30 November 2019
18:31
人类历史上,除了计算机外从没有一项技术可以在短短的几十年间,能够全方位的影响整个社会的各个领域。技术的发展,少不了许多代人为之的努力。无论是在计算机硬件上,还是在实现的算法上,这其中有着大量非常精巧的设计,在后面的文章中,将会不定期的把这些知识展现出来。这次介绍一个在隐私保护领域常用的模型,K-匿名。
背景
随着大数据分析技术的迅猛发展,研究者以及各个商业公司迫切的需要从大数据中挖掘出有价值的信息。要想从大数据中挖掘信息,首先要有足够的可公开的数据,但是当大规模数据拥有者比如医院、政府、大数据公司等,对外发布数据时,不可避免的会涉及到公民的隐私问题。如果最大限度的保护公布数据的统计特征,又不泄露公民的隐私显得格外重要。
分析
表1是某医院数据库中存储的一张病历表。一共有7个属性,分别为用户识别号tId、姓名name、省份province、年龄age、性别sex、所患疾病disease、邮编zip。
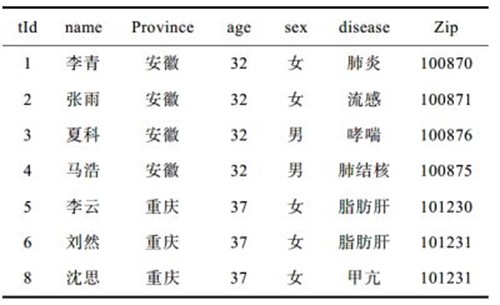
表1 医院病历表
这一张表医院是不能直接用于发布出去的,至少也要把病人的姓名删掉然后再发布。在这张表里,病人的姓名是病人的标识符,如果有身份证号的话,也是属于标识符。标识符就是能够唯一标识病人身份的属性。对于标识符通常采用的是隐匿处理的方式(删除、屏蔽或加密)。那么我们假设医院将表1进行了发布,为了保护病人的隐私,将姓名这一属性删除掉了。
在这张表里,除了有标识符外,还有一些属性是准标识符。准标识符指的是那些介于标识符与非敏感属性之间的一些属性,这些属性通过与其它的数据表进行结合(链接攻击),也能够识别出病人的具体信息。在表1中姓名、省份、年龄、性别、邮编都可以看成准标识符。
链接攻击
链接攻击是从发布的数据中获取隐私信息最常用的攻击方法。攻击者利用从别处获得的数据,和本次发布的数据进行链接,从而推测出病人的隐私信息。
例如,攻击者从别处获得了该区域的选民信息表。该选民信息表中并没有涉及个体的隐私信息。

表2 选民信息表
当攻击者将表1和表2的准标识符进行链接起来时,会惊奇的发现,名为李青的选民,具有很大的概率是肺炎患者。这样一来,病人的隐私信息就泄露了。
K-匿名隐私保护模型
K-匿名隐私保护模型要求每条记录在发布数据前,都至少与表中K-1条记录无法区分开来。具有相同准标识符的记录构成一个等价类。所以,即使攻击者知道了一定的背景知识,知道了表2的选民信息,也无法与表1中确定的一条信息进行链接,因为在表1中有K条信息可以被链接,攻击者此时便无法唯一的识别出某个病人。表3满足2-匿名医疗数据表(此表数据的选取和表1表2无关)。表3中存在3个等价类,可以看出一些属性的数据范围变大了,这是泛化技术。
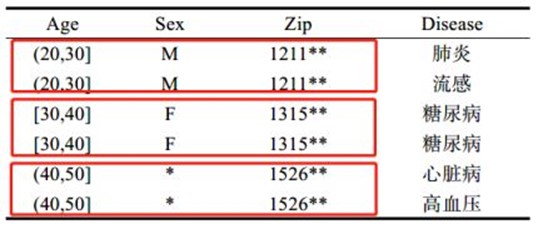
表3 满足K=2匿名数据表
细心的读者可能看出来了一些破绽,如果处于同一等价类中的记录,在敏感属性(疾病)上取值是相同的话,同样会泄露病人的隐私,这是同质性攻击。
来自 <https://zhuanlan.zhihu.com/p/50183231>
提出背景
Internet 技术、大容量存储技术的迅猛发 展以及数据共享范围的逐步扩大,数据的自动采集 和发布越来越频繁,信息共享较以前来得更为容易 和方便;但另一方面,以信息共享与数据挖掘为目的的数据发布过程中隐私泄露问题也日益突出,因此如何在实现信息共享的同时,有效地保护私有敏感信息不被泄漏就显得尤为重要。数据发布者在发布数据前需要对数据集进行敏感信息的保护处理工作,数据发布中隐私保护对象主要是用户敏感信息与个体间的关联关系,因此,破坏这种关联关系是数据发布过程隐私保护的主要研究问题。
传统处理办法
(一)匿名。
对姓名,身份证号等能表示一个用户的显示标识进行删除
弊端:攻击者可以通过用户的其他信息,例如生日、性别、年龄等从其他渠道获取的个人 信息进行链接,从而推断出用户的隐私数据。 如下图的表:
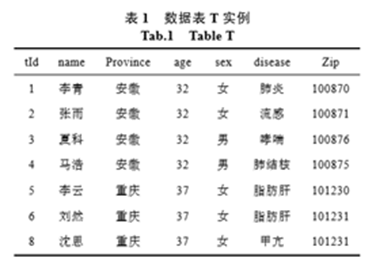
先引入2个概念
1.标识符(explicit identifiers):可以直接确定一个个体。如:id,姓名等。
2.准标识符集(quasi-identifler attribute set ):可以和外部表连接来识别个体的最小属性集,如表1中的 {省份,年纪,性别,邮编}。攻击者可以通过这4个属性,确定一个个体。
为了保护用户隐私,不让患者的患病信息泄露,在发布信息时,删去患者姓名,试图达到保护隐私的目的。但是攻击者手上还有选民登记表。攻击者根据准标识符进行链接,就可以推断出李青患有肺炎这一敏感信息。这就是链式攻击。
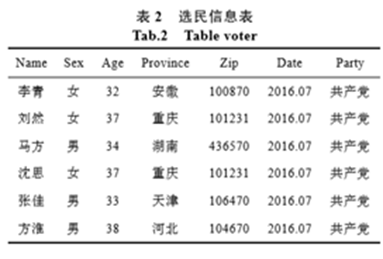
通过这个例子,我们也发现,使用删除标识符的方式发布数据无法真正阻止隐私泄露,攻击者可以通过链接攻击获取个体的隐私数据
(二)数据扰乱。
对初始数据进行扭曲、扰乱、随机化之后再进行挖掘,
弊端:尽管这种方法能够保证结果的整体统 计性,但一般是以破坏数据的真实性和完整性为代价。
(三)数据加密。
利用非对称加密机制形成交互计算的协议,实现无信息泄露的分布式安全计算,以支持分布式环境中隐私保持的挖掘工作,例如安全两方或多方计算问题,但该方法需要过多的计算资源。
K匿名的基本概念
为解决链接攻击所导致的隐私泄露问题,引入k-匿名 (k-anonymity) 方法。k-匿名通过概括(对数据进行更加概括、抽象的描述)和隐匿(不发布某些数据项)技术,发布精度较低的数据,使得同一个准标识符至少有k条记录,使观察者无法通过准标识符连接记录。

原表虽然隐去了姓名,但是攻击者通过邮编和年纪,依然可以定位一条记录,经过k匿名后,对邮编和年纪做以抽象,攻击者即使知道某一用户的具体邮编为47906,年龄47,也无法确定用户患哪一种病。上图的同一个准标识符{邮编,年纪}至少有3条记录,所以为3匿名模型。
k-anonymity模型的实施,使得观察者无法以高于1/k的置信度通过准标识符来识别用户。
来自 <https://www.cnblogs.com/jiangshaoyin/p/10190540.html>