网络爬虫,是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。
但是当网络爬虫被滥用后,互联网上就出现太多同质的东西,原创得不到保护。
于是,很多网站开始反网络爬虫,想方设法保护自己的内容。 ------摘自百度百科
本文以有道翻译为例作为讲解,使用的 python 3.5.2 版本 ,涉及到反爬虫手段有 sign签名、时间戳,逆向解析 js 来确定签名算法。
研究有道词典的反爬虫机制
1、打开有道词典 http://fanyi.youdao.com/,按下F12,输入要翻译的内容进行翻译,观察network。

2、找到 post 请求,点击查看(一般来说客户端都是用post方法向服务端发送请求)

3、查看header 和 response ,可以确定网站进行自动翻译时,用的就是这条请求。
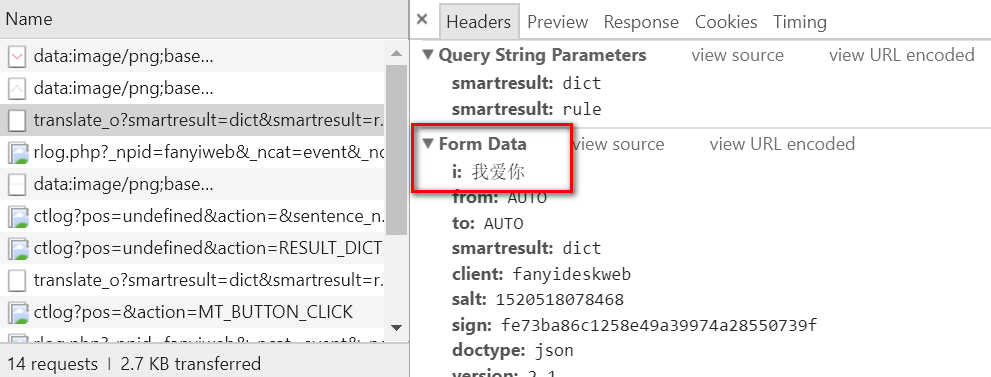

4、找出post 发送的给服务端的数据(Headers标签下的 Form Data),并进行分析
i:我爱你 #需要翻译的内容 from:AUTO #应该为自动翻译,自动检测语言并翻译 to:AUTO #应该为自动翻译,自动检测语言并翻译 smartresult:dict #多次翻译时,值都不变,暂时不管 client:fanyideskweb #同上 doctype:json #同上 version:2.1 #同上 keyfrom:fanyi.web #同上 typoResult:false #同上 action:FY_BY_REALTIME #提交表单的方式,回车键或者鼠标点击 salt:1520518078468 # 凭经验猜测是时间戳,不过还需要验证 sign:fe73ba86c1258e49a39974a28550739f #标记,需要找一下生成规则
多次翻译发现,每次提交发现只有i 、salt、 sign的值是不同的,i不用多说,现在我们现在需要知道salt和sign的生成规则。
这里我们可以分析一下,这两个值在每次请求的时候都不一样,只有两种情况:第一是每次翻译的时候,浏览器先从服务器获取这两个值;第二是在本地,用JS代码按照一定的规则生成。
我们首先来看第一个情况,我们可以看到在每次发送翻译请求的时候,并没有一个请求是专门用来获取这两个值的:
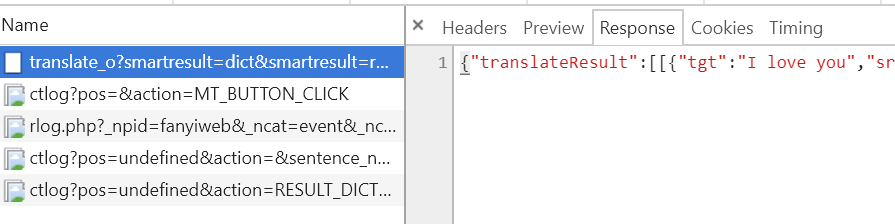

所以可以排除服务器返回的可能。
那么接下来看一下,在本地是怎么生成的。这需要通过js 找一下。
查找方式是:网页右键--查看源代码--搜索(ctrl+F),搜索内容输入.js,发现一共有3个js文件,以此进入,继续通过查找的方式搜“ sign” “salt”
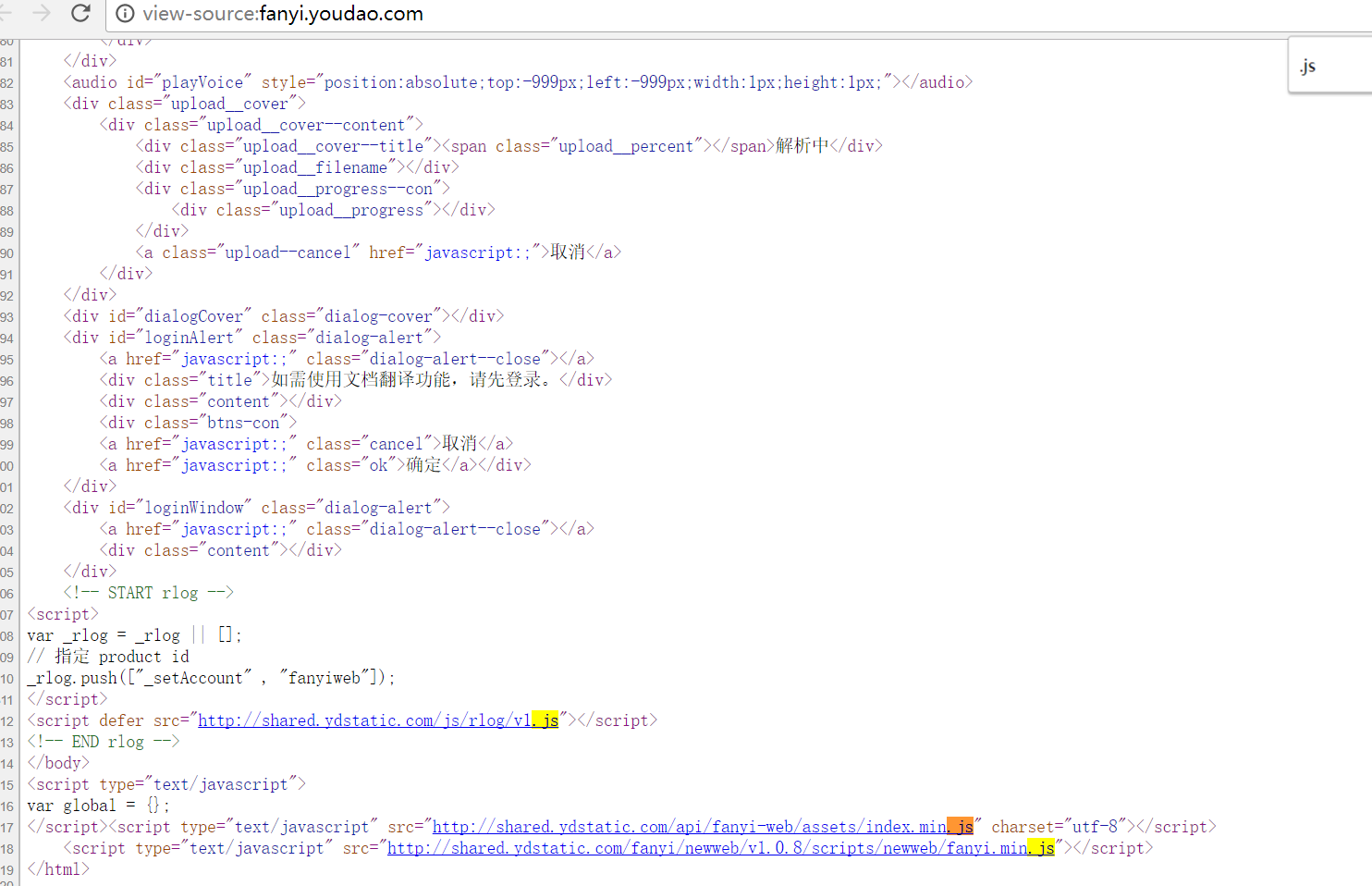

最终,我们在fanyi.js 下面搜索了sign 和 salt ,然后全选所有的代码,复制下来,再打开站长工具:http://tool.chinaz.com/Tools/jsformat.aspx。把代码复制进去后,点击格式化:

然后把格式化后的代码复制下来,用pycharm打开,搜索sign和salt,找到相关的代码。有了这些源码就可以分析了,salt 的确是时间戳,后面加了随机数,sign 是几个数相加后进行 md5 加密得到的:
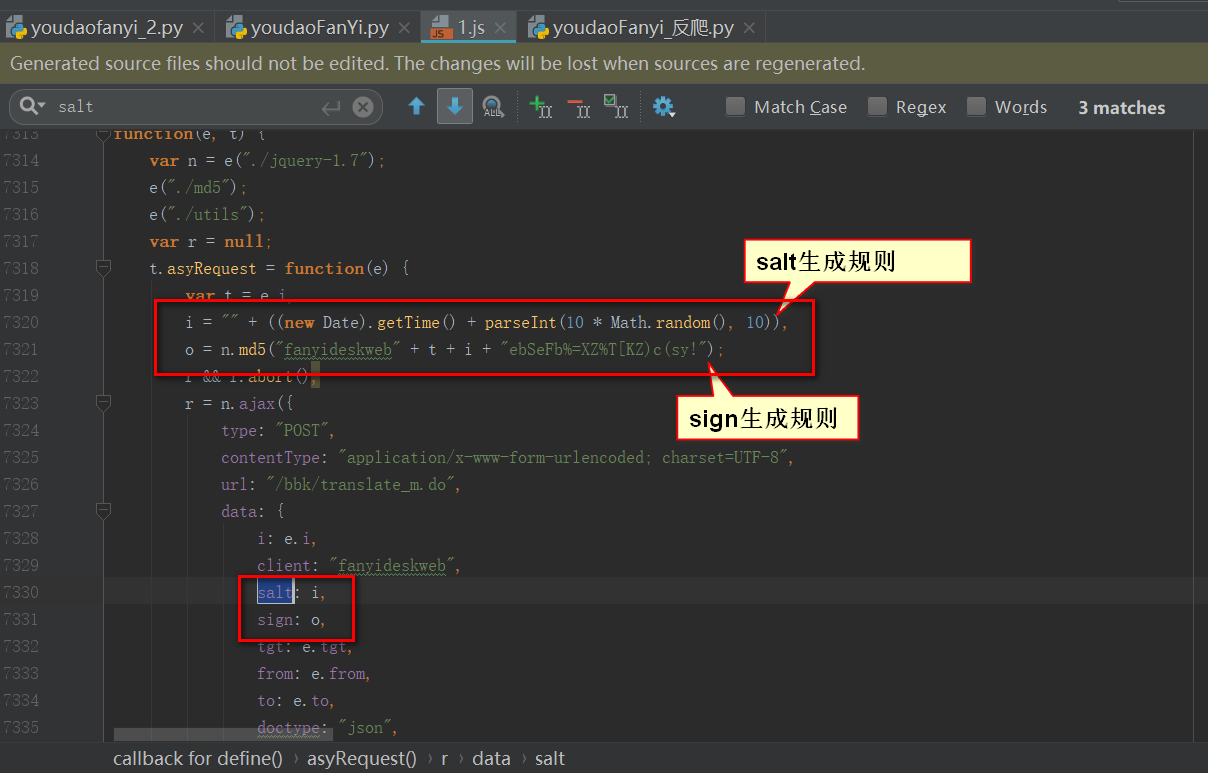
现在可以写代码了,嘿嘿~
源码如下(有一个要注意的地方,请求中获取的url 需要去除 “_o” ,否则运行会提示):
1 import urllib.request 2 import urllib.parse 3 import time 4 import hashlib #提供了常见的摘要算法 5 import json 6 url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&sessionFrom=null' #上一次群里面那个失效了 把_o去掉就可以了 7 8 # 找出每次提交都变化的值 9 u = 'fanyideskweb' 10 d = input('请输入翻译的内容:') 11 # js的代码: f = "" + ((new Date).getTime() + parseInt(10 * Math.random(), 10)), 12 # 通过13位的时间戳加上一个随机的个位数 13 # python 中的时间戳是 10位加小数点,可以乘以 1000 取整 14 f = str(int(time.time()*1000)) 15 16 c = "rY0D^0'nM0}g5Mm1z%1G4" 17 g = hashlib.md5() 18 g.update((u + d + f + c).encode('utf-8')) 19 # 组装head 20 head = {} 21 head['User-Agent'] = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:54.0) Gecko/20100101 Firefox/54.0' 22 head['Host'] = 'fanyi.youdao.com' 23 head['Referer'] = 'http://fanyi.youdao.com/' 24 # 组装data 25 data = {} 26 data['i'] = d # 这是我们要翻译的字符串 27 data['from'] = 'AUTO' 28 data['to'] = 'AUTO' 29 data['smartresult'] = 'dict' 30 data['client'] = u 31 data['salt'] = f # 当前时间戳。 32 data['sign'] = g.hexdigest() # 签名字符串。 33 data['doctype'] = 'json' 34 data['version'] = '2.1' 35 data['keyfrom'] = 'fanyi.web' 36 data['action'] = 'FY_BY_CL1CKBUTTON' 37 data['typoResult'] = 'true' 38 data = urllib.parse.urlencode(data).encode('utf-8') 39 40 req = urllib.request.Request(url, data, head) # 用Request类构建了一个完整的请求,增加了headers等一些信息 41 response = urllib.request.urlopen(req) 42 html = response.read().decode('utf-8') 43 target = json.loads(html) 44 print('翻译结果: %s ' % (target['translateResult'][0][0]['tgt']))