端拒绝,但是如果是IO阻塞或者有锁这个指标是不对,应该结合RT决定。
保证正确性:
保证幂等性:全局id生成器,插入时唯一id约束,更新时限制status,version等。
传统的事务(2PC,3PC)处理方式性能较差且对关联系统可用性要求高,使用事件驱动实现服务间的完全解耦实现自治(http://bit.ly/2I1Q6c1).
存在的问题:发送消息给mq,mq存储了数据单未立即返回确认导致发送端回滚消费方仍处理。
1,事件表驱动:修改数据库同时插入事件表,外部程序扫描发送,仍存在多次发送需要处理幂等。
2,TCC模式:先把事件设置为Prepare,根据数据库状态进行提交或者回归,如果MQ没有收到确认则回查,需要调用方开发接口支持。
https://mp.weixin.qq.com/s/_zMzWRYy0TZkxQKDI5sDXA
减少故障时间:
一)故障前提前发现:系统设计时针对核心链路提供柔性业务降级(异步,减少查询条数etc),上线后通过压测等排查性能瓶颈, 验证限流、降级、熔断、报警等机制是否正常工作。通过chaosEngine(模拟超时,Load高等场景https://www.gremlin.com/product/)检验系统的可用性,服务方不定期关闭部分服务看调用方的情况(Google SRE)
二)故障中尽快解决(剔除又问题的节点etc):
1,提前未规划的非核心请求导致超载:发现->限流,面临的挑战时如何从业务上梳理清优先级和关联性
2,业务推广导致的核心请求:无状态服务动态扩容同时考虑扩容后对有状态服务的影响