参考资料传送门
http://blog.csdn.net/lyy289065406/article/details/6762370
http://blog.csdn.net/lyy289065406/article/details/6762432
http://blog.csdn.net/xinghongduo/article/details/6195337
题目链接
http://poj.org/problem?id=3177
题目大意:有F个牧场,1<=F<=5000,现在一个牧群经常需要从一个牧场迁移到另一个牧场。奶牛们已经厌烦老是走同一条路,所以有必要再新修几条路,这样它们从一个牧场迁移到另一个牧场时总是可以选择至少两条独立的路。现在F个牧场的任何两个牧场之间已经至少有一条路了,奶牛们需要至少有两条。
给定现有的R条直接连接两个牧场的路,F-1<=R<=10000,计算至少需要新修多少条直接连接两个牧场的路,使得任何两个牧场之间至少有两条独立的路。两条独立的路是指没有公共边的路,但可以经过同一个中间顶点
总结来说,给定一个连通的无向图G,至少要添加几条边,才能使其变为双连通图。
显然,当图G存在桥(割边)的时候,它必定不是双连通的。桥的两个端点必定分别属于图G的两个【边双连通分量】(注意不是点双连通分量),一旦删除了桥,这两个【边双连通分量】必定断开,图G就不连通了。但是如果在两个【边双连通分量】之间再添加一条边,桥就不再是桥了,这两个【边双连通分量】之间也就是双连通了。
有关图论的知识点的定义:http://www.byvoid.com/blog/biconnect/
要解这个问题,我们先要了解Tarjar算法
说到以Tarjan命名的算法,我们经常提到的有3个,其中就包括本文所介绍的求强连通分量的Tarjan算法。而提出此算法的普林斯顿大学的Robert E Tarjan教授也是1986年的图灵奖获得者。
首先明确几个概念。
1. 强连通图。在一个强连通图中,任意两个点都通过一定路径互相连通。比如图一是一个强连通图,而图二不是。因为没有一条路使得点4到达点1、2或3。

2. 强连通分量。在一个非强连通图中极大的强连通子图就是该图的强连通分量。比如图三中子图{1,2,3,5}是一个强连通分量,子图{4}是一个强连通分量。

其实,tarjan算法的基础是DFS。我们准备两个数组Low和Dfn。Low数组是一个标记数组,记录该点所在的强连通子图所在搜索子树的根节点的Dfn值(很绕嘴,往下看你就会明白),Dfn数组记录搜索到该点的时间,也就是第几个搜索这个点的。根据以下几条规则,经过搜索遍历该图(无需回溯)和对栈的操作,我们就可以得到该有向图的强连通分量。
- 数组的初始化:当首次搜索到点p时,Dfn与Low数组的值都为搜索到该点的次序。(比如1这点是第一个被搜索的,则Dfn[1] = 1, Low[1] = 1)
- 堆栈:每搜索到一个点,将它压入栈顶。
- 当点p有到点p’的路径时,如果p’不在栈中,且p’没有进入过栈,则将p’压入栈顶,Dfn[p’]与Low[p’]数组的值都为搜索到该点的次序 ,并递归搜索p’点。
- 当点p有到点p’的路径时,如果p’不在栈中,且p’已经出栈,则忽略。
- 当点p有到点p’的路径时,如果p’在栈中,p的low值为p的low值和p’的low值中较小的一个。
- 当点p的所有子树已经全部遍历过后,如果p的low值等于dfn值,则说明p并没有返祖路径,以p为根构成一个强连通分量, 将p以及在它之上的元素弹出栈。这些出栈的元素组成一个强连通分量。
- 返回p的父亲节点继续搜索(或许会更换搜索的起点,因为整个有向图可能分为两个不连通的部分),直到所有点被遍历。
由于每个顶点只访问过一次,每条边也只访问过一次,我们就可以在O(n+m)的时间内求出有向图的强连通分量。但是,这么做的原理是什么呢?
Tarjan算法的操作原理如下:
- Tarjan算法基于定理:在任何深度优先搜索中,同一强连通分量内的所有顶点均在同一棵深度优先搜索树中。也就是说,强连通分量一定是有向图的某个深搜树子树。
- 可以证明,当一个点既是强连通子图Ⅰ中的点,又是强连通子图Ⅱ中的点,则它是强连通子图Ⅰ∪Ⅱ中的点。
- 这样,我们用low值记录该点所在强连通子图对应的搜索子树的根节点的Dfn值。注意,该子树中的元素在栈中一定是相邻的,且根节点在栈中一定位于所有子树元素的最下方。
- 强连通分量是由若干个环组成的。所以,当有环形成时(也就是搜索的下一个点已在栈中),我们将这一条路径的low值统一,即这条路径上的点属于同一个强连通分量。
- 如果遍历完整个搜索树后某个点的dfn值等于low值,则它是该搜索子树的根。这时,它以上(包括它自己)一直到栈顶的所有元素组成一个强连通分量。
红字部分需要在编程中注意,当递归返回上一层时,一定要检查当前节点和栈顶节点的low值,如果当前节点大于栈顶节点,则把栈顶节点的low值赋给当前节点。
OK,了解了Tarjan算法,再回到本问题,给定一个连通的无向图G,至少要添加几条边,才能使其变为双连通图。
Targan原本求的是有向图的强连通分量,这里我们变换一下思想,如果把一个有向图的强连通分量的每条边都变成无向边,则这个强连通分量就是一个双连通图,即任何一点都有到其他点的两条路径。
所以我们要做的就是将原本的无向图变成双向连接的有向图,用邻接矩阵很容易实现,然后在图中用Tarjan算法求出所有的强连通分量,在这里其实就是双连通子图。
求出所有的双连通子图后,我们要做的就是缩点,其实并没必要把点都合到一起,只需要找个数组表示一下, 在一个子图里面的点编号相同就可以, 参考下图。
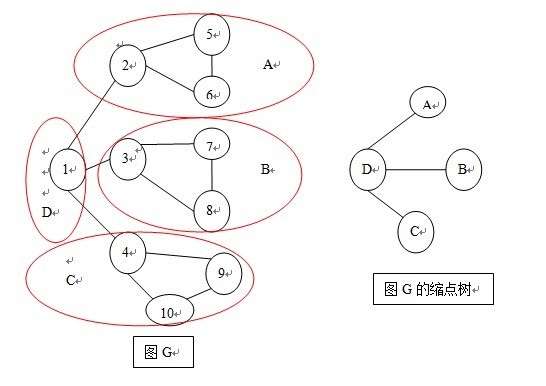
其中Low[4]=Low[9]=Low[10]
Low[3]=Low[7]=Low[8]
Low[2]=Low[5]=Low[6]
Low[1]独自为政....
把Low值相同的点划分为一类,每一类就是一个【边双连通分量】,也就是【缩点】了,不难发现,连接【缩点】之间的边,都是图G的桥,那么我们就得到了上右图以缩点为结点,已桥为树边所构造成的树。
问题再次被转化为“至少在缩点树上增加多少条树边,使得这棵树变为一个双连通图”。
首先知道一条等式:
若要使得任意一棵树,在增加若干条边后,变成一个双连通图,那么
至少增加的边数 =( 这棵树总度数为1的结点数 + 1 )/ 2
(证明就不证明了,自己画几棵树比划一下就知道了)
那么我们只需求缩点树中总度数为1的结点数(即叶子数)有多少就可以了。换而言之,我们只需求出所有缩点的度数,然后判断度数为1的缩点有几个,问题就解决了。
求出所有缩点的度数的方法
两两枚举图G的直接连通的点,只要这两个点不在同一个【缩点】中,那么它们各自所在的【缩点】的度数都+1。注意由于图G是无向图,这样做会使得所有【缩点】的度数都是真实度数的2倍,必须除2后再判断叶子。
好了,上代码:
#include <cstdio> #include <iostream> #include <memory.h> #include <stack> #include <set> #include <cstdlib> #include <climits> #include <vector> using namespace std; //F 农场数, R 路径数, point1路径起点, point2路径终点 int F, R, point1, point2; //计算遍历次序 int count; //每个点可达到的最早被遍历的点的次序 int low[5001]; //每个点被遍历到的次序 int dfn[5001]; //每个点所在的缩点组 int group[5001]; //每个点是否在栈中 bool inStack[5001]; //图的邻接矩阵 bool graph[5001][5001]; //栈 stack<int> pointStack; //缩点编号 int nodeID; //缩点数 int nodeCount; void tarjan(int src, int father) { for(int i=1; i<=F; ++i) { //去掉父节点的影响 if(i!=father && graph[src][i] == 1) { if(inStack[i]) { low[src] = min(low[src],low[i]); } //already pop else if(dfn[i]!=0) { continue; } else { pointStack.push(i); inStack[i] = true; low[i] = ++count; dfn[i] = count; tarjan(i, src); } } } //当前点的子节点都遍历过以后,一定要比较一下栈顶low值 low[src] = low[pointStack.top()]; if(low[src] == dfn[src]) { //merge point int tmp; do { tmp = pointStack.top(); pointStack.pop(); inStack[tmp] = false; group[tmp] = nodeID; } while(tmp != src); nodeID++; nodeCount++; } } int getMinPath() { //统计每个缩点的边数 int *count = new int[nodeCount+1](); for(int i=1; i<=F; ++i) { for(int j=1; j<=F; ++j) { //遍历所有的边,如果边的两个节点不在一个缩点组里面 if(graph[i][j] == true && group[i] != group[j]) { ++count[group[i]]; ++count[group[j]]; } } } int ret = 0; for(int i=1; i<=nodeCount; ++i) { if(count[i]/2 == 1) ++ret; } return (ret+1)/2; } int main(int argc, char** argv) { while (scanf("%d %d", &F, &R) != EOF) { memset(low,0,sizeof(low)); memset(dfn,0,sizeof(dfn)); memset(group,0,sizeof(group)); memset(inStack,false,sizeof(inStack)); memset(graph,false,sizeof(graph)); nodeCount = 0; for(int i=0; i<R; ++i) { cin >> point1 >> point2; graph[point1][point2] = 1; graph[point2][point1] = 1; } //将第一个点加入栈中 pointStack.push(1); inStack[1] = true; low[1] = 1; dfn[1] = 1; count = 1; nodeID = 1; tarjan(1,-1); cout << getMinPath() << endl; } return 0; }