| 这个作业属于哪个课程 | 课程 |
|---|---|
| 这个作业要求在哪里 | 作业要求 |
| 这个作业的目标 | 对已爬取的论文列表进行操作,析已爬取到的论文信息,提取top10个热门领域或热门研究方向 |
| 吴世龙学号 | 221801317 |
| 陈子傲学号 | 221801320 |
PSP表
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 10 |
| • Estimate | • 估计这个任务需要多少时间 | 30 | 10 |
| Development | 开发 | 3310 | 3725 |
| • Analysis | • 需求分析 (包括学习新技术) | 60 | 120 |
| • Design Spec | • 生成设计文档 | 15 | 10 |
| • Design Review | • 设计复审 | 10 | 5 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 10 | 20 |
| • Design | • 具体设计 | 60 | 60 |
| • Coding | • 具体编码 | 3000 | 3360 |
| • Code Review | • 代码复审 | 30 | 30 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 20 | 30 |
| Reporting | 报告 | 50 | 45 |
| • Test Report | • 测试报告 | 30 | 30 |
| • Size Measurement | • 计算工作量 | 5 | 5 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 10 | 20 |
| • 合计 | 3340 | 3735 |
Github地址
项目部署地址
成品展示
主页面:展示默认的论文集合
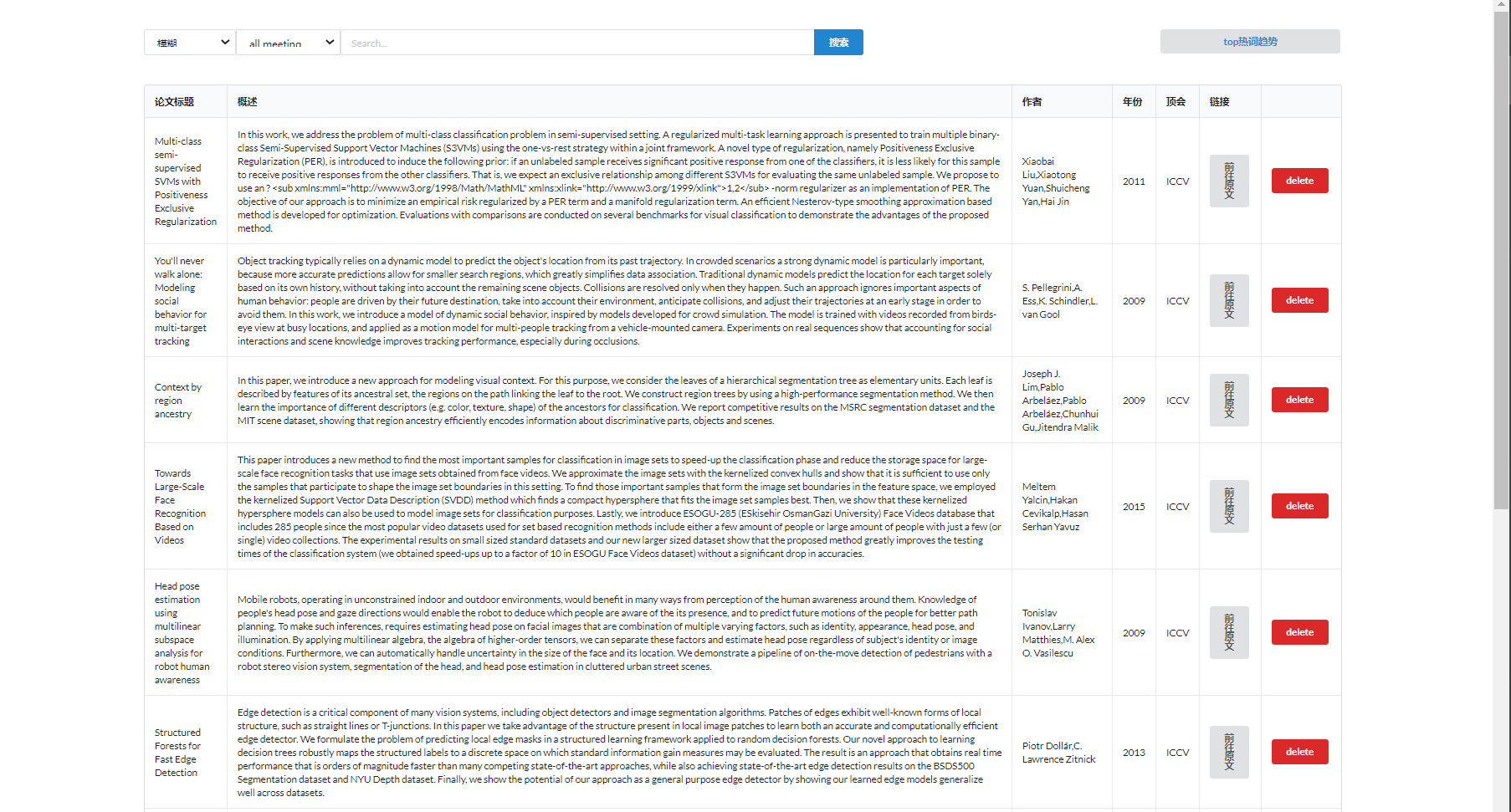
搜索框:能够采用不同的搜索方式,包括关键词搜索、标题搜索以及模糊搜索,同时也可以对不同顶会的内容进行搜索。

分页栏:每页展示十篇论文,可快速跳转

论文条目:展示论文概述标题作者年份链接等内容,删除按钮可以移除当前的论文

移除后:
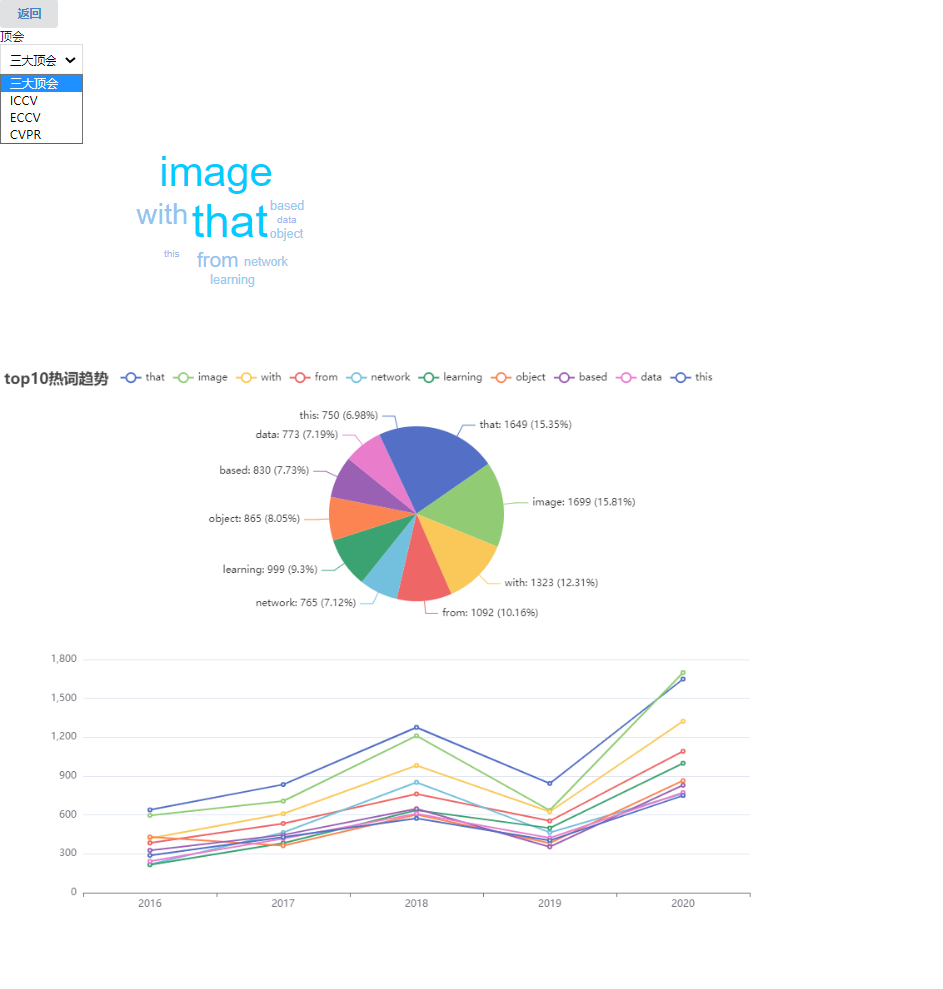
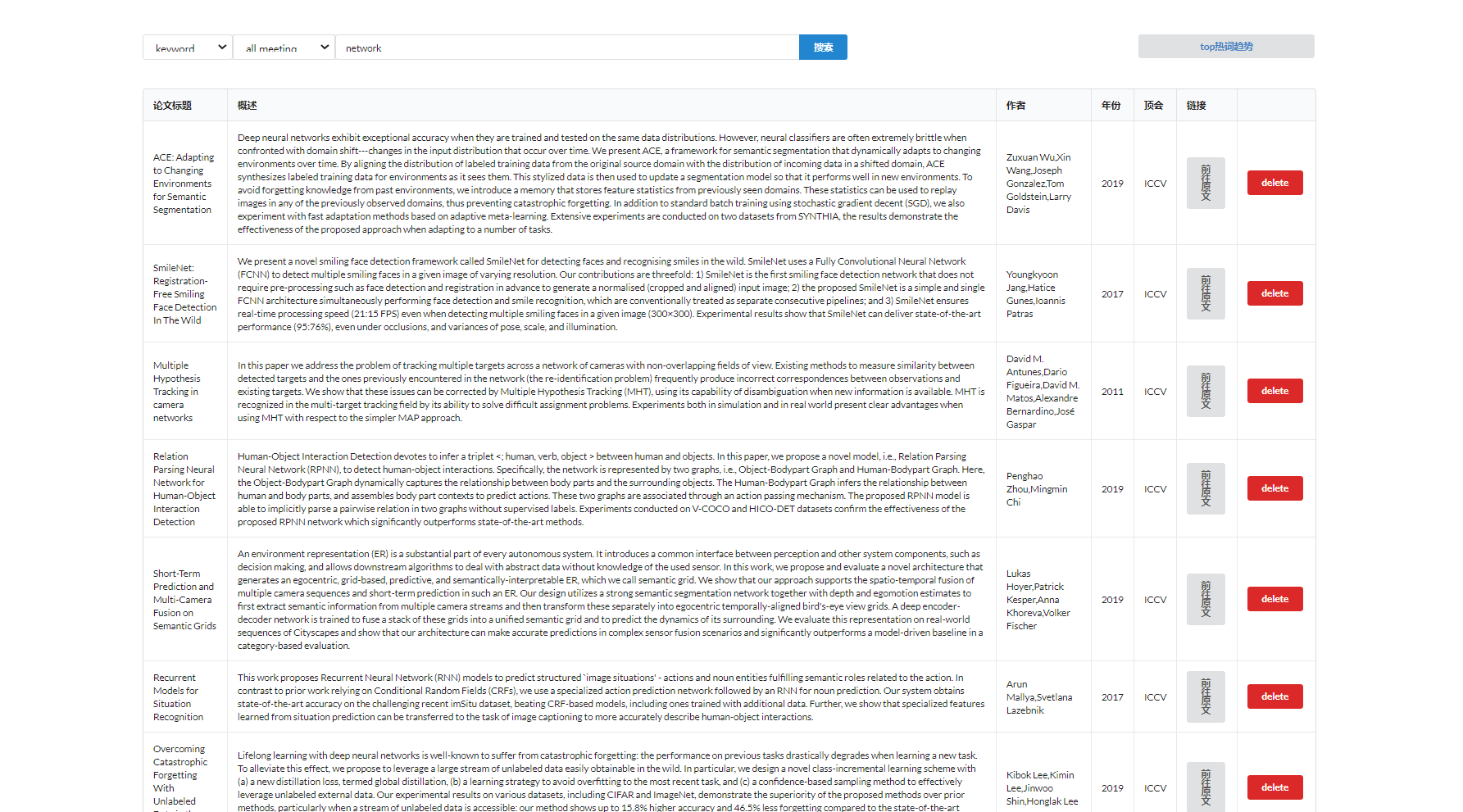
关键热词界面:可以选择不同的顶会进行查看,点击词云的关键词可以跳转到该词搜索界面
结对讨论过程
在看到作业要求之后,我们就进行了需求分析和分工。因为子傲的基础比较差,所以他在前面的时间先去学习和熟悉他负责的部分所需要的技术。世龙同学则先开始进行开发。
讨论内容主要是分析这个项目的需求,一起画了简易的原型图,以及共同学习解决问题
由于有了第一次结对的经验,再加上返校后线下讨论更加便捷,所以开展讨论的次数也变得更多;
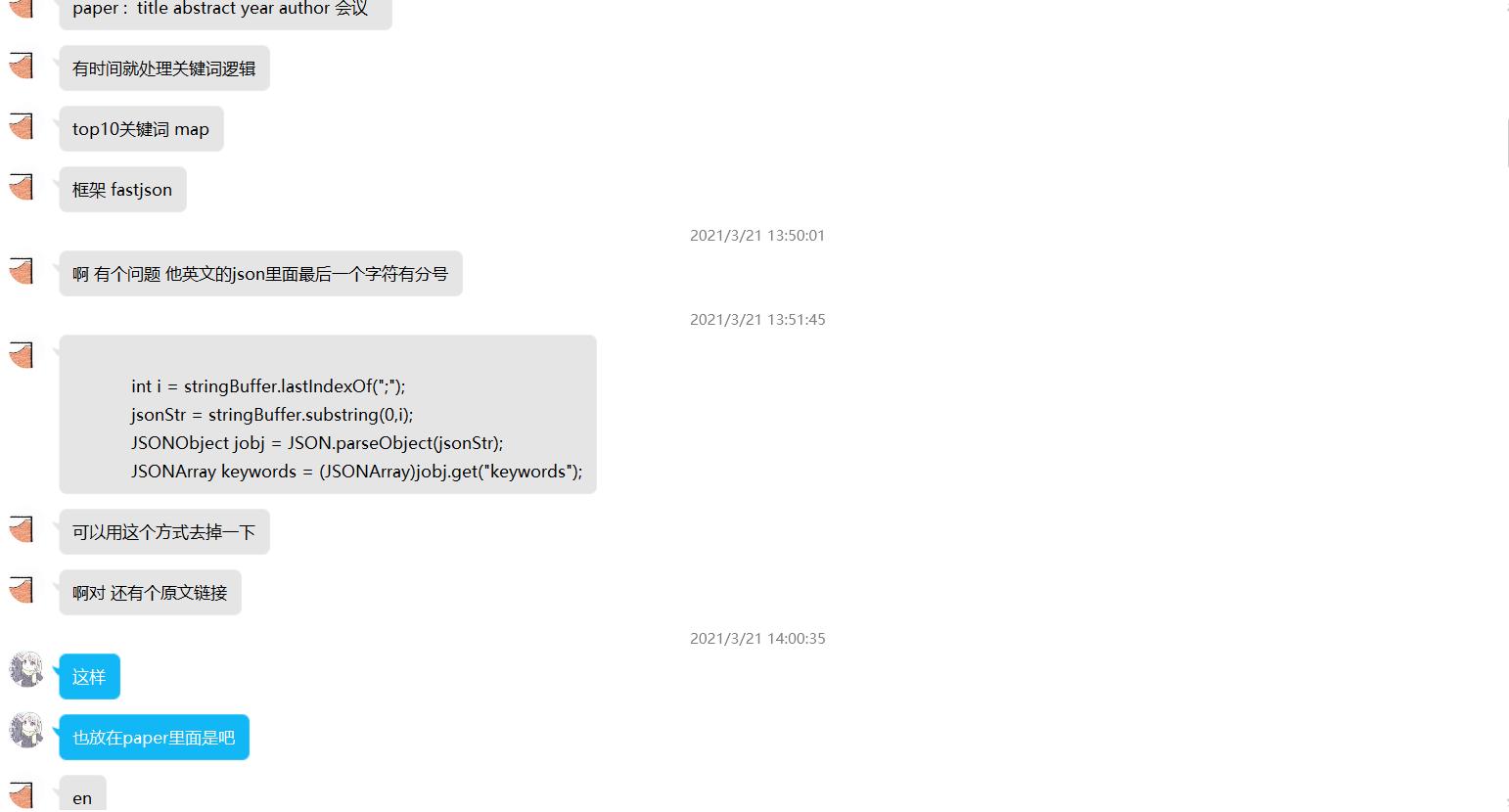
我们的讨论方式以线下讨论为主,将讨论的结果通过qq进行记录,以下放上几张讨论截图
设计实现过程





关键代码说明
论文信息处理
处理枚举类,有三个枚举类型CVPR ECCV ICCV,分别实现getPaperByJSON方法
通过fastjson进行json字符串处理
public enum PaperJSONParser {
CVPR{
@Override
Paper getPaperByJSON(StringBuilder json) throws IOException {
Paper paper = new Paper();
JSONObject paperJSONObj = JSON.parseObject(json.substring(0,json.lastIndexOf(";")));
//base info
paper.setMeeting("CVPR");
paper.setTitle(paperJSONObj.getString("title"));
paper.setAbstractContent(paperJSONObj.getString("abstract"));
paper.setYear(paperJSONObj.getString("publicationYear").trim());
paper.setLink(paperJSONObj.getString("doiLink"));
//author
JSONArray authors = paperJSONObj.getJSONArray("authors");
StringBuilder authorsInfo = new StringBuilder();
for (Object author:authors) {
JSONObject authorInfo = (JSONObject)author;
authorsInfo.append(authorInfo.getString("name")).append(",");
}
paper.setAuthors(authorsInfo.substring(0,authorsInfo.length()-1));
return paper;
}
},
...
//abstract Paper getPaper(String path) throws IOException;
abstract Paper getPaperByJSON(StringBuilder json) throws IOException;
}
为了方便进行DAO层的操作,所以把信息存储到数据库也写成了控制器方法。
这里meeting有三种取值CVPR ECCV ICCV //因为这里是我自己写的私有工具类,所以没有进行参数验证了。
可以通过meeting字符串来获取相应的PaperJSONParser
把目录名称也改成对应的三个会议的名字,就可以通过参数动态确定目录位置,可以少写很多代码。
@RequestMapping("/initmysql")
public void insertAllPaper(String meeting) throws IOException {
PaperJSONParser jsonParser = PaperJSONParser.valueOf(meeting.trim().toUpperCase());
String rootPath = basePath+meeting.trim().toUpperCase();
File root = new File(rootPath);
File[] paperPaths = root.listFiles();
for (int i = 0; i < paperPaths.length; i++) {//遍历所有目录下的论文
StringBuilder stringBuilder = new StringBuilder();
IOUtil.readToBuffer(paperPaths[i].getAbsolutePath(),stringBuilder);
Paper paper = jsonParser.getPaperByJSON(stringBuilder);//解析出paper实例
paperService.add(paper);//添加到数据库中
int paperID = paperService.getID(paper);//获取自增ID
//构造出主要内容,用来统计热词,对每篇文章中的top10热词都存储进数据库
StringBuilder mainContent = new StringBuilder(paper.getTitle());
if (paper.getAbstractContent()!=null && !paper.getAbstractContent().isEmpty()){
mainContent.append(paper.getAbstractContent());
}
TextSolver solver = new TextSolver(mainContent);
Map<String, Long> wordFrequencyMap = solver.getOrderedWordFrequencyMap(10);
//热词列表中有一些数据的冗余,方便后面的业务sql编写
for (Map.Entry wordFrequency: wordFrequencyMap.entrySet()) {
PaperKeyword paperKeyword = new PaperKeyword();
paperKeyword.setPaperID(paperID);
paperKeyword.setMeeting(paper.getMeeting());
paperKeyword.setYear(paper.getYear());
paperKeyword.setKeyword((String) wordFrequency.getKey());
paperKeyword.setFrequency((Long) wordFrequency.getValue());
paperKeywordService.add(paperKeyword);
}
}
}
热词图表相关sql
通过sum(frequency) group by keyword统计热词频率,选出top10
<!-- 返回某几年间 前10热词列表 注入到相应的POJO中-->
<resultMap id="hotWord" type="Keyword">
<result column="keyword" property="keyword"/>
<result column="year" property="year"/>
<result column="sum" property="frequency"/>
</resultMap>
<select id="getOrderedWord" parameterType="Integer" resultMap="hotWord">
select keyword,sum(frequency) sum from keywordPaper
where year between #{beginYear} and #{endYear}
<if test="meeting != null and meeting != ''">
and meeting = #{meeting}
</if>
group by keyword order by sum desc limit ${size};
</select>
通过sum(frequency) group by year获取出热词每年的出现频率
<!-- 得到某词的趋势-->
<select id="getWordTrend" resultMap="hotWord">
select keyword,year,sum(frequency) sum from keywordPaper
where keyword = #{keyword}
<if test="meeting != null and meeting != ''">
and meeting = #{meeting}
</if>
group by year ;
</select>
搜索相关
Pager 分页包装类
public class Pager {
public static final int PAGE_NUM = 10;
List<Paper> papers;//当前页面展示的所有paper
int curPage;//当前页
int nextPage;//下一页
int prePage;//前一页
int totalPageNum;//总页数
List<Integer> shownPage;//前端分页器中展示的页码
//通过papers、当前页、总页数进行初始化
public Pager(List<Paper> papers, int curPage, int totalPageNum) {
this.papers = papers;
this.curPage = curPage;
this.nextPage = (curPage+1)<totalPageNum?curPage+1:totalPageNum;
this.prePage = (curPage-1)>0?curPage-1:1;
this.totalPageNum = totalPageNum;
this.shownPage = new LinkedList<>();
for (int i = curPage-2; i <= curPage+2 ; i++){
if (i>0&&i<=totalPageNum){
shownPage.add(i);
}
}
}
...
keyword查询 控制器方法: //其他的类似
前端传入:keyword,meeting (会自动包装到keyword类中),页码
先取出总页数,再通过前端搜索请求的页码来请求出相应的paper
@GetMapping("/paper/query/keyword")
public Pager queryByKeyword(Keyword keyword,@RequestParam(name = "page",defaultValue = "1") int page){
int pageNumInLogic = page - 1;
int paperCount = paperService.queryPaperNumByKeyword(keyword);
int totalPageNum = paperCount/Pager.PAGE_NUM + 1;
List<Paper> papers = paperService.queryByKeywordLimit(keyword, pageNumInLogic * Pager.PAGE_NUM, Pager.PAGE_NUM);
return new Pager(papers,page,totalPageNum);
}
前端相应请求代码
keywordSearch = function (meeting, content, page) {
console.log("keywordSearch", meeting, content, page)
axios({
method: 'get',
url: '/paper/query/keyword',
params: {
keyword: content,
meeting: meeting,
page: page
},
}).then(function (response) {
flashData(response)
});
};
前端展示 使用vue框架
<tr v-for="paper in papers">
<td >{{paper.title}}</td>
<td >{{paper.abstractContent}}</td>
<td >{{paper.authors}}</td>
<td >{{paper.year}}</td>
<td >{{paper.meeting}}</td>
<td >
<a class="ui button" v-bind:href="paper.link">前往原文</a>
</td>
<td>
<button id="delbtn"
@click="del(paper.paperID)"
class="ui red button" >delete</button>
</td>
</tr>
分页器
<div id="pager" class="ui right floated pagination menu">
<template v-if="curPage != 1">
<a @click="toBegin" class="icon item">
<i class="angle double left icon"></i>
</a>
<a @click="toPre" class="icon item">
<i class="left chevron icon"></i>
</a>
</template>
<template v-for="pageNum in shownPage">
<template v-if="pageNum == curPage">
<a @click="toPage(pageNum)" style="background-color: lightgrey" class="item">
{{pageNum}}</a>
</template>
<template v-else>
<a @click="toPage(pageNum)" class="item">
{{pageNum}}</a>
</template>
</template>
<template v-if="curPage != totalPageNum">
<a @click="toNext" class="icon item">
<i class="right chevron icon"></i>
</a>
<a @click="toEnd" class="icon item">
<i class="angle double right icon"></i>
</a>
</template>
</div>
心路历程以及收获
陈子傲:本次结对作业对于偏向产品/策划方向的我来说相对困难一些,对于很多知识都是两眼一摸黑,之前也没有过相关项目的经验,但是好在在吴世龙同学的帮助之下,磕磕绊绊的还是完成了一些内容,同时我发现自己对于新知识的学习速度较慢,可能后期还需要提前进行学习;
吴世龙:本次结对作业整体来说基础功能难度不是很大,但是需要花比较多的时间进行实现。因为有比较长的时间没有做项目,所以最后也只能勉强把基础需求完成。本次的收获一方面是把一些关于后端开发的东西捡起来了,然后就是把假期简单过一遍的vue使用到实际的项目里了,对前端的开发有了一定的了解。
评价结对队友
陈子傲:世龙不仅编程能力强悍,前后端精通,同时也具有非常强的责任感,和他组织讨论能够学习到很多知识,同时由于我个人对于这块知识了解相对较少,世龙也不厌其烦的教授我有关的知识和方法,同时包揽了大半工作,是个非常可靠的队友。(总之就是我拖了世龙的后退)
吴世龙:子傲对于开发的基础比较薄弱,所以给他负责的比较简单的模块。虽然他基础不好,但是他有比较强的学习积极性,有问题就会来一起讨论学习。最后圆满完成他负责的任务。