子查询的定义:
子查询是一个查询语句嵌套着另外的查询语句,用来进行一定层次的查询,其中子查询相当于第一步查询过滤,外查询就是最后得到结果的查询。经常会用到关键字:ANY、SOME、ALL、IN、EXISTS(exist),注:在子查询语句的后面,必须起别名: //select name,price from (select * from car where powers = 130) as aa;(必须起别名)
学生表:

成绩表:
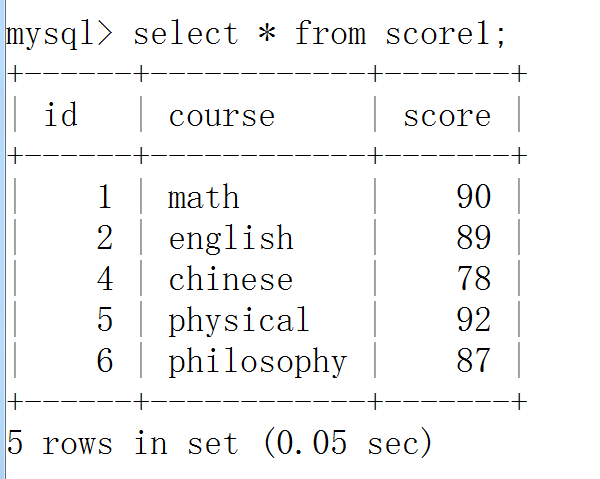
学生其他信息表:

1、where型子查询:把内层查询的结果作为外层查询的条件
A、关键字ANY、SOME子查询:ANY/SOME都是表示满足其中一个条件即可。
-- 在学生表中选择ID大于表课程表中ID的数据记录
-- ID只需要大于ID中任何一个就满足条件
SELECT * FROM name WHERE ID > ANY(SELECT ID FROM score1);

B、ALL关键字查询
与ANY/SOME相反,是要满足所有的条件才行。
SELECT * FROM score1 WHERE id> ALL(SELECT id FROM name) ;

子查询的结果是查到name表中的id列,score1表中的id都要满足大于id(name的)的条件才能查询。
C、IN关键字查询
IN关键字查询:若外查询想要查询的结果在子查询中,则返回true,继续查询到结果,否则返回false,查询为NULL。
注意:与ANY类似,但是很不相同,IN后面可以是子查询,也可以是给定的集合。ANY后面必须为子查询,且前面必须有运算符(<、>、=)
from型子查询
即把from后的表名换成查询语句,即把内查询的结果作为一张临时表
select aa.id from (select * from score1 where id > all(select id from name))as aa;

1、Exists型子查询:把外层的查询结果,拿到内层中,看是否成立
关键字EXISTS查询:
表示在EXISTS后面的查询结果是否有结果,而不在乎子查询返回什么样的结果。
若子查询的结果至少有一行,则为True,若子查询结果为NULL,则返回False,进行下一次外层查询。

现在我要查询第一张表中有子项目的数据
select cat_id,cat_name,parent_id from biao1 where (select * from biao2 where biao1.cat_id = biao2.cat_id);
外层查询一次一次的执行,
第一次取出一个cat_id = 1,带进子查询中的where biao1.cat_id = biao2.cat_id 因为cat_id = 1在biao2中不存在,所以 外层查询进行第二行的查询
第二次取出cat_id = 2,带进子查询中的where biao1.cat_id = biao2.cat_id 因为cat_id =2在biao2中存在,所以 外层查询可以执行select cat_id,cat_name,parent_id 外层查询进行第三行的查询
第三次取出cat_id = 3,带进子查询中的where biao1.cat_id = biao2.cat_id 因为cat_id =3在biao2中存在,所以 外层查询可以执行select cat_id,cat_name,parent_id
查询结果跟子查询的结果没有关系,只要外层查询的结果在子查询中能够满足,就可以查询出外层查询的结果
Union链接查询
union 查询就是把 2 条或多条 sql 的查询结果 , 合并成 1 个结果集,各语句取出的列数必须相同;如果不相同 , 会报错;
sql1 返回 N 行
sql2 返回 M 行
sql1 union sql2 , 返回 N+M 行
注意 :
使用 union 时 , 完全相等的行 , 将会被合并 ,合并是比较耗时的操作 , 两行会在比较看是否完全相等,一半不让 union 进行合并 , 使用 "union all" 可以避免;在实际中 , 一般直接使用 union all 来合并查询,而不是用union;
例如:(还是以上面三个图为例)
select age,sex from exist union select id,name from name;

union 的子句中 , 不用写 order by
select * from a order by num desc union all select * from b order by num desc;
运行以上sql语句,你会发现,order by 并没有发挥作用;这是因为每一条子句就算你排序了,但是合并以后的结果依然还是无序的;如果想对合并后的结果来排序,可以用order by;sql语句需要做一定的调整;以下是对合并后结果排序:推荐这种方式 还有limit
select * from a union all select * from b order by num desc;
左链接查询
以左表为准,去右表找匹配的数据,找不到用null补齐
select * from score1 left join name on score1.id =name.id;
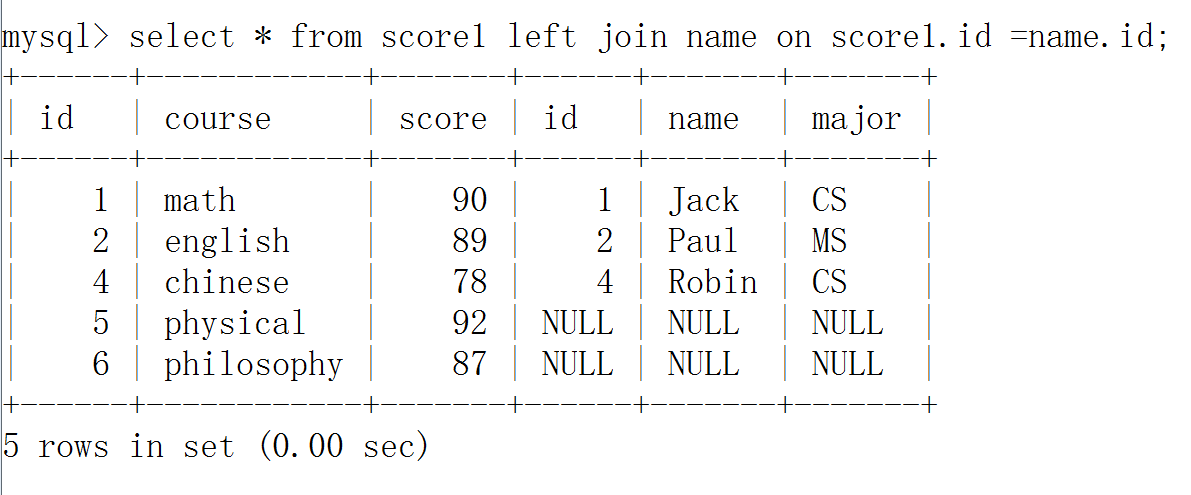
取出特定元素:
select course,name from score1 left join name on score1.id =name.id;

右链接查询 ( 和左链接类似,不举例子了)
以右表为准,去左表找匹配的数据,找不到用null补齐
内连接查询
查询左右表中都有的数据,去掉左右表中null的数据
内连接是左右链接的交集
select * from score1 join name on score1.id =name.id;
