一:
python代码:
a = 2 def b(): print a a = 4 print a b()
在b函数中,有a=4这样的代码,说明a是函数b内部的局部变量,而不是外部的那个值为2的全局变量a,那么第一行代码就报错了,原因是local variable 'a' referenced before assignment
而在c中就不会报错:
#include <stdio.h> int a=2; main(){ printf("global variable a : %d ",a); int a=3; printf("local variable a : %d ",a); } /*结果: global variable a : 2 local variable a : 3 */
在main函数中,变量a开始为全局变量,后来为本地变量,这在Python中是不允许的
二:
在python中是正确的:
def b(): print x x=3 b()
但是在c中在编译阶段就会报错:
#include <stdio.h> b(){ printf("b : %d ",a); } int a =3; main(){
b(); }
错误在第三行,错误原因是变量a未声明,如果将上述代码改一下,改成:
#include <stdio.h> extern int a; b(){ printf("b : %d ",a); } main(){ b(); }
则虽然编译通过了,但是链接的时候却报错了,extern int a;的意思是,变量a在别处有定义,暂时先让我编译通过。于是虽然编译阶段是通过了,但等到链接的时候,由于本源文件没有include其他源文件,导致连接器最终还是没能找到变量a的定义,于是就报错了
以上是python和c语言不同之处,下面再说一个相同的地方,大家都知道python是有闭包存在的:
a=2 def aa(): print a def bb(): a=4 aa() bb()#打印2
在c语言中同样存在:
#include <stdio.h> int a=2; b(){ printf("b : %d ",a); } main(){ int a=4; b();//打印2 } /*但是如果把main函数改为: main(){ a=4; b();//将不在打印4,而是2. }*/
明白了上述问题,我们来看几个例子:
现在同一文件夹下有如下文件:
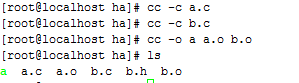
编译a.c: cc -c a.c; 生成a.o
编译b.c: cc -c b.c; 生成b.o
链接a.o,b.o生成最终可执行文件a: cc -o a a.o b.o
//a.c #include <stdio.h> #include "b.h" main(){ int a = 3; bb(); } //b.h void bb(void); //b.c #include <stdio.h> int a = 1; bb(){ printf ("%d ",a); }
执行./a,执行结果:打印的是1,而不是3
在本例中,b.c中的a属于公共的通用的变量,b函数里的a也正是这个公共变量a。任何源文件的代码在引用这个变量之前,只要有这个变量的声明,或者该源文件include的文件有这个变量的声明,那么这个源文件就可以访问这个变量或者修改这个变量的值。本例中,a.c文件就没有声明该变量。
//a.c #include <stdio.h> #include "b.h" main(){ int a = 3; bb(); } //b.h int a; void bb(void); //b.c #include <stdio.h> int a = 1; bb(){ printf ("%d ",a); }
上面这个是在b的头文件中加入了变量a的声明。a程序运行的结果还是打印1,而不是3.因为虽然全局公共变量a虽然被带到了源文件a.c中了,但是在mian函数中的a是局部变量a,而不是全局公共变量a,而bb函数中的a是全局公共变量a,所以打印1.
//a.c #include <stdio.h> #include "b.h" main(){ a = 3; bb(); } //b.h int a; void bb(void); //b.c #include <stdio.h> int a = 1; bb(){ printf ("%d ",a); }
上面这个例子中,修改了一下main函数,这时,程序a运行的结果才变为了3,这时因为main函数中的a正是全局变量a,并且把a原来的值改为了3,所以打印3
//a.c #include <stdio.h> #include "b.h" main(){ a = 3;
printf("%d",a); bb(); } //b.h int a; void bb(void); //b.c #include <stdio.h> static int a = 1; bb(){ printf ("%d ",a); }
上面这个例子中,修改了一下b.c,将变量a由原来的全局公共变量变成了本地静态变量,那么这个变量的作用域仅仅是b.c,我们知道include只是将文件加载进来,
所以,a.c源文件完全等价于:
//a.c #include <stdio.h> int a; void bb(void); main(){ a = 3; printf("%d",a); bb(); }
所以a.c中的变量a是全局公共变量a,而main函数中的a也正是这个,而bb中的a是b.c文件中的本地静态变量a,所以才会先打印3,后打印1
但是上面这个例子虽然语法上是没有任何错误的,但是却失去了头文件库文件的意义。
正确的写法是:
//a.c #include <stdio.h> #include "b.h" main(){ printf("%d",b); bb(); } //b.h int b; void bb(void); //b.c #include <stdio.h> #include "b.h" static int a = 1; int b=4; bb(){ printf ("%d ",a); }
其中a.c可以说成主程序文件,而b.h是这个主程序文件正常运行所依赖的头文件,而b.c是这个主程序文件正常运行所依赖的库文件。
我们把b.c这个库文件中,所有的需要被其他程序引用的变量或函数或者其他什么的,都列出来,做成一个文件,这个文件就是b.c的头文件,特别要注意到,由于
b.c中的变量a是本地私有的变量,其他程序文件用不到这个变量,所以就没有出现在头文件b.h中
还有就是,b.c是要包含他自己的头文件b.h的,虽然不包含也不会报错,但这是一个很好的习惯,这样我们在编译b.c的时候,编译器就能帮我们检测头文件中的声明与库文件是否保持一致,试想一下,如果b.h中,我们写的是float int b;那么有了include这句话,在编译b.c的时候编译器就能帮我们找出错误