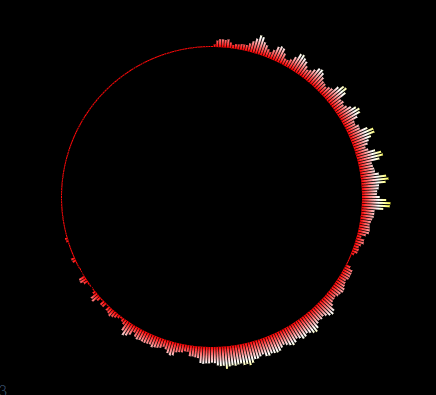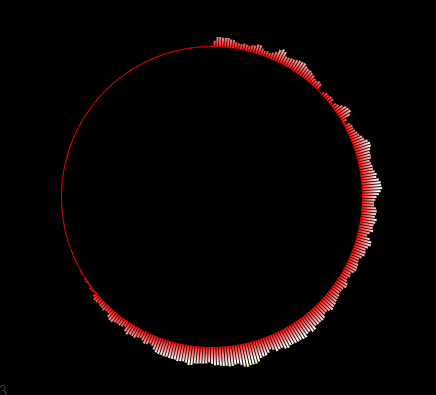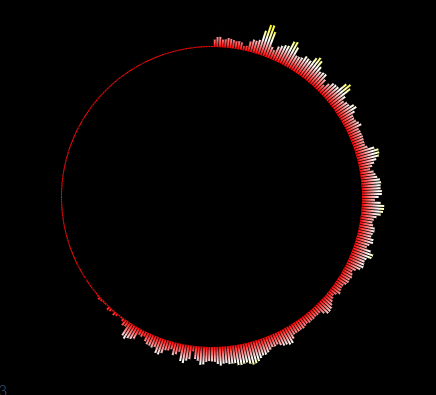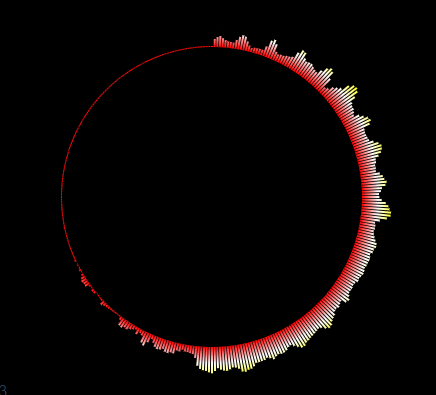
如上图,要实现对FLV直播流中音频的识别,并展示成一个音频相关的动态频谱。
一. 首先了解下什么是声音?
能量波,有频率有振幅,频率高低就是音调,振幅大小就是音量;采样率是对频率采样,采样精度是对幅度采样。
人耳能听到的频率范围是200-20KHz
音频数字化就是将模拟的(连续的)声音波形数字化(离散化),以便利用数字计算机进行处理的过程,主要参数包括采样频率(Sample Rate)和采样数位/采样精度(Quantizing,也称量化级)两个方面,这二者决定了数字化音频的质量。
二. 获取音频的可视化数据
音频的可视化简单来说可以通过反复收集当前音频的时域数据, 并绘制为一个示波器风格的输出(频谱)。
时域(time domain)是描述数学函数或物理信号对时间的关系。例如一个信号的时域波形可以表达信号随着时间的变化。
频域(frequency domain)是指在对函数或信号进行分析时,分析其和频率有关部分,而不是和时间有关的部分[1],和时域一词相对。
一般来说,可视化是通过获取各个时间上的音频数据(通常是振幅或频率),之后运用图像技术将其处理为视觉输出(例如一个图像)来实现的。网页音频接口提供了一个不会改变输入信号的音频节点 AnalyserNode,通过它可以获取声音数据并传递到像 <canvas> 等等一样的可视化工具。
1. 什么是AnalyserNode?以及如何创建AnalyserNode?
nalyserNode? AnalyserNode 赋予了节点可以提供实时频率及时间域分析的信息。它使一个 AudioNode通过音频流不做修改的从输入到输出, 但允许你获取生成的数据, 处理它并创建音频可视化.

AnalyserNode是一个节点名称,并不是html5的API,它可以通过 AudioContext 创建。
var audioCtx = new(window.AudioContext || window.webkitAudioContext)(); var analyser = audioCtx.createAnalyser();
AudioContext 即为本文实现方案的一个重点API,它是html5处理音频的API,MDN中解释如下:
AudioContext接口表示由音频模块连接而成的音频处理图,每个模块对应一个AudioNode。AudioContext可以控制它所包含的节点的创建,以及音频处理、解码操作的执行。做任何事情之前都要先创建AudioContext对象,因为一切都发生在这个环境之中。
总结一下实现方案就是,AudioContext创建一个AnalyserNode节点,通过该节点拿到频谱数据(可以理解为一定范围内的数字),进行图形化显示。
2. 那如何通过AnalyserNode节点获取频谱数据呢?
先上代码:
this.analyser = this.audioCtx.createAnalyser()
this.analyser.fftSize = 1024
...
let array = new Uint8Array(this.analyser.frequencyBinCount) // 创建frequencyBinCount长度的Uint8Array数组,用于存放音频数据
this.analyser.getByteFrequencyData(array) // 将音频数据填充到数组当中
这里的array值即为音频的时域数据数组,数组中的每个数据的最大值为256。
为什么最大值为256?
音频的每个数据占用一个字节,当音频无数据时,array中的值均为0。每一个字节有8位,最大值为2的8次方,即256
再解释几个名词:
1. fftSize(Fast Fourier Transfor 快速傅里叶变换)
AnalyserNode接口的fftSize属性的值是一个无符号长整型的值, 表示(信号)样本的窗口大小。fftSize 属性的值必须是从32到32768范围内的2的非零幂; 其默认值为2048。
2. frequencyBinCount
getByteFrequencyData getByteFrequencyData()方法将当前频率数据复制到传入的Uint8Array(无符号字节数组)中。
至此我们已经获取到可以用于可视化的音频数据数组!音频数据已知,音频数据的最大值已知,即可根据这些绘制出想要的可视化图形。
细心的同学可能发现,以上我们并没有接入任何音频,那哪来的音频数据?
对的,我们还需要接入音频才能拿到进行上面的这些操作。
三. 音频的接入和播放
音频源可以提供一个片段一个片段的音频采样数据(以数组的方式),一般,一秒钟的音频数据可以被切分成几万个这样的片段。这些片段可以是经过一些数学运算得到 (比如
OscillatorNode),也可以是音频或视频的文件读出来的(比如AudioBufferSourceNode和MediaElementAudioSourceNode),又或者是音频流(MediaStreamAudioSourceNode)
音频接入
方式一:createMediaElementSource
MediaElementAudioSourceNode 接口代表着某个由HTML5 <audio> 或 <video> 元素所组成的音频源。
<audio id="audio" controls="" autoplay="" loop="" crossorigin="anonymous" src="./1.mp3"></audio> <script> /* AudioContext.createMediaElementSource() 创建一个MediaElementAudioSourceNode接口来关联HTMLMediaElement. 这可以用来播放和处理来自<video>或<audio> 元素的音频. */ var audio = document.getElementById('audio'); var ctx = new AudioContext(); var analyser = ctx.createAnalyser(); var audioSrc = ctx.createMediaElementSource(audio); ... // 连接到音频分析器,分析频谱 audioSrc.connect(analyser); analyser.connect(ctx.destination); </script>
AudioContext的 destination 属性返回一个 AudioDestinationNode 表示 context 中所有音频(节点)的最终目标节点,一般是音频渲染设备,比如扬声器。
方式二:createBufferSource
function decodeBuffer(arrayBuffer) { audioContext.decodeAudioData(arrayBuffer, function(buffer) { play(buffer); }); } function play(buffer) { var audioBufferSourceNode = audioContext.createBufferSource(); audioBufferSourceNode.connect(analyser); // 用于连接到终端设备进行播放声音 analyser.connect(audioContext.destination); audioBufferSourceNode.buffer = buffer; audioBufferSourceNode.start(); }
两种获取ArrayBuffer的方式一种是fileReader, 一种是XMLHttpRequest。
第一种方式:fileReader
<input id="fileChooser" type="file" /> <script> window.onload = function() { var audioContext = new AudioContext(); var analyser = audioContext.createAnalyser(); analyser.fftSize = 256; var fileChooser = document.getElementById('fileChooser'); fileChooser.onchange = function() { if (fileChooser.files[0]) { loadFile(fileChooser.files[0]); } } function loadFile(file) { var fileReader = new FileReader(); fileReader.onload = function(e) {
var arrayBuffer = e.target.result decodeBuffer(arrayBuffer); } fileReader.readAsArrayBuffer(file); } } </script>
第二种:XHR(也是我获取FLV音频的方式)
getBuffer () { let _this = this // Fetch中的Response.body实现了getReader()方法用于渐增的读取原始字节流 // 处理器函数一块一块的接收响应体,而不是一次性的。当数据全部被读完后会将done标记设置为true。 在这种方式下,每次你只需要处理一个chunk,而不是一次性的处理整个响应体。 let myRequest = new Request(this.config.url) fetch(myRequest, { method: 'GET' }) .then( response => { _this._pump(response.body.getReader()) }, error => { console.error('audio stream fetch Error:', error) } ) .catch((e) => { console.log('e:', e) }) } _pump (reader) { var _this = this return reader.read() .then( ({ value, done }) => { if (done) { _this.debug('Stream reader done') } else { let arrayBuffer = value.buffer ... // 获取下一个chunk _this._pump(reader) } }) .catch((e) => { console.log('[flv audio]read stream:', e) }) }
至此,音频源的接入和播放即可完成,但对于flv的音频流,是不能直接用于 decodeAudioData 的,需要增加adts头部信息方可decode。
四. Flv音频的异步解码
AAC ES流无法直接播放,一般需要封装为ADTS格式才能再次使用,一般是在AAC ES流前添加7个字节的ADTS header。
ES--Elementary Streams (原始流)是直接从编码器出来的数据流,可以是编码过的视频数据流(H.264,MJPEG等),音频数据流(AAC),或其他编码数据流的统称。ES是只包含一种内容的数据流,如只含视频或只含音频等。
什么是ADTS header呢?可以参考这篇
1. 那如何添加ADTS header呢?
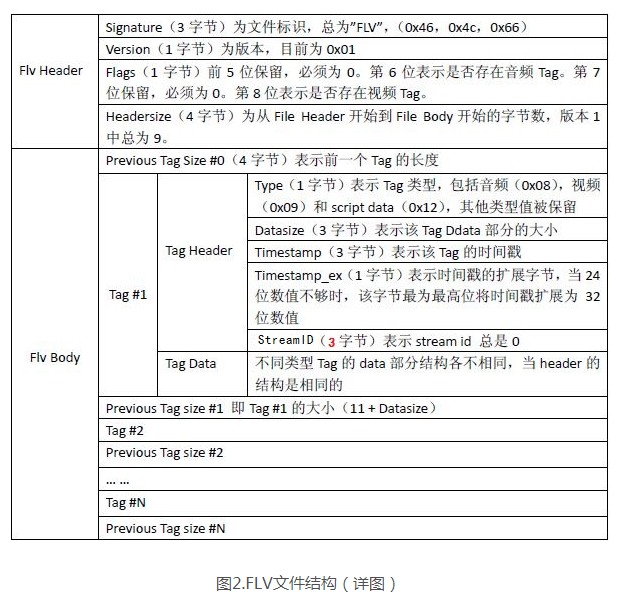
在 视音频编解码学习工程:FLV封装格式分析器 中介绍了FLV的封装格式(如上图),我们可以知道Flv body由若干个tag组成,每个tag包含Tag Header和Tag Data部分,TagData部分又可以分为AudioTagHeader和AudioTagBody,如下:

(图片来自:https://www.jianshu.com/p/d68d6efe8230)
AudioTagHeader包括音频的配置信息有音频编码类型、采样率、精度、类型,当SoundFormat为10的时候,即当音频是aac的时候,AudioTagHeader还包括一个字节的AACPacketType(值为0或1),它表示后面的AudioTagBody是AudioSpecificConfig还是AACframe data,如下图:

(参考:https://www.adobe.com/content/dam/acom/en/devnet/flv/video_file_format_spec_v10.pdf)
AAC sequence header包含了AudioSpecificConfig,有更详细音频的信息,但这种包只出现一次,而且是第一个Audio Tag,因为后面的音频ES流需要该header的ADTS(Audio Data Transport Stream)头。AAC raw则包含音频ES流了,也就是audio payload。
注释:<ui8> (8-Byte Unsigned Integer)
有关AudioSpecificConfig的详细信息可以参考 ISO_IEC_14496 1.6.2.1
ADTS的头信息有7个字节,都可以从 AudioSpecificConfig 中获取,上代码:
/** * 计算adts头部, aac文件需要增加adts头部才能被audioContext decode * @typedef {Object} AdtsHeadersInit * @property {number} audioObjectType * @property {number} samplingFrequencyIndex * @property {number} channelConfig * @property {number} adtsLen * @param {AdtsHeadersInit} init * 添加aac头部参考:https://github.com/Xmader/flv2aac/blob/master/main.js */ getAdtsHeaders (init) { const { audioObjectType, samplingFrequencyIndex, channelConfig, adtsLen } = init const headers = new Uint8Array(7) headers[0] = 0xff // syncword:0xfff 高8bits headers[1] = 0xf0 // syncword:0xfff 低4bits headers[1] |= (0 << 3) // MPEG Version:0 for MPEG-4,1 for MPEG-2 1bit headers[1] |= (0 << 1) // Layer:0 2bits headers[1] |= 1 // protection absent:1 1bit headers[2] = (audioObjectType - 1) << 6 // profile:audio_object_type - 1 2bits headers[2] |= (samplingFrequencyIndex & 0x0f) << 2 // sampling frequency index:sampling_frequency_index 4bits headers[2] |= (0 << 1) // private bit:0 1bit headers[2] |= (channelConfig & 0x04) >> 2 // channel configuration:channel_config 高1bit headers[3] = (channelConfig & 0x03) << 6 // channel configuration:channel_config 低2bits headers[3] |= (0 << 5) // original:0 1bit headers[3] |= (0 << 4) // home:0 1bit headers[3] |= (0 << 3) // copyright id bit:0 1bit headers[3] |= (0 << 2) // copyright id start:0 1bit headers[3] |= (adtsLen & 0x1800) >> 11 // frame length:value 高2bits headers[4] = (adtsLen & 0x7f8) >> 3 // frame length:value 中间8bits headers[5] = (adtsLen & 0x7) << 5 // frame length:value 低3bits headers[5] |= 0x1f // buffer fullness:0x7ff 高5bits headers[6] = 0xfc return headers }
其中 audioObjectType, samplingFrequencyIndex, channelConfig, adtsLen 即可从 AAC sequence header 中获取,幸运的是,flv.js pr354 的作者已经把这部分信息解析出来了,省去了我们很多麻烦。
在flv.js源码的 demux/flv-demuxer.js 中,有_parseAudioData函数:
... if (aacData.packetType === 0) { // AAC sequence header (AudioSpecificConfig) if (meta.config) { Log.w(this.TAG, 'Found another AudioSpecificConfig!') } let misc = aacData.data meta.audioSampleRate = misc.samplingRate meta.channelCount = misc.channelCount meta.codec = misc.codec meta.originalCodec = misc.originalCodec meta.config = misc.config // added by qli5 meta.configRaw = misc.configRaw // added by Xmader meta.audioObjectType = misc.audioObjectType meta.samplingFrequencyIndex = misc.samplingIndex meta.channelConfig = misc.channelCount // The decode result of Fan aac sample is 1024 PCM samples meta.refSampleDuration = 1024 / meta.audioSampleRate * meta.timescale Log.v(this.TAG, 'Parsed AudioSpecificConfig') if (this._isInitialMetadataDispatched()) { // Non-initial metadata, force dispatch (or flush) parsed frames to remuxer if (this._dispatch && (this._audioTrack.length || this._videoTrack.length)) { this._onDataAvailable(this._audioTrack, this._videoTrack) } } else { this._audioInitialMetadataDispatched = true } // then notify new metadata this._dispatch = false // metadata中的信息提供给外部封装aac的adts头部 this._onTrackMetadata('audio', meta) let mi = this._mediaInfo mi.audioCodec = meta.originalCodec mi.audioSampleRate = meta.audioSampleRate mi.audioChannelCount = meta.channelCount if (mi.hasVideo) { if (mi.videoCodec != null) { mi.mimeType = 'video/x-flv; codecs="' + mi.videoCodec + ',' + mi.audioCodec + '"' } } else { mi.mimeType = 'video/x-flv; codecs="' + mi.audioCodec + '"' } if (mi.isComplete()) { this._onMediaInfo(mi) } } ...
因此我们可以通过 _onTrackMetadata 获得metadata数据。接着我们就可以对AAC data添加ADTS头部信息:
/** * 获取添加adts头部信息的aac数据 * * @param {*} metadata * @param {*} aac * @returns */ getNewAac (aac) { const { audioObjectType, samplingFrequencyIndex, channelCount: channelConfig } = this.metadata let output = [] let _this = this // aac音频需要增加adts头部后才能被解析播放 aac.samples.forEach((sample) => { const headers = _this.getAdtsHeaders({ audioObjectType, samplingFrequencyIndex, channelConfig, adtsLen: sample.length + 7 }) output.push(...headers, ...sample.unit) }) return new Uint8Array(output) }
此时flv-demuxer.js具有两大作用:
- 获取ADTS头部信息
- 获取AAC ES流
最后我们对ES流添加ADTS头部,交给AudioContext.decodeAudioData解码并播放。
(此处我们只考虑利用flv-demuxer.js解析flv音频的功能,处理视频和MSE喂给video部分不考虑)
2. 对交给demuxer的chunk添加FLV header
addFlvHeader (chunk) { let audioBuffer = null if (this.flvHeader == null) { // copy first 9 bytes (flv header) this.flvHeader = chunk.slice(0, 9) audioBuffer = chunk } else { audioBuffer = this.appendBuffer(this.flvHeader, chunk) } return audioBuffer }
五. FLV音频的连续播放
Fetch获取音频流是一段段的,每一段时间都很短,大概100ms左右,经过添加ADST头部后,这些一段段的AAC音频如何连续播放?如此高频的解码音频是否有性能问题?
让音频连续的播放起来目前有两种方式:
第一种堆积播放:
flv-demuxer.js默认的方式,会对之前的音频进行堆积:
...
if (aacData.packetType === 1) { // AAC raw frame data let dts = this._timestampBase + tagTimestamp let aacSample = { unit: aacData.data, length: aacData.data.byteLength, dts: dts, pts: dts } track.samples.push(aacSample) track.length += aacData.data.length }
...
每次从flv-demuxer.js获取的AAC ES流都包含上一次解析的流内容,此时解码后播放需要定位到上次播放的时间,以上次播放到的时间点为起始点,播放当前的音频流,播放时长为本次流时长减去上次播放的流时长。
此种情况下,利用AudioContext.decodeAudioData的音频数据会越来越大,延时也就越来越高,消耗的性能也是越来越大。最终会导致浏览器的内存溢出,浏览器崩溃。
第二种分段播放:
此种情况为了避免上种情况的内存溢出,每次交给demuxer音频数据时,先对 track.samples 进行清空:
// 清空audio之前的metadata数据 _this.flvDemuxerObj._audioMetadata = null // 此为清除之前的audio流,得到fetch流对应的音频;若不清除,parseChunk后得到的是从开始累积的aac数据 _this.flvDemuxerObj._audioTrack = { type: 'audio', id: 2, sequenceNumber: 0, samples: [], length: 0 }
这样每次从demuxer拿到的数据即为Fetch Reader交给它的数据,没有对历史数据的累积。
每次播放时,只单独播放每个片段的音频数据。我们会把处理好的音频数据存放在音频数组 audioStack 内,每次播放从数组内取出第一个 this.audioStack.shift()
我们会在上一段音频播放结束后,进行出栈播放的操作:
audioBufferSourceNode.onended = function (e) {
_this.loopPlayBuffers()
}
此时我们忽略了从音频出栈到audioContext播放此音乐的程序运行时间,实际上是非常短暂的,我们几乎听不出有停顿。但有一种情况会产生延迟,在音频出栈的时候,发现音频栈为空,此时可能是因为网络原因fetch流产生较大的延迟,这个时候我们必须等待有新的处理好的音频入栈,才能接着播放,此时我们就会感知到一个短暂的停顿。
计算延迟时间如下:
... if (this.audioStack.length == 0) { console.warn('audioStack为空,等待audio入栈(音频解析速度慢或遇到问题)') this.delayStartTime = (new Date()).getTime() this.audioPlaying = false return } if (this.delayStartTime !== 0) { let nowTime = (new Date()).getTime() let gap = nowTime - this.delayStartTime this.delayStartTime = 0 this.debugFunc('延迟时间:' + gap + ' ms') } ...
六. 音频可视化波形实现
通过上文第二点可知我们已经获取到了音频可视化的频谱数据数组audioArray。
我们只需要按照一定规则把数组数据绘制在canvas上即可。
这里我们实现一个圆形的音频波形。

首先要理解圆形周围的每个柱形都是一个音谱数据,它的值value就是audioArray数组中的一个值,范围为[0-256]。
let meterHeight = value * (wave.cheight / 2 - wave.cr) / 256
我们可以自定义一个圆周要有多少个柱形组成,假设由 meterNum 代表柱形的个数,那我们就要从audioArray中取样,取出meterNum 个数据来:
// 计算采样步长 var step = Math.round(array.length / meterNum)
然后我们对audioArray频谱数组每隔step个数据取一个样本,进行柱形的绘制,并以圆心为中心进行旋转,旋转的度数为:
(360 / meterNum) * (wave.PI / 180)
for (let i = 0; i < meterNum; i++) { let value = array[i * step] // wave.cheight / 2 - wave.cr 为波形的最大高度 let meterHeight = value * (wave.cheight / 2 - wave.cr) / 256 || wave.minHeight // 根据圆心为中心点旋转 wave.ctx.rotate((360 / meterNum) * (wave.PI / 180)) wave.ctx.fillRect(-wave.meterWidth / 2, -wave.cr - meterHeight, wave.meterWidth, meterHeight) } wave.ctx.restore()
}
以上就是每一次绘制需要进行的操作,然后我们利用 requestAnimationFrame 进行循环以上绘制。
以上部分的完整源代码已经在github, 欢迎大家star试用,有任何问题也欢迎大家及时提出,一起讨论改进。
github地址:https://github.com/saysmy/flv-audio-visualization
2019-05-16补充更新:
第四大点:FLV音频的异步解码中 AACPacketType ,一般情况下如果音频格式标准,整个音频流只有一个 AACPacketType 为0的tag,但也有例外,有一些音频流会出现多次 AACPacketType值为0的情况, AACPacketType值为0和1交替出现,不影响解码:
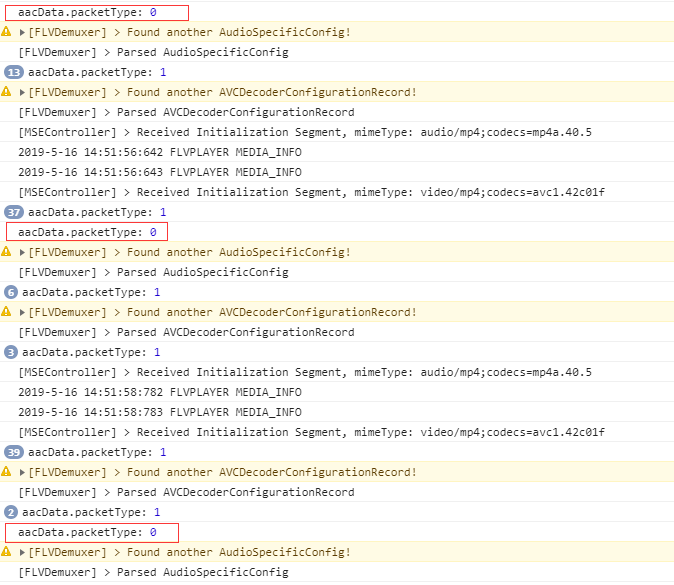
已知问题:
如果你的音视频无法播放,打开debug,发现有如下图的warning提示:

则你的flv音视频格式并不很规范,规范的flv音视频解析的flvtrunk如下:

它的前9个字节为FLV Header,前三个字节是固定的70,76,86,代表文件标志F、L、V。紧接着是4个字节的previousTagSize, 也是固定的0,0,0,0 ,因为它的前一个tag不存在,大小都为0。再接着便是flv tag,第一个字节是tag type,一般是8(音频),9(视频),18(scriptData)。如果不是这样的格式,就会解析失败,出现上图的warning提示。
附:
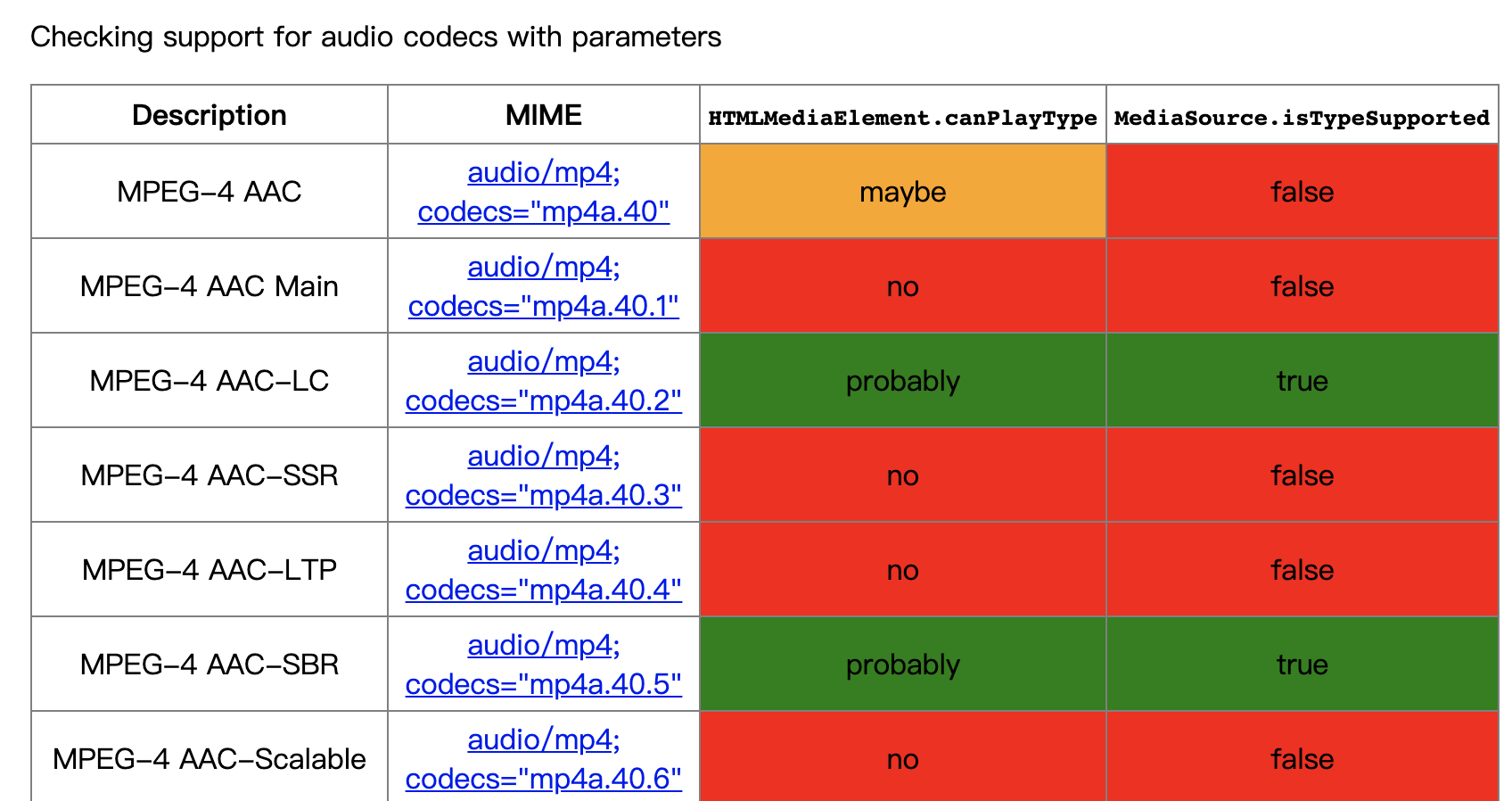
详情见:https://cconcolato.github.io/media-mime-support/#audio/mp4;%20codecs=%22mp4a.40%22
参考文章:
https://lucius0.github.io/2017/12/27/archivers/media-study-03/
https://www.jianshu.com/p/d68d6efe8230
https://blog.csdn.net/tx3344/article/details/7414543
https://segmentfault.com/a/1190000017090438
https://github.com/Xmader/flv2aac