第十章、大型数据集的学习
1.很多时候数据是越大越好,所以处理大量数据的时候就会很费时,
但是在确定数据的时候,一定要先想一下,如果只使用部分数据(不是很大),就能替代整体数据,那么还是选择部分数据。
或者这是一个欠拟合的问题,而需要先修改。
2.随机梯度下降stochastic gradient descent :可以通用在使用梯度下降法的算法中。
原来的梯度下降称为Batch gradient descen批处理梯度下降,下图左部

新的算法如右部所示,它的每一步都是只考虑当前的一个数据,theta是在不断的变化,原来的是总数除以m,现在一个个的算,不除以m,相对变化比较快。
但是它的最终结果会停在最值周围,可能永远到不了最值(就是因为它每步只考虑尽可能使当前数据的代价cost最小)。
因为它变化比较快,所以一般只要重复1-10次就能达到好的效果。
计算步骤:
- 使所有数据随机排列(因为在这种方法中,不同的数据排列会得到不同的结果,可能很好,可能很差)
- 梯度下降
3.迷你批处理梯度下降Mini-Batch Gradient Descent


优点:相比批处理梯度下降更快;使用好的向量化(并行处理)比随机梯度下降(一次只处理一个,没有并行性)效果好。(有并行处理能力时最好用)
缺点:多了一个参数b需要选择。(一般经常使用10,b一般在[2,100]之间)
4.检验随机梯度下降是否收敛
在批处理梯度下降中,我们使用的是每步plot那个代价值J,看是否下降;
随机梯度下降以为每步只处理一个数据,所以使用每1000步输出一个平均值的方式查看。
可能的图像及解释:
- 正常情况(红色表示使用小的alpha)

- 正常情况(红色表示每5000步plot一次,蓝色表示每1000步plot一次)

- 讨论(红色表示每5000步plot一次,蓝色表示每1000步plot一次,粉色的表示算法有问题)
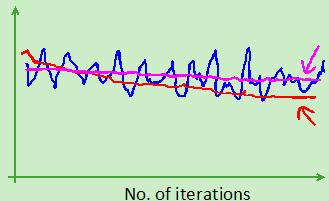
- 异常情况(可能alpha太大造成)

5.随机梯度下降alpha的选择:使用4中的方法选择一个alpha常数。
一种优化的方法是:

优点:在最后会更加靠近最值,因为最后幅度变小了;
缺点:需要确定两个常数的值(解决了一个,出来两个orz)
一般情况下是直接使用不变的alpha,因为也是很接近的,可能优化不了多少。
6.在线学习Online Learning
随机梯度下降算法是每一步只处理一个数据。类似这个思想,对于一个在线的网站,不断地有数据进入,那么可以每产生一个数据,就使用这个数据进行学习,用这个数据来更新参数theta,这个数据使用一次后,就不再使用:

优点:如果用户的习惯变了,那么这个算法同样会慢慢的适应改变,慢慢的修改参数。
7.Map Reduce and Data Parallelism 映射分割和数据并行

原理:就是将可以合并的运算分到多个机器或CPU上分别计算不同部分,之后再进行合并,加快速度。(多台电脑的话,受网络延迟影响)。
如果有多核的话,某些线性代数函数库会自动使用并行技术,不需要Map Reduce。然而不是所有的函数都会使用并行。