Disruptor 的大名从很久以前就听说了,但是一直没有时间;看完以后才发现其内部的思想异常清晰,很容易就能前移到其他的项目,所以仔细了解一下还是很有必要的这。篇博客将主要从源码角度分析,Disruptor 为什么那么快,在此之前可以先查看 Disruptor 详解 一 ,能够对 Disruptor 的使用有一个大致的了解;此外 Disruptor 通常会和 ArrayBlockingQueue 做对比,可以参考 JDK源码分析(11)之 BlockingQueue 相关 ;
一、Disruptor 简介
首先可以从下面两张图看到,Disruptor 的内部结构,只这里我偷了一下懒,图中的内容是老版本的,可能和新版本有点不一样但是主要结构还是一样的;

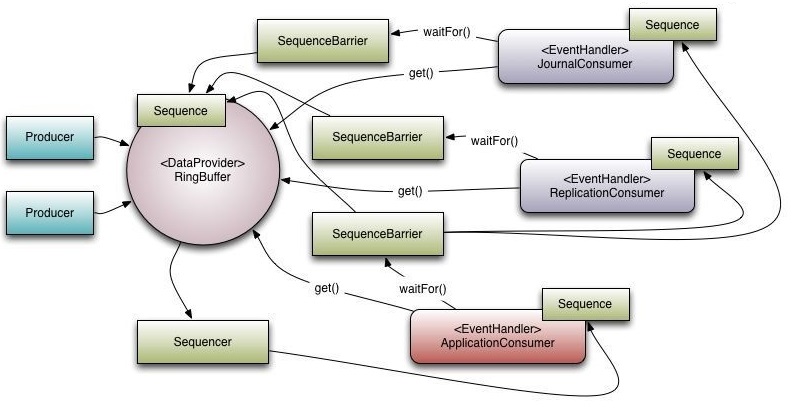
具体使用示例代码我这里就不贴,大家可以看我上一篇博客;
初始化;首先在启动的时候,需要预先初始化 RingBuffer,所以需要传入 EventFactory;这里和 JUC 里面 Queue 很不一样的地方地方是,RingBuffer 中的 Event 不会被取出,每次 publish 的时候都是覆盖之前的内容,所以 RingBuffer 这里是不会产生 GC 的;而生产者和消费者都持有一个 Sequence,指示当前的处理位置,当需要获取 Event 的时候,可以直接使用 sequence & ringBuffer.size - 1 除留余数法快速找到对应的数组位置;
private void fill(EventFactory<E> eventFactory) {
for (int i = 0; i < bufferSize; i++) {
entries[BUFFER_PAD + i] = eventFactory.newInstance();
}
}
生产者;同时可以指定 Disruptor 是单生产者还是多生产者:
- ProducerType.SINGLE - SingleProducerSequencer :因为只有一个生产者,所以者更新 sequence 的时候是不需要加锁的;
- ProducerType.MULTI - MultiProducerSequencer :多个生产者的时候,使用乐观锁机制更新 sequence,即
UNSAFE.compareAndSwapLong;
当没有空余位置的时候他们都是使用 LockSupport.parkNanos(1L); 来阻塞线程的,如果有需要你也可以改成其他的等待模式;
// RingBuffer
// 首先通过 Sequencer 拿到下一个可用的序列
public long next() { return sequencer.next(); }
// 然后用除留余数发拿到对应的数组元素
public E get(long sequence) { return elementAt(sequence); }
// 这里是使用 UNSAFE 直接获取内存对象
protected final E elementAt(long sequence) {
return (E) UNSAFE.getObject(entries, REF_ARRAY_BASE + ((sequence & indexMask) << REF_ELEMENT_SHIFT));
}
// 最后将拿到的数组元素修改为新的 Event,再发布
public void publish(long sequence) { sequencer.publish(sequence); }
// 这里所有关于生产者并发的问题都封装到了 Sequencer 里面,后面最详细讲到
消费者;正因为上面说的 RingBuffer 中的对象不对像普通的 Queue 一样,真正取出,所以在 Disruptor 中可以很容易做到,同一个消息同时被多个消费者获取的逻辑;这里的关键就在于 每个消费者所持有的 Sequence;
- 当消息可以被重复消费的时候,每个消费者不需要管其他的消费者,每次获取新任务的时候,只需要和生产者的 Sequence 比较就可以了,获取成功后更新自己,这样每个消费者就可以互不影响了;
- 当消息不能被重复消费的时候,所有的消费者共享一个 Sequence,当发生竞争的时候使用指定的 WaitStrategy 解决冲突;
等待策略;Disruptor 提供了很多从等待策略,这里需要根据实际的业务需求选择使用;同时和 JDK 中的队列相比,无论是阻塞队列还是并发队列,其控制并发的方式都是固定的,而在 Disruptor 中则可以很容易的定制这些策略,从这一点来看也可以说是实现了策略模式;
- BlockingWaitStrategy: 和 ArrayBlockingQueue 一样使用加锁的方式
- BusySpinWaitStrategy: Busy Spin strategy 自旋等待
- LiteBlockingWaitStrategy: BlockingWaitStrategy 的变种,也是使用加锁方式
- PhasedBackoffWaitStrategy:两段式策略
- SleepingWaitStrategy: 这是一个在性能和 CPU 占用率做了平衡的一种策略,初始自旋,然后 Yield,最后 Sleep
- TimeoutBlockingWaitStrategy:同名字
- YieldingWaitStrategy: 使用自旋、Yield 方式
以上这些就是 Disruptor 的大致框架性内容了,另外有两点是 Disruptor 很快的重要原因;
- 缓存的引用
- 并发的处理
二、Disruptor 对缓存的应用
首先计算机中各级存储器的速度差异巨大,数量级描述大致如下:
| 存储器 | 容量 | 速度 |
|---|---|---|
| 寄存器 | * / B | 1 ns |
| 一级 Cache | * / KB | 5 ~ 10 ns |
| 二级 Cache | * / KB - M | 40 ~ 60 ns |
| 内存 | */ M - G | 100 ~ 150 ns |
| 硬盘 | * / G - T | 3 ~ 15 ms |
根据上图的数据,直观的反应如果想加快软件的运行速度,当然是尽量利用上层的缓存体系;在 JVM 中缓存不是以单字节存在的,而是以缓存行的形式,通常是 2 的整数幂个连续字节,一般为 32-256 个字节。最常见的缓存行大小是 64 个字节;
在我们的队列,数则或者 Disruptor 中,理想状态下就是生产者和消费的速度保持相对一致,这样能避免阻塞的发生,其生产者和消费者就分别位于数组的头部和尾部;

但是这样的理想状态很难到达,要么是生产者快一些,要么是消费者快一些,其结果如下图;

所以头和尾通常都位于同一个缓存行中,这样者更新头的时候,将对应的缓存标记为失效,同时尾也被标记为了失效,者就是伪缓存;
下面是一个缓存的测试例子;
public final class FalseSharing implements Runnable {
private static final int NUM_THREADS = 4; // change
private static final long ITERATIONS = 500L * 1000L * 1000L;
private final int arrayIndex;
private static VolatileLong[] longs = new VolatileLong[NUM_THREADS];
static {
for (int i = 0; i < longs.length; i++) {
longs[i] = new VolatileLong();
}
}
public FalseSharing(final int arrayIndex) {
this.arrayIndex = arrayIndex;
}
public static void main(final String[] args) throws Exception {
final long start = System.nanoTime();
runTest();
System.out.println("duration = " + (System.nanoTime() - start));
}
private static void runTest() throws InterruptedException {
Thread[] threads = new Thread[NUM_THREADS];
for (int i = 0; i < threads.length; i++) {
threads[i] = new Thread(new FalseSharing(i));
}
for (Thread t : threads) {
t.start();
}
for (Thread t : threads) {
t.join();
}
}
@Override
public void run() {
long i = ITERATIONS + 1;
while (0 != --i) {
longs[arrayIndex].value = i;
}
}
public static final class VolatileLong {
// public long p1, p2, p3, p4, p5, p6; // cache line padding
public volatile long value = 0L;
// public long p8, p9, p10, p11, p12, p13, p14, p15; // cache line padding
}
}
这里不同的机器测试的结果不同,大家可以修改线程数,padding 数,和 padding 的先后顺序;会得到不同的结果;
我测试的结果:
无 padding :17988876300
有 padding :4667271000
可以看到是查了一个数量级
这样的缓存填充,在 Disruptor 中随处可见:
abstract class RingBufferPad {
protected long p1, p2, p3, p4, p5, p6, p7;
}
public final class RingBuffer<E> extends RingBufferFields<E> implements Cursored, EventSequencer<E>, EventSink<E> {
public static final long INITIAL_CURSOR_VALUE = Sequence.INITIAL_VALUE;
protected long p1, p2, p3, p4, p5, p6, p7;
...
}
三、Disruptor 的并发处理
并发的处理,同样的 Disruptor 中随处可见,虽然在平时写代码的时候也会注意,但是当状态变量多了以后,代码就会变得很复杂,不容易读懂;而在 Disruptor 中由 Sequence 串联起来的各个部分,以及策略模式的应用,使得每部分的处理一样的清晰;这里的内容太多了就不一一分析了,比如 MultiProducerSequencer 和 SingleProducerSequencer;
// SingleProducerSequencer
public long next(int n) {
if (n < 1) throw new IllegalArgumentException("n must be > 0");
long nextValue = this.nextValue;
long nextSequence = nextValue + n;
long wrapPoint = nextSequence - bufferSize;
long cachedGatingSequence = this.cachedValue;
if (wrapPoint > cachedGatingSequence || cachedGatingSequence > nextValue) {
cursor.setVolatile(nextValue); // StoreLoad fence
long minSequence;
while (wrapPoint > (minSequence = Util.getMinimumSequence(gatingSequences, nextValue))) {
LockSupport.parkNanos(1L); // TODO: Use waitStrategy to spin?
}
this.cachedValue = minSequence;
}
this.nextValue = nextSequence;
return nextSequence;
}
// MultiProducerSequencer
public long next(int n) {
if (n < 1) throw new IllegalArgumentException("n must be > 0");
long current;
long next;
do {
current = cursor.get();
next = current + n;
long wrapPoint = next - bufferSize;
long cachedGatingSequence = gatingSequenceCache.get();
if (wrapPoint > cachedGatingSequence || cachedGatingSequence > current) {
long gatingSequence = Util.getMinimumSequence(gatingSequences, current);
if (wrapPoint > gatingSequence) {
LockSupport.parkNanos(1); // TODO, should we spin based on the wait strategy?
continue;
}
gatingSequenceCache.set(gatingSequence);
}
else if (cursor.compareAndSet(current, next)) {
break;
}
}
while (true);
return next;
}
总结
对 Disruptor 源码查看的最大感觉是,习以为常的结构设计模式,都可以有更精妙的写法,如果 Sequence 承担的各部分逻辑串联的角色,整体的消费者生产者模式,消费者部分可以看成是观察者模式,也可以看出是事件监听模式,以及并发控制的策略模式;两外就是包括伪缓存在内的各细节优化;