【整理】
在求解最优化问题中,拉格朗日乘子法(Lagrange Multiplier)和KKT(Karush Kuhn Tucker)条件是两种最常用的方法。在有等式约束时使用拉格朗日乘子法,在有不等约束时使用KKT条件。
我们这里提到的最优化问题通常是指对于给定的某一函数,求其在指定作用域上的全局最小值(因为最小值与最大值可以很容易转化,即最大值问题可以转化成最小值问题)。提到KKT条件一般会附带的提一下拉格朗日乘子。对学过高等数学的人来说比较拉格朗日乘子应该会有些印象。二者均是求解最优化问题的方法,不同之处在于应用的情形不同。
一般情况下,最优化问题会碰到一下三种情况:
(1)无约束条件
这是最简单的情况,解决方法通常是函数对变量求导,令求导函数等于0的点可能是极值点。将结果带回原函数进行验证即可。
(2)等式约束条件
设目标函数为f(x),约束条件为h_k(x),形如:
s.t. 表示subject to ,“受限于”的意思,l表示有l个约束条件。

则解决方法是消元法或者拉格朗日法。消元法比较简单不在赘述,这里主要讲拉格朗日法,因为后面提到的KKT条件是对拉格朗日乘子法的一种泛化。
例如给定椭球:

求这个椭球的内接长方体的最大体积。这个问题实际上就是条件极值问题,即在条件 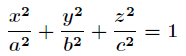 下,求
下,求 的最大值。
的最大值。
当然这个问题实际可以先根据条件消去 z (消元法),然后带入转化为无条件极值问题来处理。但是有时候这样做很困难,甚至是做不到的,这时候就需要用拉格朗日乘数法了。
首先定义拉格朗日函数F(x):

然后解变量的偏导方程:


如果有l个约束条件,就应该有l+1个方程。求出的方程组的解就可能是最优化值(高等数学中提到的极值),将结果带回原方程验证就可得到解。
回到上面的题目,通过拉格朗日乘数法将问题转化为

对 求偏导得到
求偏导得到

联立前面三个方程得到 和
和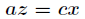 ,带入第四个方程解之
,带入第四个方程解之

带入解得最大体积为:

至于为什么这么做可以求解最优化?维基百科上给出了一个比较好的直观解释。
举个二维最优化的例子:
min f(x,y)
s.t. g(x,y) = c
这里画出z=f(x,y)的等高线(函数登高线定义见百度百科):

绿线标出的是约束g(x,y)=c的点的轨迹。蓝线是f(x,y)的等高线。箭头表示斜率,和等高线的法线平行。从梯度的方向上来看,显然有d1>d2。绿色的线是约束,也就是说,只要正好落在这条绿线上的点才可能是满足要求的点。如果没有这条约束,f(x,y)的最小值应该会落在最小那圈等高线内部的某一点上。而现在加上了约束,最小值点应该在哪里呢?显然应该是在f(x,y)的等高线正好和约束线相切的位置,因为如果只是相交意味着肯定还存在其它的等高线在该条等高线的内部或者外部,使得新的等高线与目标函数的交点的值更大或者更小,只有到等高线与目标函数的曲线相切的时候,可能取得最优值。
如果我们对约束也求梯度∇g(x,y),则其梯度如图中绿色箭头所示。很容易看出来,要想让目标函数f(x,y)的等高线和约束相切,则他们切点的梯度一定在一条直线上(f和g的斜率平行)。
也即在最优化解的时候:∇f(x,y)=λ(∇g(x,y)-C) (其中∇为梯度算子; 即:f(x)的梯度 = λ* g(x)的梯度,λ是常数,可以是任何非0实数,表示左右两边同向。)
即:▽[f(x,y)+λ(g(x,y)−c)]=0λ≠0
那么拉格朗日函数: F(x,y)=f(x,y)+λ(g(x,y)−c) 在达到极值时与f(x,y)相等,因为F(x,y)达到极值时g(x,y)−c总等于零。
min( F(x,λ) )取得极小值时其导数为0,即▽f(x)+▽∑ni=λihi(x)=0,也就是说f(x)和h(x)的梯度共线。
简单的说,在F(x,λ)取得最优化解的时候,即F(x,λ)取极值(导数为0,▽[f(x,y)+λ(g(x,y)−c)]=0)的时候,f(x)与g(x) 梯度共线,此时就是在条件约束g(x)下,f(x)的最优化解。
(3)不等式约束条件
设目标函数f(x),不等式约束为g(x),有的教程还会添加上等式约束条件h(x)。此时的约束优化问题描述如下:

则我们定义不等式约束下的拉格朗日函数L,则L表达式为:

其中f(x)是原目标函数,hj(x)是第j个等式约束条件,λj是对应的约束系数,gk是不等式约束,uk是对应的约束系数。
常用的方法是KKT条件,同样地,把所有的不等式约束、等式约束和目标函数全部写为一个式子L(a, b, x)= f(x) + a*g(x)+b*h(x),
KKT条件是说最优值必须满足以下条件:
1)L(a, b, x)对x求导为零;
2)h(x) =0;
3)a*g(x) = 0;
求取这些等式之后就能得到候选最优值。其中第三个式子非常有趣,因为g(x)<=0,如果要满足这个等式,必须a=0或者g(x)=0. 这是SVM的很多重要性质的来源,如支持向量的概念。
接下来主要介绍KKT条件,推导及应用。详细推导过程如下:


参考:
【1】拉格朗日乘数法
【2】KKT条件介绍
=====================================================
版权声明:本文为博主原创文章,未经博主允许不得转载。
在求取有约束条件的优化问题时,拉格朗日乘子法(Lagrange Multiplier) 和KKT条件是非常重要的两个求取方法,对于等式约束的优化问题,可以应用拉格朗日乘子法去求取最优值;如果含有不等式约束,可以应用KKT条件去求取。当然,这两个方法求得的结果只是必要条件,只有当是凸函数的情况下,才能保证是充分必要条件。KKT条件是拉格朗日乘子法的泛化。之前学习的时候,只知道直接应用两个方法,但是却不知道为什么拉格朗日乘子法(Lagrange Multiplier) 和KKT条件能够起作用,为什么要这样去求取最优值呢?
本文将首先把什么是拉格朗日乘子法(Lagrange Multiplier) 和KKT条件叙述一下;然后开始分别谈谈为什么要这样求最优值。
一. 拉格朗日乘子法(Lagrange Multiplier) 和KKT条件
通常我们需要求解的最优化问题有如下几类:
(i) 无约束优化问题,可以写为:
min f(x);
(ii) 有等式约束的优化问题,可以写为:
min f(x),
s.t. h_i(x) = 0; i =1, ..., n
(iii) 有不等式约束的优化问题,可以写为:
min f(x),
s.t. g_i(x) <= 0; i =1, ..., n
h_j(x) = 0; j =1, ..., m
对于第(i)类的优化问题,常常使用的方法就是Fermat定理,即使用求取f(x)的导数,然后令其为零,可以求得候选最优值,再在这些候选值中验证;如果是凸函数,可以保证是最优解。
对于第(ii)类的优化问题,常常使用的方法就是拉格朗日乘子法(Lagrange Multiplier) ,即把等式约束h_i(x)用一个系数与f(x)写为一个式子,称为拉格朗日函数,而系数称为拉格朗日乘子。通过拉格朗日函数对各个变量求导,令其为零,可以求得候选值集合,然后验证求得最优值。
对于第(iii)类的优化问题,常常使用的方法就是KKT条件。同样地,我们把所有的等式、不等式约束与f(x)写为一个式子,也叫拉格朗日函数,系数也称拉格朗日乘子,通过一些条件,可以求出最优值的必要条件,这个条件称为KKT条件。
(a) 拉格朗日乘子法(Lagrange Multiplier)
对于等式约束,我们可以通过一个拉格朗日系数a 把等式约束和目标函数组合成为一个式子L(a, x) = f(x) + a*h(x), 这里把a和h(x)视为向量形式,a是横向量,h(x)为列向量,之所以这么写,完全是因为csdn很难写数学公式,只能将就了.....。
然后求取最优值,可以通过对L(a,x)对各个参数求导取零,联立等式进行求取,这个在高等数学里面有讲,但是没有讲为什么这么做就可以,在后面,将简要介绍其思想。
(b) KKT条件
对于含有不等式约束的优化问题,如何求取最优值呢?常用的方法是KKT条件,同样地,把所有的不等式约束、等式约束和目标函数全部写为一个式子L(a, b, x)= f(x) + a*g(x)+b*h(x),KKT条件是说最优值必须满足以下条件:
1. L(a, b, x)对x求导为零;
2. h(x) =0;
3. a*g(x) = 0;
求取这三个等式之后就能得到候选最优值。其中第三个式子非常有趣,因为g(x)<=0,如果要满足这个等式,必须a=0或者g(x)=0. 这是SVM的很多重要性质的来源,如支持向量的概念。
二. 为什么拉格朗日乘子法(Lagrange Multiplier) 和KKT条件能够得到最优值?
为什么要这么求能得到最优值?先说拉格朗日乘子法,设想我们的目标函数z = f(x), x是向量, z取不同的值,相当于可以投影在x构成的平面(曲面)上,即成为等高线,如下图,目标函数是f(x, y),这里x是标量,虚线是等高线,现在假设我们的约束g(x)=0,x是向量,在x构成的平面或者曲面上是一条曲线,假设g(x)与等高线相交,交点就是同时满足等式约束条件和目标函数的可行域的值,但肯定不是最优值,因为相交意味着肯定还存在其它的等高线在该条等高线的内部或者外部,使得新的等高线与目标函数的交点的值更大或者更小,只有到等高线与目标函数的曲线相切的时候,可能取得最优值,如下图所示,即等高线和目标函数的曲线在该点的法向量必须有相同方向,所以最优值必须满足:f(x)的梯度 = a* g(x)的梯度,a是常数,表示左右两边同向。这个等式就是L(a,x)对参数求导的结果。(上述描述,我不知道描述清楚没,如果与我物理位置很近的话,直接找我,我当面讲好理解一些,注:下图来自wiki)。

而KKT条件是满足强对偶条件的优化问题的必要条件,可以这样理解:我们要求min f(x), L(a, b, x) = f(x) + a*g(x) + b*h(x),a>=0,我们可以把f(x)写为:max_{a,b} L(a,b,x),为什么呢?因为h(x)=0, g(x)<=0,现在是取L(a,b,x)的最大值,a*g(x)是<=0,所以L(a,b,x)只有在a*g(x) = 0的情况下才能取得最大值,否则,就不满足约束条件,因此max_{a,b} L(a,b,x)在满足约束条件的情况下就是f(x),因此我们的目标函数可以写为 min_x max_{a,b} L(a,b,x)。如果用对偶表达式: max_{a,b} min_x L(a,b,x),由于我们的优化是满足强对偶的(强对偶就是说对偶式子的最优值是等于原问题的最优值的),所以在取得最优值x0的条件下,它满足 f(x0) = max_{a,b} min_x L(a,b,x) = min_x max_{a,b} L(a,b,x) =f(x0),我们来看看中间两个式子发生了什么事情:
f(x0) = max_{a,b} min_x L(a,b,x) = max_{a,b} min_x f(x) + a*g(x) + b*h(x) = max_{a,b} f(x0)+a*g(x0)+b*h(x0) = f(x0)
可以看到上述加黑的地方本质上是说 min_x f(x) + a*g(x) + b*h(x) 在x0取得了最小值,用fermat定理,即是说对于函数 f(x) + a*g(x) + b*h(x),求取导数要等于零,即
f(x)的梯度+a*g(x)的梯度+ b*h(x)的梯度 = 0
这就是kkt条件中第一个条件:L(a, b, x)对x求导为零。
而之前说明过,a*g(x) = 0,这时kkt条件的第3个条件,当然已知的条件h(x)=0必须被满足,所有上述说明,满足强对偶条件的优化问题的最优值都必须满足KKT条件,即上述说明的三个条件。可以把KKT条件视为是拉格朗日乘子法的泛化。