数据的寻址方式
1、 隐含寻址:操作数的地址由指令决定
2、 立即寻址:指令的地址字段即为操作数
3、 直接寻址:指令的地址字段即为操作数的地址
4、 间接寻址:指令的地址字段即为操作数的地址的地址
5、 寄存器寻址:指令的地址字段为寄存器,且寄存器中保存操作数
6、 寄存器间接寻址:指令的地址字段为寄存器,且寄存器中保存操作数的地址
7、 偏移寻址:两个地址字段EA = A + (R),至少一个为显式的地址A,另一个可能是基于操作码的某个隐含使用的寄存器R
① 相对寻址:隐含使用的寄存器为程序计数器PC, 有效地址为EA = A + (PC)
② 基址寻址:隐含使用的寄存器中保存一个存储器地址,地址字段A保存偏移量
③ 变址寻址:隐含使用的寄存器中保存一个偏移量,地址字段A保存存储器地址
8、 段寻址:存储器地址左移N位再加上偏移地址
9、 堆栈寻址:push指令和pop指令等,有点像默认地址为栈顶的隐含寻址
求浮点数的规格化数
1、 最小正数:阶码的最小负数值与尾数的最小正数值组合而成
2、 最大正数:阶码的最大正数值与尾数的最大正数值组合而成
3、 最小负数:阶码的最大正数值与尾数的最小负数值组合而成
4、 最大负数:阶码的最小负数值与尾数的最大负数值组合而成
注意:对补码来说:如果是正数,尾数的最高位为“1”;如果是负数,尾数的最高位应为“0”
IEEE754浮点数规格化表示:阶码E=e-127,尾数的小数点前面隐含一个1
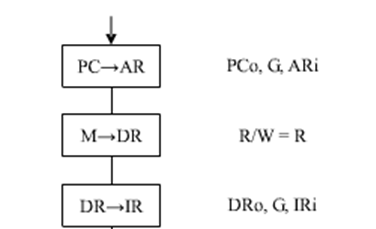
绘制指令周期流程图以及在旁边列出相应的微操作控制信号序列:
所有指令的取指阶段都相同,因此图和序列也相同,照背即可,G表示门电路信号,不同题目可能不同,下面以某一题的ADD,(R2),R0举例
小下标i或者o表示这个信号是输入信号还是输出信号
接着是一个菱形四边形,分隔取指阶段和执行阶段。
接着是执行阶段,执行阶段一般先取数再根据指令的不同送入不同的地方。
① 立即寻址、寄存器寻址:直接将地址字段A或者寄存器n的内容通过门电路送入相应的位置,产生的序列为:Ao或者Rno,G,Xi(送入ALU)或者PCi(JMP指令)
② 直接寻址、寄存器间接寻址:
先将地址字段或者寄存器n的内容送入AR,相应的序列为:Ao或Rno,G,Ari
其次根据AR在主存M中找到对应的数据送入DR,只需改变控制R/W控制,因此产生的序列为:R/W = R
最后再将DR中的数据送入相应位置,产生的序列为:DRo,G,Yi或者其他地方
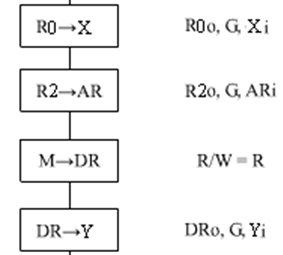
取完数后,再根据指令的不同处理数据,然后把结果送入某个寄存器或者主存中。如果是数据运算指令,则产生的序列为:+(-、*、÷),G,Ri

最后,执行阶段结束,CPU转入公操作,公操作符为~

求顺序存储器和交叉存储器的带宽
1、 求数据总量q = 字数m * 字长
2、 求传输m个字所需的时间:
顺序存储器:t1 = m * T(存储周期)
交叉存储器:t2 = T + (m-1)*τ(总线周期)
3、 用数据总量q分别处以t1、t2即可得到顺序、交叉存储器的带宽,单位为bit/s
4、 注意1s = 10^9ns
浮点数加减法x + y
按要求写出x和y的浮点机器数[x]浮 、[y]浮
① 0操作数检查
两数是否都非0。
② 求阶差
小阶向大阶对齐
③ 尾数相加。
[Mx]补 00.101011
+ [My]补 11.100101(1)
00.010000(1)
④ 规格化处理
补码尾数的最高位与符号位相反
⑤ 舍入处理
括号内的最高位如果为1则进位,否则全部舍去
⑥ 溢出检查
双符号位下,01为正溢出,10为负溢出
最后写出结果x+y=2-011×0.100001
cache的映射方式(假设cache有m行)
1、 直接映射:,主存的第n行映射到cache的第n%m行
2、 全相联映射:主存的第n行可以映射到cache的任意行
3、 组相连映射:r路组相连,先将cache分成m/r组,主存的第n行映射到cache的第n%(m/r)组的第0~(r-1)行
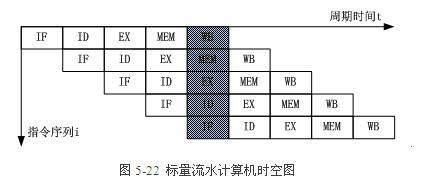
流水线
1、 流水线的时钟周期为耗时最大的功能段所用的时间
2、 实际吞吐率=指令条数÷流水线时间
流水线时间=一条指令所需时间+(指令条数-1)*时间最长的指令功能段
3、 最大吞吐率=1 / 平均延迟时间
平均延迟时间=所有功能段所花费的时间÷功能段的数量
4、 加速比=非流水线时间÷流水线时间
非流水线时间=n条指令所需时间
5、 时空图