一.全站数据的爬取(手动)
- yield scrapy.Request(url,callback):callback回调一个函数用于数据解析
# 爬取阳光热线前五页数据
import scrapy from sunLinePro.items import SunlineproItem class SunSpider(scrapy.Spider): name = 'sun' # allowed_domains = ['www.xxx.com'] start_urls = ['http://wz.sun0769.com/index.php/question/questionType?type=4&page='] #通用的url模板(不可以修改) url = 'http://wz.sun0769.com/index.php/question/questionType?type=4&page=%d' page = 1 def parse(self, response): print('--------------------------page=',self.page) tr_list = response.xpath('//*[@id="morelist"]/div/table[2]//tr/td/table//tr') for tr in tr_list: title = tr.xpath('./td[2]/a[2]/text()').extract_first() status = tr.xpath('./td[3]/span/text()').extract_first() item = SunlineproItem() item['title'] = title item['status'] = status yield item if self.page < 5: #手动对指定的url进行请求发送 count = self.page * 30 new_url = format(self.url%count) self.page += 1 # 手动对指定的url进行请求发送 yield scrapy.Request(url=new_url,callback=self.parse)
二.如何进行post请求发送 和cookie处理
1.post请求的发送
- post请求的发送:
- 重写父类的start_requests(self)方法
- 在该方法内部只需要调用yield scrapy.FormRequest(url,callback,formdata)
import scrapy class PostdemoSpider(scrapy.Spider): name = 'postDemo' # allowed_domains = ['www.xxx.com'] #https://fanyi.baidu.com/sug start_urls = ['https://fanyi.baidu.com/sug'] #父类方法,就是将start_urls中的列表元素进行get请求的发送 # def start_requests(self): # for url in self.start_urls: # yield scrapy.Request(url=url,callback=self.parse) def start_requests(self): for url in self.start_urls: data = { 'kw':'cat' } #post请求的手动发送使用的是FormRequest yield scrapy.FormRequest(url=url,callback=self.parse,formdata=data) def parse(self, response): print(response.text)
2.cookie的处理
- cookie处理:scrapy默认情况下会自动进行cookie处理
三.请求传参
请求传参: - 使用场景:如果使用scrapy爬取的数据没有在同一张页面中,则必须使用请求传参 - 编码流程: - 需求:爬取的是首页中电影的名称和详情页中电影的简介(全站数据爬取) - 基于起始url进行数据解析(parse) - 解析数据 - 电影的名称 - 详情页的url - 对详情页的url发起手动请求(指定的回调函数parse_detail),进行请求传参(meta) meta传递给parse_detail这个回调函数 - 封装一个其他页码对应url的一个通用的URL模板 - 在for循环外部,手动对其他页的url进行手动请求发送(需要指定回调函数==》parse) - 定义parse_detail回调方法,在其内部对电影的简介进行解析。解析完毕后,需要将解析到的电影名称 和电影的简介封装到同一个item中。 - 接收传递过来的item,并且将解析到的数据存储到item中,将item提交给管道
# -*- coding: utf-8 -*- import scrapy from moviePro.items import MovieproItem class MovieSpider(scrapy.Spider): name = 'movie' # allowed_domains = ['www.xxx.com'] start_urls = ['https://www.4567tv.tv/frim/index1.html'] #通用的url模板只适用于非第一页 url = 'https://www.4567tv.tv/frim/index1-%d.html' page = 2 #电影名称(首页),简介(详情页) def parse(self, response): li_list = response.xpath('/html/body/div[1]/div/div/div/div[2]/ul/li') for li in li_list: name = li.xpath('./div/a/@title').extract_first() detail_url = 'https://www.4567tv.tv'+li.xpath('./div/a/@href').extract_first() item = MovieproItem() item['name'] = name #对详情页的url发起get请求 #请求传参:meta参数对应的字典就可以传递给请求对象中指定好的回调函数 yield scrapy.Request(url=detail_url,callback=self.detail_parse,meta={'item':item}) if self.page <= 5: new_url = format(self.url%self.page) self.page += 1 yield scrapy.Request(url=new_url,callback=self.parse)
#解析详情页的页面数据 def detail_parse(self,response): #回调函数内部通过response.meta就可以接收到请求传参传递过来的字典 item = response.meta['item'] desc = response.xpath('/html/body/div[1]/div/div/div/div[2]/p[5]/span[2]/text()').extract_first() item['desc'] = desc yield item

四.中间件
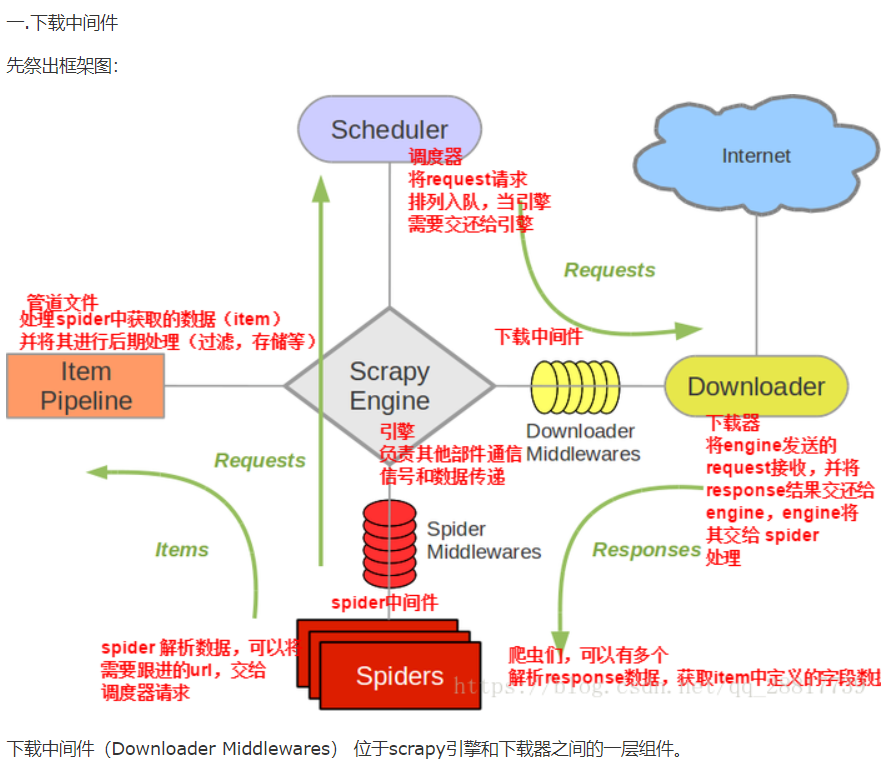
- 下载中间件的作用:批量拦截整个工程中发起的所有请求和响应 - 拦截请求: - UA伪装: - 代理ip: - 拦截响应:
1.UA池 和代理池
UA池:User-Agent池 - 作用:尽可能多的将scrapy工程中的请求伪装成不同类型的浏览器身份。
代理池:ip代理
- 作用:尽可能多的将scrapy工程中的请求的IP设置成不同的。
①在middlewares.py 文件中
import random #批量拦截所有的请求和响应 class MiddlewearproDownloaderMiddleware(object): #UA池 user_agent_list = [ "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 " "(KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1", "Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 " "(KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 " "(KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 " "(KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6", "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 " "(KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1", "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 " "(KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5", "Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 " "(KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 " "(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 " "(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 " "(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 " "(KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 " "(KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 " "(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 " "(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 " "(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 " "(KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3", "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 " "(KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24", "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 " "(KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24" ] #代理池 PROXY_http = [ '153.180.102.104:80', '195.208.131.189:56055', ] PROXY_https = [ '120.83.49.90:9000', '95.189.112.214:35508', ] #拦截正常请求:request就是该方法拦截到的请求,spider就是爬虫类实例化的一个对象 def process_request(self, request, spider): print('this is process_request!!!') #UA伪装 request.headers['User-Agent'] = random.choice(self.user_agent_list) return None #拦截所有的响应 def process_response(self, request, response, spider): return response #拦截发生异常的请求对象 def process_exception(self, request, exception, spider): print('this is process_exception!!!!') #代理ip的设定 if request.url.split(':')[0] == 'http': request.meta['proxy'] = random.choice(self.PROXY_http) else: request.meta['proxy'] = random.choice(self.PROXY_https) #将修正后的请求对象重新进行请求发送 return request
②在settings.py文件中

2.拦截响应和 selenium的使用
拦截响应:
修改 中间件文件的 process_response 函数
selenium 浏览器自动化:
- 爬虫类中定义一个属性bro
- 爬虫类中重写父类的一个方法closed,在该方法中关闭bro
- 在中间件类的process_response中编写selenium自动化的相关操作
示例:爬取 网易新闻 数据
①在 爬虫文件中
# -*- coding: utf-8 -*- import scrapy from wangyiPro.items import WangyiproItem from selenium import webdriver class WangyiSpider(scrapy.Spider): name = 'wangyi' # allowed_domains = ['www.xxx.com'] start_urls = ['https://news.163.com/'] #浏览器实例化的操作只会被执行一次 bro = webdriver.Chrome(executable_path='chromedriver.exe') urls = []#最终存放的就是五个板块对应的url def parse(self, response): li_list = response.xpath('//*[@id="index2016_wrap"]/div[1]/div[2]/div[2]/div[2]/div[2]/div/ul/li') for index in [3,4,6,7,8]: li = li_list[index] new_url = li.xpath('./a/@href').extract_first() self.urls.append(new_url) #是五大板块对应的url进行请求发送 yield scrapy.Request(url=new_url,callback=self.parse_news) #是用来解析每一个板块对应的新闻数据(新闻的标题) def parse_news(self,response): div_list = response.xpath('//div[@class="ndi_main"]/div') for div in div_list: title = div.xpath('./div/div[1]/h3/a/text()').extract_first() news_detail_url = div.xpath('./div/div[1]/h3/a/@href').extract_first() #实例化item对象将解析到的标题和内容存储到item对象中 item = WangyiproItem() item['title'] = title #对详情页的url进行手动请求发送以便回去新闻的内容 yield scrapy.Request(url=news_detail_url,callback=self.parse_detail,meta={'item':item}) def parse_detail(self,response): item = response.meta['item'] #通过response解析出新闻的内容 content = response.xpath('//div[@id="endText"]//text()').extract() content = ''.join(content) item['content'] = content yield item def closed(self,spider): print('爬虫整体结束!!!') self.bro.quit()
②在 中间件文件 中
# -*- coding: utf-8 -*- # Define here the models for your spider middleware # # See documentation in: # https://doc.scrapy.org/en/latest/topics/spider-middleware.html from scrapy import signals from scrapy.http import HtmlResponse from time import sleep class WangyiproDownloaderMiddleware(object): def process_request(self, request, spider): return None #拦截整个工程中所有的响应对象 def process_response(self, request, response, spider): if request.url in spider.urls: #就要将其对应的响应对象进行处理 #获取了在爬虫类中定义好的浏览器对象 bro = spider.bro bro.get(request.url) bro.execute_script('window.scrollTo(0,document.body.scrollHeight)') sleep(1) bro.execute_script('window.scrollTo(0,document.body.scrollHeight)') sleep(1) #获取携带了新闻数据的页面源码数据 page_text = bro.page_source #实例化一个新的响应对象 new_response = HtmlResponse(url=request.url,body=page_text,encoding='utf-8',request=request) return new_response else: return response def process_exception(self, request, exception, spider): pass
③注意事项
1. 导入浏览器启动文件 2. 修改 settings.py 文件 3,修改 items.py 文件 4,持久化存储式,修改 管道 文件