一.io有几种流?
有两种流:字节流和字符流.
字节流继承自inputstream和outstream。
字符流继承自write和read。
二.Jdbc的开发流程?
JDBC编程的六个步骤:
1)加载驱动程序。
2)建立连接。
3)创建语句。
4)执行语句。
5)处理ResultSet。
(6)关闭连接
public class UseJdbc { public void Jdbc() { try { Class.forName("com.mysql.cj.jdbc.Driver");//加载驱动程序 System.out.println("Ok"); //建立连接 Connection connection = DriverManager.getConnection("jdbc:mysql://localhost/Contacts?serverTimezone=UTC", "root", "Cc229654512"); System.out.println("Database connected"); //创建语句 Statement statement = connection.createStatement(); //用executeQuery执行SQL查询语句 ResultSet resultSet = statement.executeQuery("select Name, PhoneNumber, Email, QQ, Note from Contacts"); //获取并输出返回结果 while (resultSet.next()) { System.out.println(resultSet.getString(1) + " " + resultSet.getString(2) + " " + resultSet.getString(3) + " " + resultSet.getString(4) + " " + resultSet.getString(5)); } //关闭连接 connection.close(); } catch (Exception ex) { ex.printStackTrace(); } } }
三.Nginx负载权重的分配?
我们这里讨论nginx的两种负载均衡方式 轮询加权(也可以不加权,就是1:1负载)和ip_hash(同一ip会被分配给固定的后端服务器,解决session问题) 这个配置文件,我们可以写到nginx.conf里面(如果只有一个web集群),如果有多个web集群,最好写到vhosts里面,以虚拟主机的方式,这里我写到nginx.conf里面 第一种配置:加权轮询,按服务器的性能给予权重,本例是1:2分配 upstream lb { server 192.168.196.130 weight=1 fail_timeout=20s; server 192.168.196.132 weight=2 fail_timeout=20s; } server { listen 80; server_name safexjt.com www.safexjt.com; index index.html index.htm index.php; location / { proxy_pass http://lb; proxy_next_upstream http_500 http_502 http_503 error timeout invalid_header; include proxy.conf; } } 第二种配置:ip_hash轮询方法,不可给服务器加权重 upstream lb { server 192.168.196.130 fail_timeout=20s; server 192.168.196.132 fail_timeout=20s; ip_hash; } server { listen 80; server_name safexjt.com www.safexjt.com; index index.html index.htm index.php; location / { proxy_pass http://lb; proxy_next_upstream http_500 http_502 http_503 error timeout invalid_header; include proxy.conf; } } 方法二 nginx负载均衡基于ip_hash实现session粘帖 1、轮询(默认) 每个请求按时间顺序逐一分配到不同的后端服务器,如果后端服务器down掉,能自动剔除。 upstream backserver { server 192.168.0.14; server 192.168.0.15; } 2、指定权重 指定轮询几率,weight和访问比率成正比,用于后端服务器性能不均的情况。 upstream backserver { server 192.168.0.14 weight=10; server 192.168.0.15 weight=10; } 3、IP绑定 ip_hash 每个请求按访问ip的hash结果分配,这样每个访客固定访问一个后端服务器,可以解决session的问题。 upstream backserver { ip_hash; server 192.168.0.14:88; server 192.168.0.15:80; } 4、fair(第三方) 按后端服务器的响应时间来分配请求,响应时间短的优先分配。 upstream backserver { server server1; server server2; fair; } 5、url_hash(第三方) 按访问url的hash结果来分配请求,使每个url定向到同一个后端服务器,后端服务器为缓存时比较有效。 upstream backserver { server squid1:3128; server squid2:3128; hash $request_uri; hash_method crc32; } 在需要使用负载均衡的server中增加 proxy_pass http://backserver/; upstream backserver{ ip_hash; server 127.0.0.1:9090 down; (down 表示单前的server暂时不参与负载) server 127.0.0.1:8080 weight=2; (weight 默认为1.weight越大,负载的权重就越大) server 127.0.0.1:6060; server 127.0.0.1:7070 backup; (其它所有的非backup机器down或者忙的时候,请求backup机器) } max_fails :允许请求失败的次数默认为1.当超过最大次数时,返回proxy_next_upstream 模块定义的错误 fail_timeout:max_fails次失败后,暂停的时间
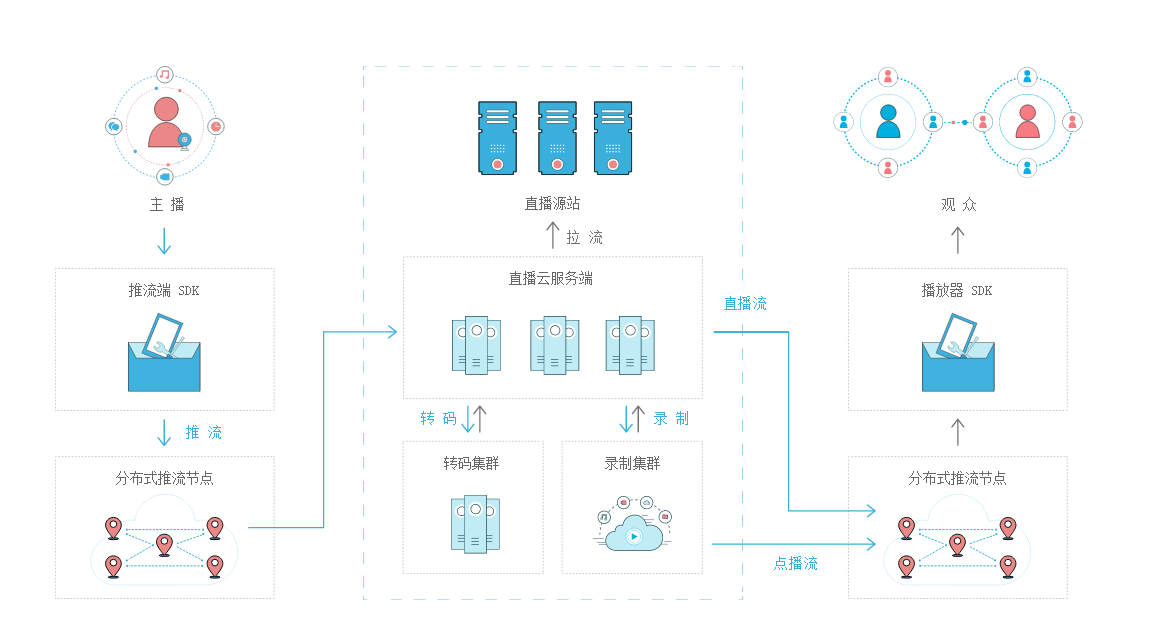
四、视频的推流与拉流?
推流,指的是把采集阶段封包好的内容传输到服务器的过程。
拉流是指服务器已有直播内容,用指定地址进行拉取的过程。
 五。Springboot的启动方式以及springboot项目会存放在Tomcat中吗?
五。Springboot的启动方式以及springboot项目会存放在Tomcat中吗?
启动方式有两种:第一种在springbootapplication中运行run as java application
第二种 运行run as spring boot app
总结下SpringBoot应用部署到Tomcat下的配置方法用于备忘也方便遇到同样问题的朋友 将打包方式改成war 这个没啥好说的, 肯定要改成war 配置嵌入Tomcat中的方式 这里有两种方式可选择: 方式一:用spring-boot内置的tomcat库, 并指定你要部署到Tomcat的版本 <properties> <tomcat.version>7.0.69</tomcat.version> </properties> <dependency> <groupId>org.apache.tomcat</groupId> <artifactId>tomcat-juli</artifactId> <version>${tomcat.version}</version> </dependency> 方式二:不用spring-boot内置的tomcat库(强烈推荐这种方式!!) <!-- 打war包时加入此项, 告诉spring-boot tomcat相关jar包用外部的,不要打进去 --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-tomcat</artifactId> <scope>provided</scope> </dependency> maven-war-plugin (可选) 与maven-resources-plugin类似,当你有一些自定义的打包操作, 比如有非标准目录文件要打到war包中或者有配置文件引用了pom中的变量。 具体用法参见官方文档:http://maven.apache.org/components/plugins/maven-war-plugin/
六。线程中的sleep和wait的区别?
sleep与wait最主要的区别在于,sleep与wait都可以使线程等待,但sleep不会释放资源而wait会释放资源。 还有就是,wait方法只能在同步块或者同步方法中执行。 怎么理解这句话? 这里有个例子:我登录图书管理系统订了一本 《疯狂JAVA讲义》,当我去到图书管排队借书,到了借书窗口的时候,我告诉管理员我们的名字和预定的书,然后管理员查询到我预订的信息,然后安排助理去预定的图书中找这本书,这个时候,如果我用的是sleep模式,我就一直站在窗口前,直到管理员给我这本书。如果我用的是wait模式,那么我就让出位置给在排队的后面的同学,到旁边的椅子上等待,直到通知我,我要的书找到了,我再回到队伍中排队取票。 这样是不是明白对了? 下面来验证一下,sleep是否不会释放资源而wait会释放资源。 复制代码 public class ThreadTest { public static void main(String[] args) throws InterruptedException { new Thread(new Thread1()).start(); synchronized (ThreadTest.class) { System.out.println("Main Thread go to sleep : currenttime-->"+System.currentTimeMillis()); //sleep过程不会释放资源 Thread.sleep(10000); } System.out.println("Main Thread get up : currenttime-->"+System.currentTimeMillis()); new Thread(new Thread2()).start(); System.out.println("Main Thread over"); } static class Thread1 implements Runnable{ @Override public void run() { System.out.println("Thread1 is ready :currenttime-->"+System.currentTimeMillis()); //因为sleep不会释放资源,所以在主线程sleep结束前,是不能取得资源的锁,而是在等待 synchronized (ThreadTest.class) { System.out.println("Thread1 is running :currenttime-->"+System.currentTimeMillis()); System.out.println("Thread1 wait :currenttime-->"+System.currentTimeMillis()); try { ThreadTest.class.wait(); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println("Thread1 is over "); } } } static class Thread2 implements Runnable{ @Override public void run() { System.out.println("Thread2 is ready :currenttime-->"+System.currentTimeMillis()); synchronized (ThreadTest.class){ System.out.println("Thread2 is running :currenttime-->"+System.currentTimeMillis()); System.out.println("Thread2 notify :currenttime-->"+System.currentTimeMillis()); ThreadTest.class.notify(); System.out.println("Thread2 is over"); } } } } 复制代码 输出结果: 复制代码 Main Thread go to sleep : currenttime-->1400232812969 Thread1 is ready :currenttime-->1400232812969 Main Thread get up : currenttime-->1400232822970 Thread1 is running :currenttime-->1400232822970 Thread1 wait :currenttime-->1400232822970 Main Thread over Thread2 is ready :currenttime-->1400232822972 Thread2 is running :currenttime-->1400232822972 Thread2 notify :currenttime-->1400232822972 Thread2 is over Thread1 is over 复制代码 由结果可以看出,当主线程sleep10s中的过程,Thread1仅仅处于ready状态,而一直没有获取到ThreadTest.class的锁,原因在于,主线程在sleep的之前已经获取了该资源的锁,这也验证了在用sleep()的时候不会释放资源。 当主线程sleep完之后,Thread1获取到了ThreadTest.class的锁,然后调用了wait方法(wait方法是Object的静态方法)。在调用该方法后,Thread2启动,且顺利获取到ThreadTest.class的锁,这也验证了在用wait()方法的时候会释放资源。 最后,在Thread2中调用notify方法(notify方法也是Object的静态方法,作用是唤醒在同步监视器上等待的一个线程),然后我们看到 "Thread1 is over"。wait 方法与 notify 方法或notifyAll方法 搭配使用,来协调线程运行。如果我们把Thread2中的notify方法去掉,会发现最后Thread1并没有再次运行,也就不会打印"Thread1 is over"。
七.简述collection中的集合以及区别,map的种类和区别?
1.ArrayList: 元素单个,效率高,多用于查询
2.Vector: 元素单个,线程安全,多用于查询
3.LinkedList:元素单个,多用于插入和删除
4.HashMap: 元素成对,元素可为空
5.HashTable: 元素成对,线程安全,元素不可为空
arraylist和linklist的区别:
因为数组有索引(角标)所以ArrayList的查询速度快,而添加删除元素速度稍慢。因为,你每删除或者添加一个元素,你都要移动所添加或删除元素后面的所有数据,该集合是线程不同步的(线程不安全)。
Linklist底层是通过链表实现的,他的特点是查询速度慢,因为他没有角标都是上一个原素指向下一个元素。查询一个元素要遍历整个集合。但是他的添加和删除比arraylist快。
hashset和treeset的区别:
hashset:不能保证元素的排列顺序,顺序有可能发生变化 。不是同步的(线程不安全)。集合元素可以是null,但只能放入一个null。
treeset:TreeSet 是二差树实现的,Treeset中的数据是自动排好序的,不允许放入null值.
hashmap和hashtable的区别:hashmap线程不安全,可以接受null(hashmap可以接受null的键值(key)和值(value)而hashtable则不行),hashtable线程安全。
八。Redis和mongodb的区别?
Redis和MongoDB都是NoSQL(非关系性数据库)。redis是通过key和value的形式存放在内存中,Redis有五种数据类型:string(字符串)、 list(双向链表)、dict(hash表)、set(集合)、zset(排序set)。MongoDB是面像文档流形式。
九。项目的分布式dubbo和kafka ?
Dubbo是Alibaba开源的分布式服务框架,它最大的特点是按照分层的方式来架构,使用这种方式可以使各个层之间解耦合(或者最大限度地松耦合)。从服务模型的角度来看,Dubbo采用的是一种非常简单的模型,要么是提供方提供服务,要么是消费方消费服务,所以基于这一点可以抽象出服务提供方(Provider)和服务消费方(Consumer)两个角色
Dubbo的总体架构,如图所示:
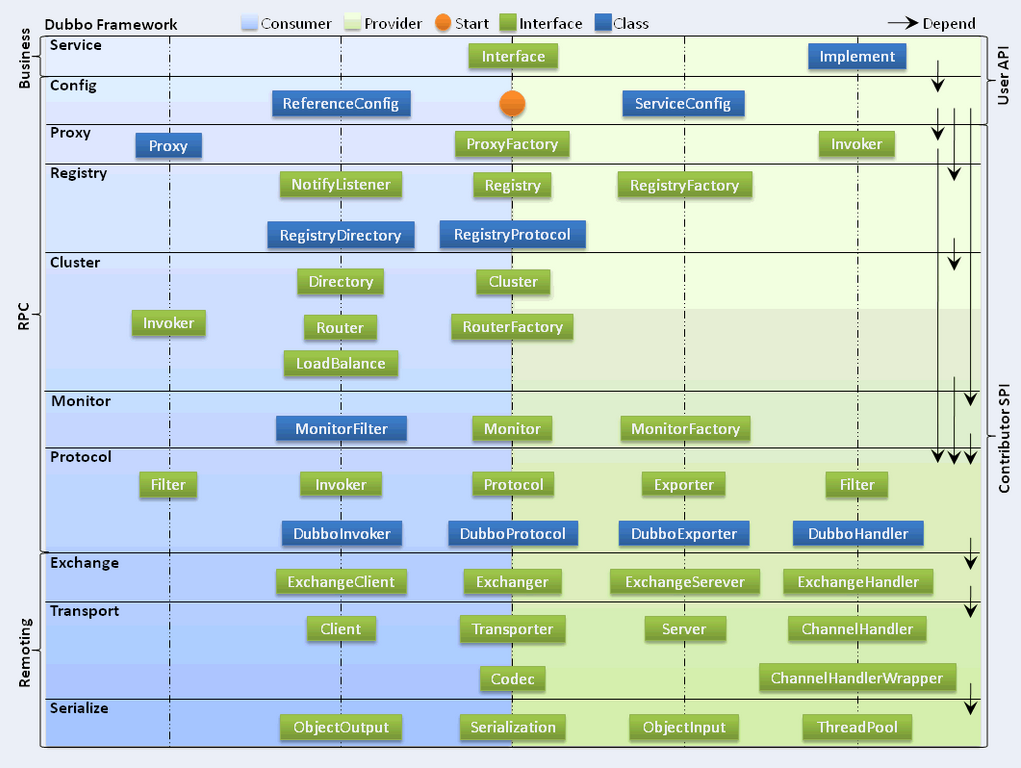
Dubbo框架设计一共划分了10个层,而最上面的Service层是留给实际想要使用Dubbo开发分布式服务的开发者实现业务逻辑的接口层。图中左边淡蓝背景的为服务消费方使用的接口,右边淡绿色背景的为服务提供方使用的接口, 位于中轴线上的为双方都用到的接口。 下面,结合Dubbo官方文档,我们分别理解一下框架分层架构中,各个层次的设计要点:
- 服务接口层(Service):该层是与实际业务逻辑相关的,根据服务提供方和服务消费方的业务设计对应的接口和实现。
- 配置层(Config):对外配置接口,以ServiceConfig和ReferenceConfig为中心,可以直接new配置类,也可以通过spring解析配置生成配置类。
- 服务代理层(Proxy):服务接口透明代理,生成服务的客户端Stub和服务器端Skeleton,以ServiceProxy为中心,扩展接口为ProxyFactory。
- 服务注册层(Registry):封装服务地址的注册与发现,以服务URL为中心,扩展接口为RegistryFactory、Registry和RegistryService。可能没有服务注册中心,此时服务提供方直接暴露服务。
- 集群层(Cluster):封装多个提供者的路由及负载均衡,并桥接注册中心,以Invoker为中心,扩展接口为Cluster、Directory、Router和LoadBalance。将多个服务提供方组合为一个服务提供方,实现对服务消费方来透明,只需要与一个服务提供方进行交互。
- 监控层(Monitor):RPC调用次数和调用时间监控,以Statistics为中心,扩展接口为MonitorFactory、Monitor和MonitorService。
- 远程调用层(Protocol):封将RPC调用,以Invocation和Result为中心,扩展接口为Protocol、Invoker和Exporter。Protocol是服务域,它是Invoker暴露和引用的主功能入口,它负责Invoker的生命周期管理。Invoker是实体域,它是Dubbo的核心模型,其它模型都向它靠扰,或转换成它,它代表一个可执行体,可向它发起invoke调用,它有可能是一个本地的实现,也可能是一个远程的实现,也可能一个集群实现。
- 信息交换层(Exchange):封装请求响应模式,同步转异步,以Request和Response为中心,扩展接口为Exchanger、ExchangeChannel、ExchangeClient和ExchangeServer。
- 网络传输层(Transport):抽象mina和netty为统一接口,以Message为中心,扩展接口为Channel、Transporter、Client、Server和Codec。
- 数据序列化层(Serialize):可复用的一些工具,扩展接口为Serialization、 ObjectInput、ObjectOutput和ThreadPool。
-
Dubbo支持多种协议,如下所示:
- Dubbo协议
- Hessian协议
- HTTP协议
- RMI协议
- WebService协议
- Thrift协议
- Memcached协议
- Redis协议
dubbo理论参考资料:http://shiyanjun.cn/archives/325.html
dubbo配置参考资料一:http://blog.csdn.net/noaman_wgs/article/details/70214612
dubbo配置参考资料二:https://www.cnblogs.com/Javame/p/3632473.html
Kafka是由LinkedIn开发的一个分布式的消息系统,使用Scala编写,它以可水平扩展和高吞吐率而被广泛使用。目前越来越多的开源分布式处理系统如Cloudera、Apache Storm、Spark都支持与Kafka集成。
kafka 相关名词解释如下:

1.producer: 消息生产者,发布消息到 kafka 集群的终端或服务。 2.broker: kafka 集群中包含的服务器。 3.topic: 每条发布到 kafka 集群的消息属于的类别,即 kafka 是面向 topic 的。 4.partition: partition 是物理上的概念,每个 topic 包含一个或多个 partition。kafka 分配的单位是 partition。 5.consumer: 从 kafka 集群中消费消息的终端或服务。 6.Consumer group: high-level consumer API 中,每个 consumer 都属于一个 consumer group,每条消息只能被 consumer group 中的一个 Consumer 消费,但可以被多个 consumer group 消费。 7.replica: partition 的副本,保障 partition 的高可用。 8.leader: replica 中的一个角色, producer 和 consumer 只跟 leader 交互。 9.follower: replica 中的一个角色,从 leader 中复制数据。 10.controller: kafka 集群中的其中一个服务器,用来进行 leader election 以及 各种 failover。 12.zookeeper: kafka 通过 zookeeper 来存储集群的 meta 信息。
kafka的参考资料:https://www.cnblogs.com/cyfonly/p/5954614.html
十。Spring中bean的生命周期?
1.生命周期流程图:
Spring Bean的完整生命周期从创建Spring容器开始,直到最终Spring容器销毁Bean,这其中包含了一系列关键点。


若容器注册了以上各种接口,程序那么将会按照以上的流程进行。下面将仔细讲解各接口作用。
2.各种接口方法分类
Bean的完整生命周期经历了各种方法调用,这些方法可以划分为以下几类:
1、Bean自身的方法 : 这个包括了Bean本身调用的方法和通过配置文件中<bean>的init-method和destroy-method指定的方法
2、Bean级生命周期接口方法 : 这个包括了BeanNameAware、BeanFactoryAware、InitializingBean和DiposableBean这些接口的方法
3、容器级生命周期接口方法 : 这个包括了InstantiationAwareBeanPostProcessor 和 BeanPostProcessor 这两个接口实现,一般称它们的实现类为“后处理器”。
4、工厂后处理器接口方法 : 这个包括了AspectJWeavingEnabler, ConfigurationClassPostProcessor, CustomAutowireConfigurer等等非常有用的工厂后处理器 接口的方法。工厂后处理器也是容器级的。在应用上下文装配配置文件之后立即调用。