·1. 引言
前文研究大多基于VGG16架构,这是一个为多分类设计的庞大模型, 上述引文提出的具有大量参数且推理时间巨长的网络,并无法在移动或基于电池驱动的场景中进行应用,因为这些程序需要以高于10帧/秒的速度处理图像。
我们提出的模型:
1. 无后续处理步骤,可以加但没必要
2. 模型快速而紧凑,在Encoder-Decoder框架下实现
2. 本文框架
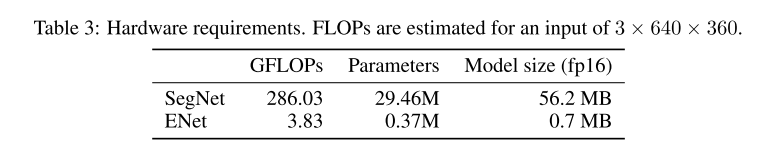
初始化模块与bottleneck模块如下图所示:
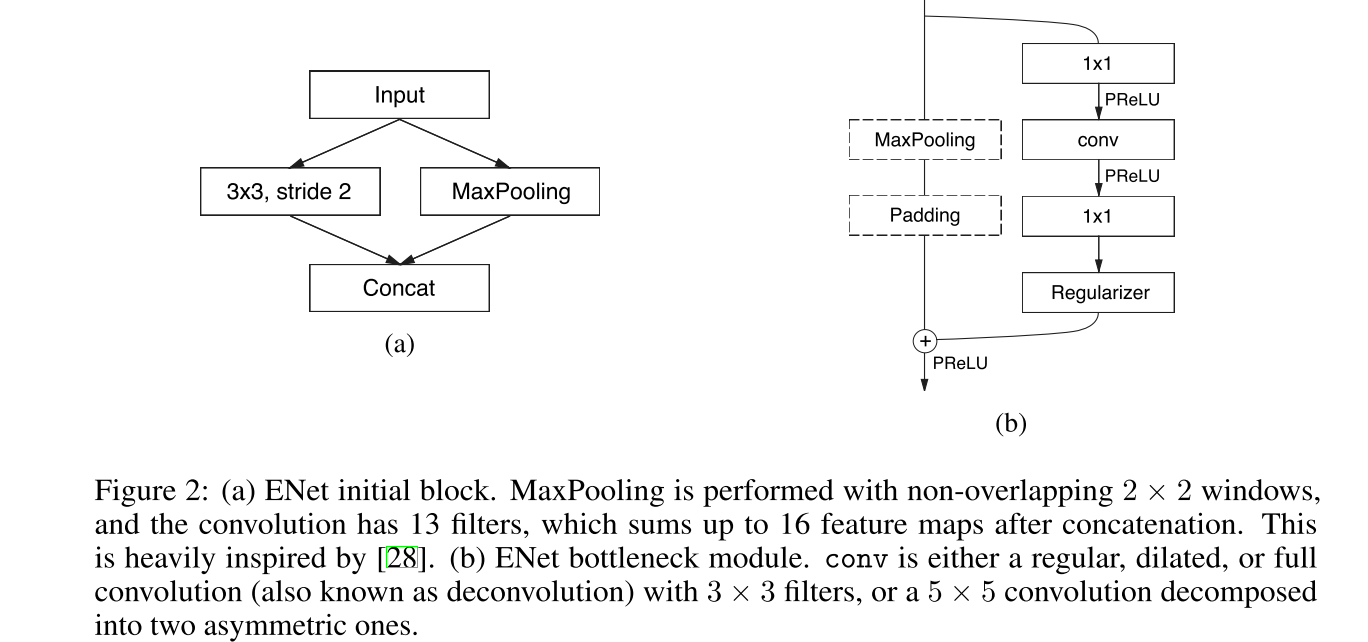
如果瓶颈是向下采样,则在主分支上增加一个最大的池化层。具体技术细节如下:

整体框架如下:
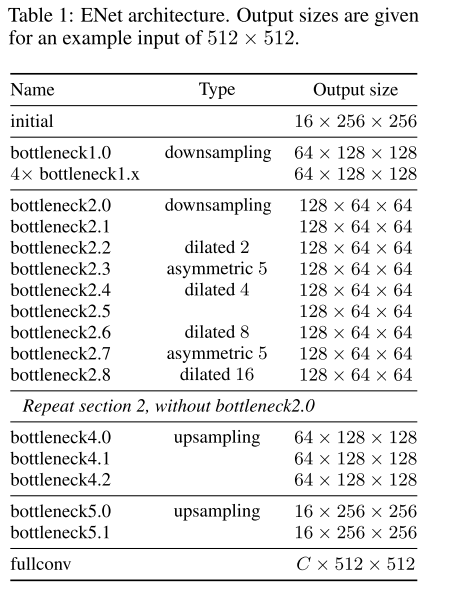
设计要点:
特征图密度:DownSampling图像在语义分割中有两个主要的缺点。首先,降低Feature Map的分辨率意味着空间信息的丢失,比如精确的边缘形状。其次,全像素分割要求输出与输入具有相同的分辨率。这意味着强下行采样需要同样的强上行采样,这会增加模型大小和计算成本。
对于第一个问题SegNet通过保存在最大池化层中选择的元素的索引,并使用它们在解码器中产生稀疏的上采样映射,我们采用与SegNet相同的操作。
对于下采样,本文采取扩展卷积的操作。
优化前期处理: ENet的前两个块大大减小了输入的大小,并且只使用了一小组特征图。它背后的想法是,视觉信息在空间上是高度冗余的,因此可以被压缩成更有效的表示。此外,我们的直觉是,最初的网络层不应该直接对分类作出贡献。相反,它们应该作为良好的特征提取器,只对网络后面部分的输入进行预处理。
解码大小:我们的体系结构由一个大的编码器和一个小的解码器组成。这是由编码器应该能够以类似于原始分类体系结构的方式工作的想法激发而成,即操作较小分辨率的数据,并提供信息处理和过滤。译码器的作用是对编码器的输出进行采样,只对细节进行微调。
Information-preserving dimensionality changes:我们选择在stride 为2的卷积下并行执行pooling操作,并将得到的feature map连接起来。这项技术使我们能够将对初始块的推断时间缩短10倍

结果:We tested on CamVid and Cityscapes datasets of road scenes, and SUN RGB-D dataset of indoor scenes