1、集合的安全性问题
ArrayList、HashSet、HashMap不是线程安全的
Vector、HashTable是线程安全的
区别就是源码中各自核心方法是否添加了synchronized关键字
Collections工具类提供了相关的API,可以让上面那三个不安全的集合变为安全的
Colllections.synchronizedCollection(c)
Colllections.synchronizedList(list)
Colllections.synchronizedMap(m)
Colllections.synchronizedSet(s)
2、ArrayList内部用什么实现的(是如何实现数组的添加和删除的,因为数组在创建的时候长度是固定的,那么就有个问题我们往ArrayList中不断的添加对象,它是如何管理这些数组呢)?
ArrayList内部使用Object[]实现的。接下来我们分别分析ArrayList的构造、add、remove、clear方法的实现原理。
一、构造函数
1)空参构造

2) 带参构造1

3)带参构造2
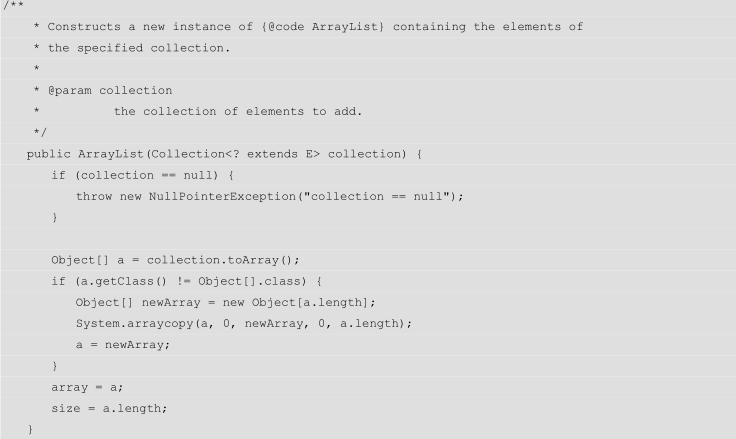
如果调用构造函数的时候传入了一个Collection的子类
①判断该集合是否为null,为null则抛出空指针异常
②如果不是则将该集合转换为数组a。然后将数组赋值为成员变量array,将该数组的长度作为成员变量size。这里面它先判断a.getClass是否等于Object[].class(为什么要加这个判断?),toArray方法是Collection接口定义的,因此所有的子类都有这样的方法,list集合的toArray和Set集合的toArray返回的都是Object[]数组。
二、add方法
add方法有两个重载,这里只研究最简单的那个

三、remove方法

四、clear方法

4、并发集合和普通集合如何区别?
并发集合常见的有ConcurrentMap、ConcurrentLinkedQuene、ConcurrentLinkedDeque等。并发集合位于java.util.concurrent包下,是jdk1.5之后才有的。(concurrent:并存的,同时发生的)
在Java中有普通集合、同步(线程安全)的集合、并发集合。普通集合通常性能最高,但是不保证多线程的安全性和并发的可靠性。线程安全集合仅仅是给集合添加了synchronized同步锁,严重牺牲了性能,而且对并发的效率就更低了(并发时的阻塞影响过了效率),并发集合则通过复杂的策略(分段锁、更好的算法)不仅保证了多线程的安全又提高了并发时的效率。
参考阅读: ConcurrentHashMap是线程安全的HashMap的实现,默认构造同样有initialCapacity和loadFactor属性,不过还多了一个concurrentLevel属性,三属性默认值分别为16、0.75、以及16。其内部使用锁分段技术,维持这锁segment的数组,在segment数组中又存放着Entity[]数组,内部hash算法将数据较均匀分布在不同锁中。
put操作:并没有在此方法上加上synchronized,首先对key.hashcode进行hash操作,得到key的hash值。hash操作的算法和map也不同,根据此hash值计算并获取对应的数组中的Segment对象(继承自ReentrantLock(可重入锁)),接着调用此Segment对象的put方法来完成当前操作。
ConcurrentHashMap基于concurrentLevel划分出了多个Segment来对key-value进行存储,从而避免每次put操作都得锁住整个数组。在默认得情况下,最佳情况可允许16个线程并发无阻塞得操作集合对象,尽可能减少并发时得阻塞现象。
get(key):首先对key.hashCode进行hash操作,基于其值找到对应的Segment对象,调用其get方法来完成当前操作。而Segment得get操作首先通过hash值和数组大小减1的值进行按位与操作来获取数组上对应位置的HashEntry。在这个步骤中,可能会因为对象大小的改变,以及数组上对应位置的HashEntry产生不一致性,那么ConcurrentHashMap是如何保证的?
对象数组大小的改变只有在put操作时有可能发生,由于HashEntry对象数组对应的变量时volatile类型的,因此可以保证HashEntry对象数组大小发生改变,读操作可看到最新的对象数组大小。
在获取到了HashEntry对象后,怎么能保证它及其next属性构成的链表上的对象不会改变呢?这点ConcurrentHashMap采用了一个简单的方式,即HashEntry对象中的hash、key、next属性都是final的,这也就意味着没办法插入一个HashEntry对象到基于next属性构成的链表中间或末尾。这样就可以保证当获取到HashEntry对象后,其基于next属性构建的链表是不会发生变化的。
ConcurrentHashMap默认情况下将数据分为16个段进行存储,并且16个段分别持有各自不同的锁Segment,锁仅用于put和remove等改变集合对象的操作,基于volatile(易变的、无定性的、无常性的)(易变性变量:是说这变量可能会被意想不到的改变,这样,编译器就不会去假设这个变量的值了。指令关键字,确保本条指令不会因编译器的优化而省略)及HashEntry链表的不变性实现了读取的不加锁。这些方式使得ConcurrentHashMap能够保持极好的并发支持,尤其时对于读写比插入和删除频繁的Map而言,而它采用的这些方法也可谓是对于Java内存模型、并发机制深刻掌握的体现。