什么是Stream?
Stream它并不是一个容器,它只是对容器的功能进行了增强,添加了很多便利的操作,例如查找、过滤、分组、排序等一系列的操作。并且有串行、并行两种执行模式,并行模式充分的利用了多核处理器的优势,使用fork/join框架进行了任务拆分,同时提高了执行速度。简而言之,Stream就是提供了一种高效且易于使用的处理数据的方式。
- 特点:
- Stream自己不会存储元素。
- Stream的操作不会改变源对象。相反,他们会返回一个持有结果的新Stream。
- Stream 操作是延迟执行的。它会等到需要结果的时候才执行。也就是执行终端操作的时候。
- 图解:
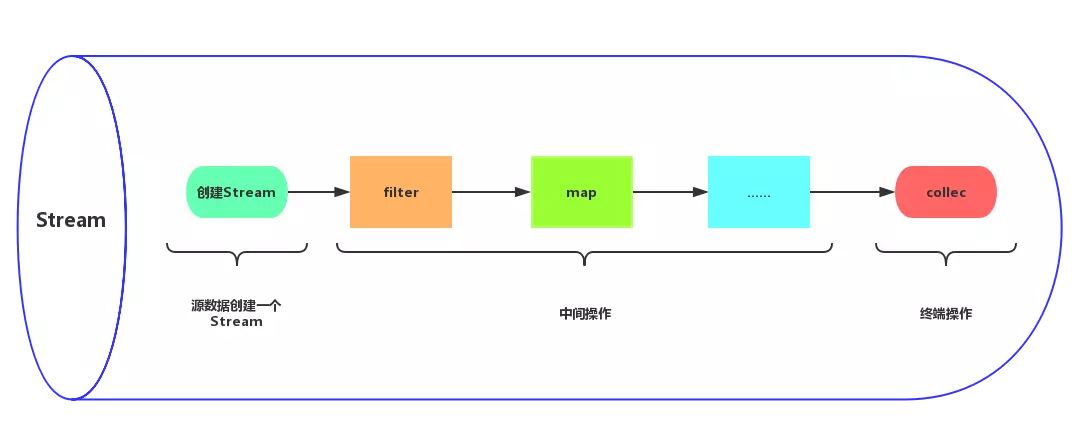 一个Stream的操作就如上图,在一个管道内,分为三个步骤,第一步是创建Stream,从集合、数组中获取一个流,第二步是中间操作链,对数据进行处理。第三步是终端操作,用来执行中间操作链,返回结果。
一个Stream的操作就如上图,在一个管道内,分为三个步骤,第一步是创建Stream,从集合、数组中获取一个流,第二步是中间操作链,对数据进行处理。第三步是终端操作,用来执行中间操作链,返回结果。
怎么创建Stream?
- 由集合创建: Java8 中的 Collection 接口被扩展,提供了两个获取流的方法,这两个方法是default方法,也就是说所有实现Collection接口的接口都不需要实现就可以直接使用:
- default Stream stream() : 返回一个顺序流。
- default Stream parallelStream() : 返回一个并行流。
例如:
List<Integer> integerList = new ArrayList<>();
integerList.add(1);
integerList.add(2);
Stream<Integer> stream = integerList.stream();
Stream<Integer> stream1 = integerList.parallelStream();
- 由数组创建: Java8 中的 Arrays 的静态方法 stream() 可以获取数组流:
- static Stream stream(T[] array): 返回一个流
- 重载形式,能够处理对应基本类型的数组:
public static IntStream stream(int[] array)
public static LongStream stream(long[] array)
public static DoubleStream stream(double[] array)
例如:
int[] intArray = {1,2,3};
IntStream stream = Arrays.stream(intArray);
- 由值创建: 可以使用静态方法 Stream.of(), 通过显示值 创建一个流。它可以接收任意数量的参数。
- public static Stream of(T... values) : 返回一个流。
例如:
Stream<Integer> integerStream = Stream.of(1, 2, 3, 4, 5, 6, 7, 8);
- 由函数创建:创建无限流 可以使用静态方法 Stream.iterate() 和 Stream.generate()创建无限流。
- 迭代 public static Stream iterate(final T seed, final UnaryOperator f)
- 生成 public static Stream generate(Supplier s)
例如:
Stream.generate(Math::random).limit(5).forEach(System.out::print);
List<Integer> collect = Stream.iterate(0,i -> i + 1).limit(5).collect(Collectors.toList());
注意:使用无限流一定要配合limit截断,不然会无限制创建下去。
Stream的中间操作
如果Stream只有中间操作是不会执行的,当执行终端操作的时候才会执行中间操作,这种方式称为延迟加载或惰性求值。多个中间操作组成一个中间操作链,只有当执行终端操作的时候才会执行一遍中间操作链,具体是因为什么我们在后面再说明。下面看下Stream有哪些中间操作。
- Stream
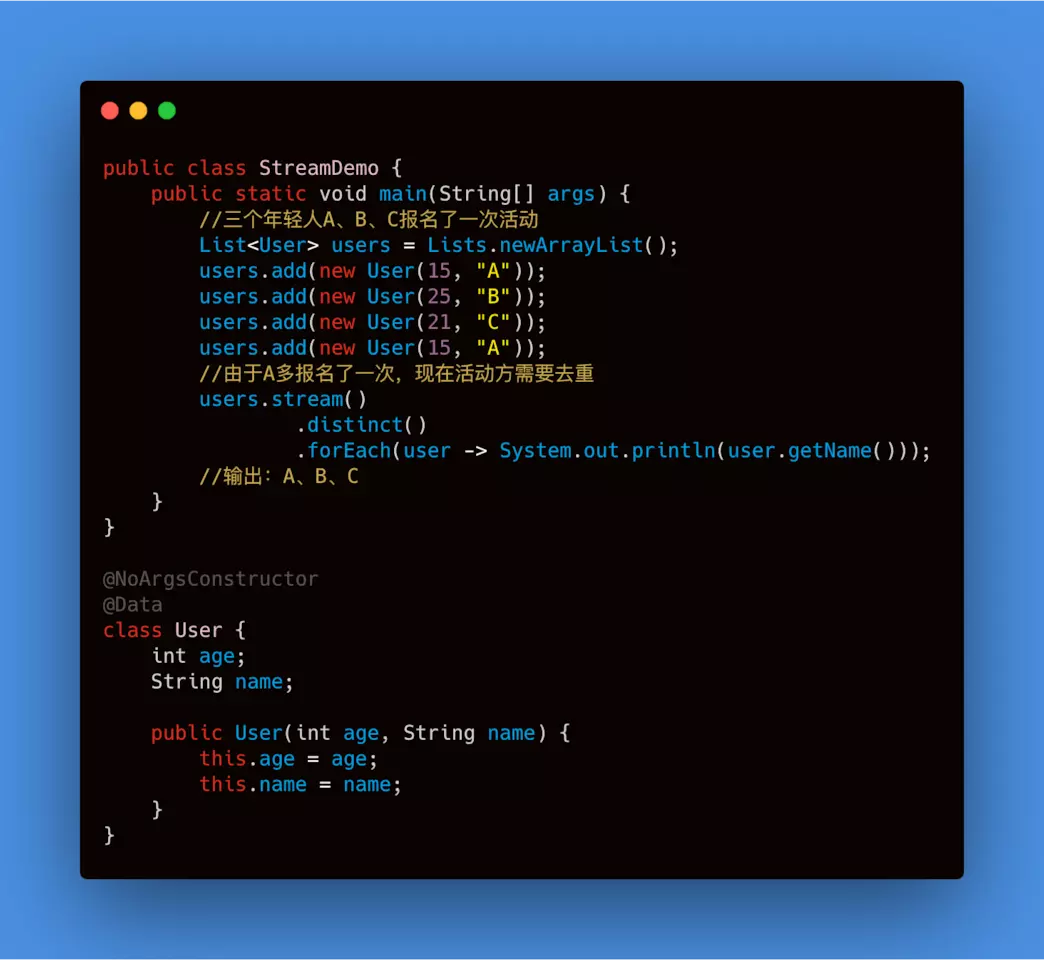
<T>distinct(): 去重,通过流所生成元素的 hashCode() 和 equals() 去除重复元素。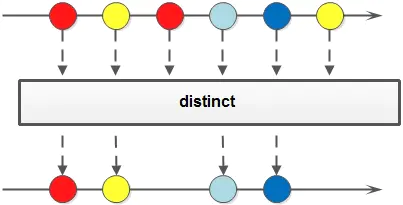
- Stream
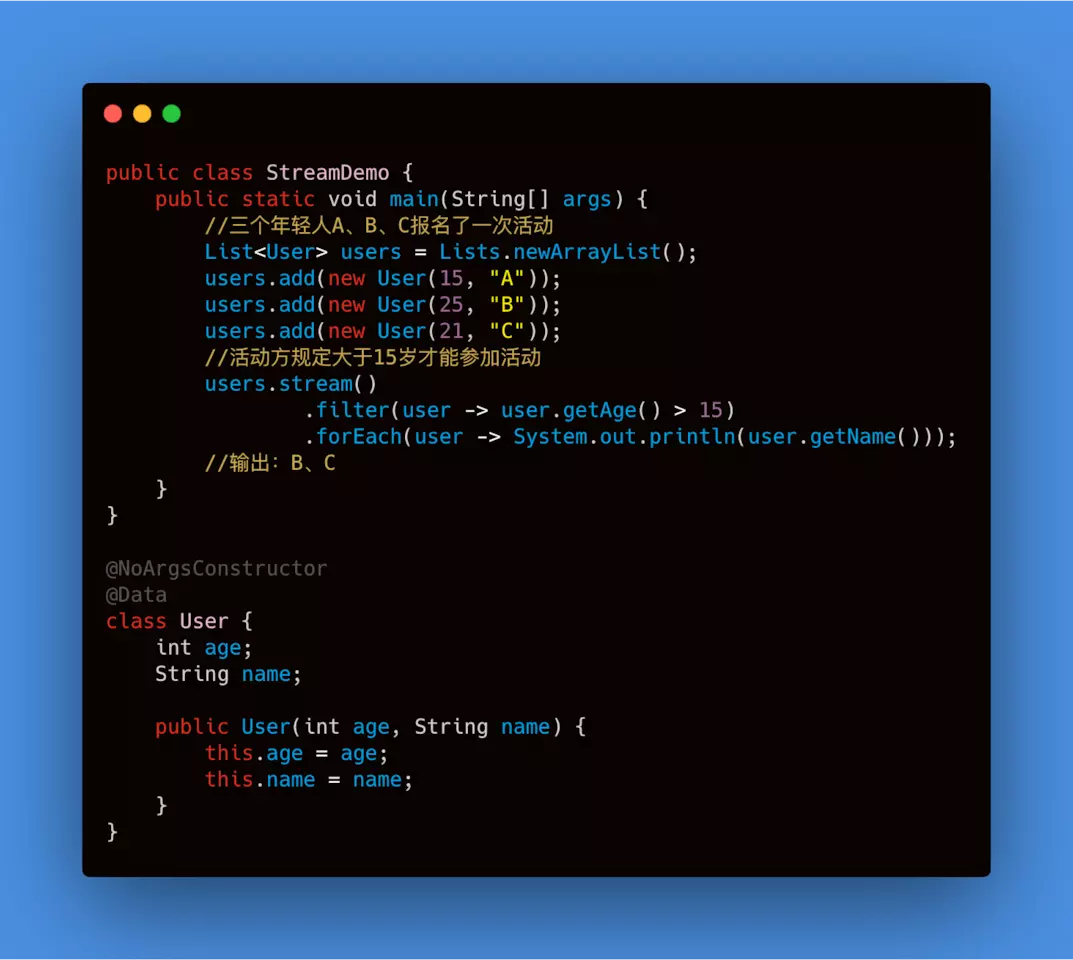
<T>filter(Predicate<? super T> predicate): Predicate函数在上一篇当中我们已经讲过,它是断言型接口,所以filter方法中是接收一个和Predicate函数对应Lambda表达式,返回一个布尔值,从流中过滤某些元素。
- Stream
<T>sorted(Comparator<? super T> comparator): 指定比较规则进行排序。 默认是升序, 若降序 操作为.sorted(..).reversed())

- Stream
<T>limit(long maxSize): 截断流,使其元素不超过给定数量。如果元素的个数小于maxSize,那就获取所有元素。
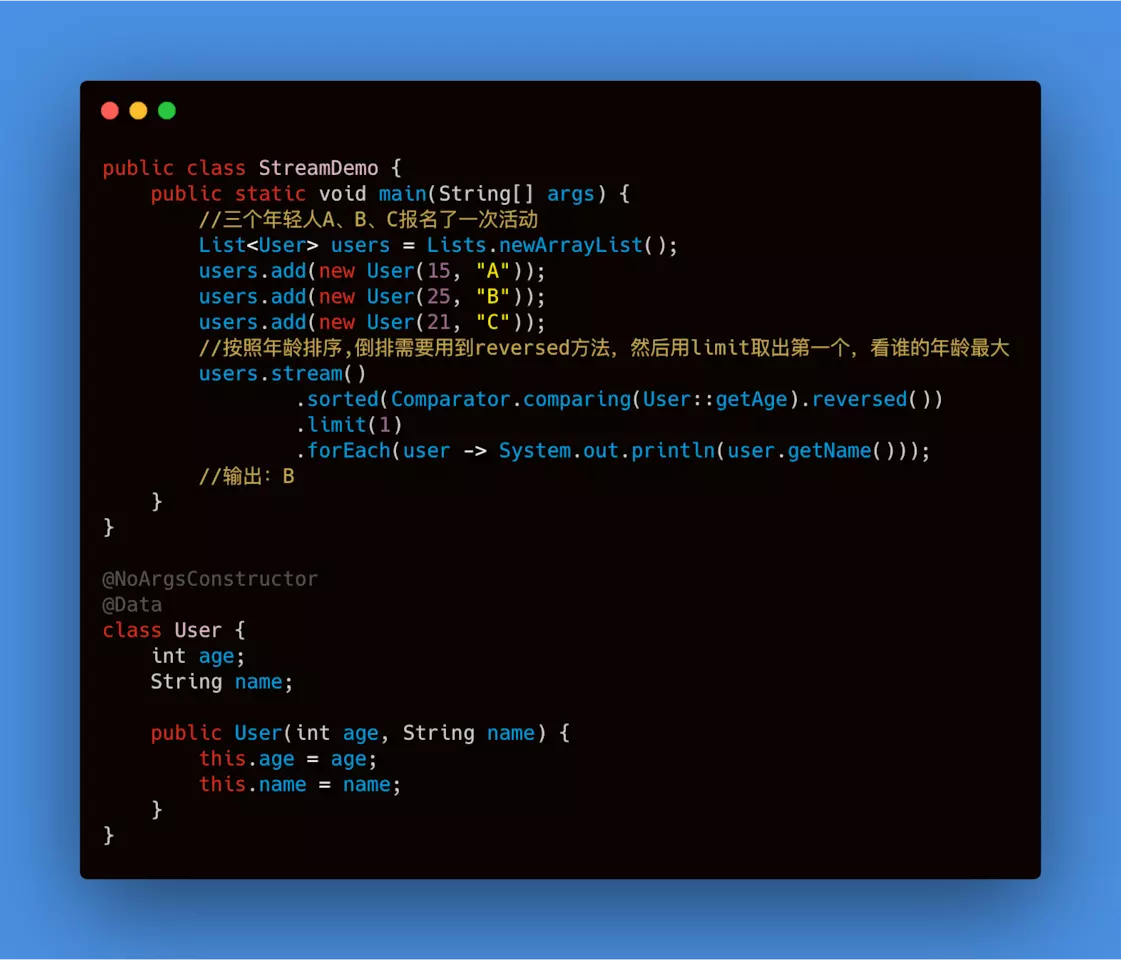
- Stream
<T>skip(long n): 跳过元素,返回一个扔掉了前 n 个元素的流。若流中元素不足 n 个,则返回一个空流。与 limit(n) 互补。

- Stream
<R>map(Function<? super T, ? extends R> mapper): 接收一个Function函数作为参数,该函数会被应用到每个元素上,并将其映射成一个新的元素。也就是转换操作,map还有三个应用于具体类型方法,分别是:mapToInt,mapToLong和mapToDouble。这三个方法也比较好理解,比如mapToInt就是把原始Stream转换成一个新的Stream,这个新生成的Stream中的元素都是int类型。这三个方法可以免除自动装箱/拆箱的额外消耗。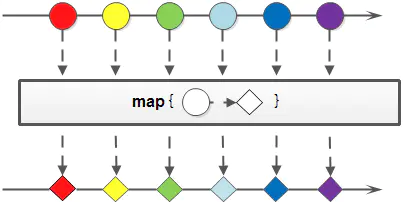

- Stream
<R>flatMap(Function<? super T, ? extends Stream<? extends R>> mapper): 接收一个Function函数作为参数,将流中的每个值都转换成另一个流,然后把所有流连接成一个流。flatMap也有三个应用于具体类型的方法,分别是:flatMapToInt、flatMapToLong、flatMapToDouble,其作用于map的三个衍生方法相同。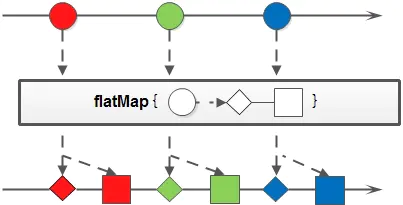
Stream的终端操作
终端操作执行中间操作链,并返回结果。终端操作我们就不一一介绍了,只介绍一下常用的操作。详细可看java.util.stream.Stream接口中的方法。
- void forEach(Consumer<? super T> action): 内部迭代(需要用户去做迭代,称为外部迭代。相反,Stream API使用内部迭代帮你把迭代做了)
users.stream().forEach(user -> System.out.println(user.getName()));
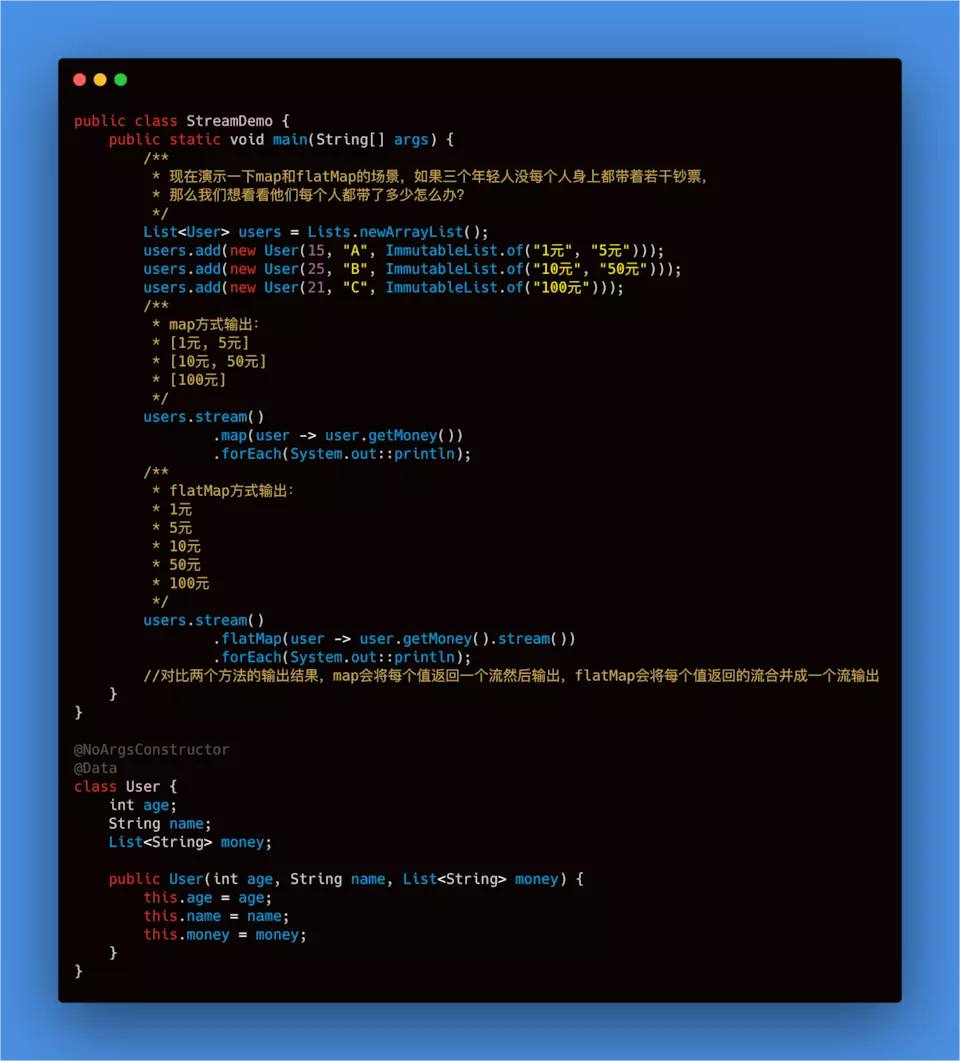
- <R, A> R collect(Collector<? super T, A, R> collector): 收集、将流转换为其他形式,比如转换成List、Set、Map。collect方法是用Collector作为参数,Collector接口中方法的实现决定了如何对流执行收集操作(如收集到 List、Set、Map)。但是 Collectors 实用类提供了很多静态方法,可以方便地创建常见收集器实例。例举一些常用的:
List<User> users = Lists.newArrayList();
users.add(new User(15, "A", ImmutableList.of("1元", "5元")));
users.add(new User(25, "B", ImmutableList.of("10元", "50元")));
users.add(new User(21, "C", ImmutableList.of("100元")));
//收集名称到List
List<String> nameList = users.stream().map(User::getName).collect(Collectors.toList());
//收集名称到List
Set<String> nameSet = users.stream().map(User::getName).collect(Collectors.toSet());
//收集到map,名字作为key,user对象作为value
Map<String, User> userMap = users.stream()
.collect(Collectors.toMap(User::getName, Function.identity(), (k1, k2) -> k2));
- 其他终端操作:
- boolean allMatch(Predicate<? super T> predicate); 检查是否匹配所有元素。
- boolean anyMatch(Predicate<? super T> predicate); 检查是否至少匹配一个元素。
- boolean noneMatch(Predicate<? super T> predicate); 检查是否没有匹配所有元素。
- Optional
<T>findFirst(); 返回当前流中的第一个元素。 - Optional
<T>findAny(); 返回当前流中的任意元素。 - long count(); 返回流中元素总数。
- Optional
<T>max(Comparator<? super T> comparator); 返回流中最大值。 - Optional
<T>min(Comparator<? super T> comparator); 返回流中最小值。 - T reduce(T identity, BinaryOperator
<T>accumulator); 可以将流中元素反复结合起来,得到一个值。 返回 T。这是一个归约操作。
Fork/Join框架
上面我们提到过,说Stream的并行模式使用了Fork/Join框架,这里简单说下Fork/Join框架是什么?Fork/Join框架是java7中加入的一个并行任务框架,可以将任务拆分为多个小任务,每个小任务执行完的结果在合并成为一个结果。在任务的执行过程中使用工作窃取(work-stealing)算法,减少线程之间的竞争。
- Fork/Join图解
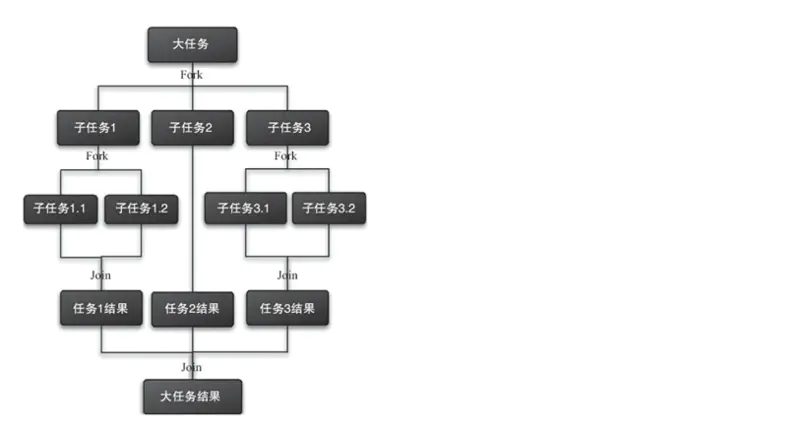
- 工作窃取图解

Stream是怎么实现的
先看下整体类图:蓝色箭头代表继承,绿色箭头代表实现,红色箭头代表内部类。
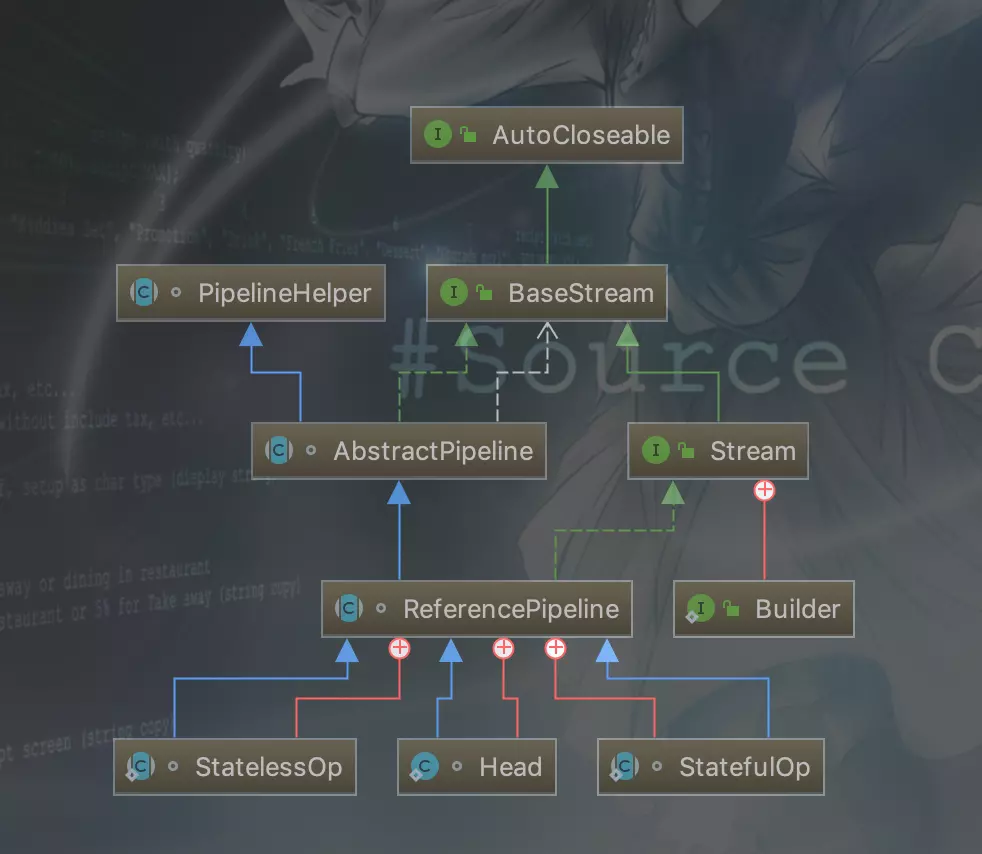 实际上Stream只有两种操作,中间操作、终端操作,中间操作只是一种标记,只有终端操作才会实际触发执行。所以Stream流水线式的操作大致应该是用某种方式记录中间操作,只有调用终端操作才会将所有的中间操作叠加在一起在一次迭代中全部执行。这里只做简单的介绍,想详细了解的可以参考下面的参考资料中的链接。
实际上Stream只有两种操作,中间操作、终端操作,中间操作只是一种标记,只有终端操作才会实际触发执行。所以Stream流水线式的操作大致应该是用某种方式记录中间操作,只有调用终端操作才会将所有的中间操作叠加在一起在一次迭代中全部执行。这里只做简单的介绍,想详细了解的可以参考下面的参考资料中的链接。
- 操作怎么记录?
Stream的操作记录是通过ReferencePipeline记录的,ReferencePipeline有三个内部类Head、StatelessOp、StatefulOp,Stream中使用Stage的概念来描述一个完整的操作,并用某种实例化后的ReferencePipeline来代表Stage,Head用于表示第一个Stage,即调用诸如Collection.stream()方法产生的Stage,很显然这个Stage里不包含任何操作,StatelessOp和StatefulOp分别表示无状态和有状态的Stage,对应于无状态和有状态的中间操作。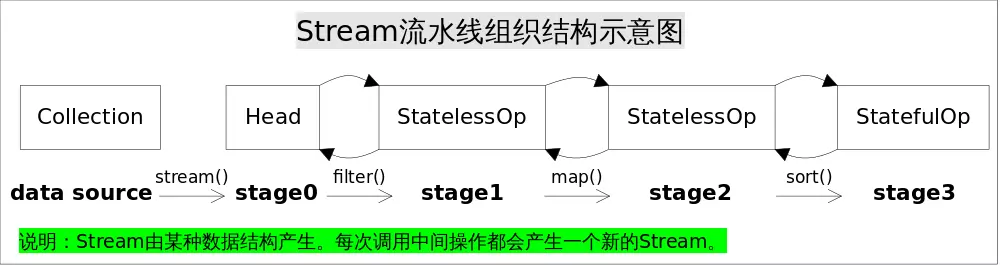
- 操作怎么叠加?
操作是记录完了,但是前面的Stage并不知道后面Stage到底执行了哪种操作,以及回调函数是哪种形式。这就需要有某种协议来协调相邻Stage之间的调用关系。 这种协议由Sink接口完成,Sink接口包含的方法如下表所示:
- void begin(long size),开始遍历元素之前调用该方法,通知Sink做好准备。
- void end(),所有元素遍历完成之后调用,通知Sink没有更多的元素了。
- boolean cancellationRequested(),是否可以结束操作,可以让短路操作尽早结束。
- void accept(T t),遍历元素时调用,接受一个待处理元素,并对元素进行处理。Stage把自己包含的操作和回调方法封装到该方法里,前一个Stage只需要调用当前Stage.accept(T t)方法就行了。
每个Stage都会将自己的操作封装到一个Sink里,前一个Stage只需调用后一个Stage的accept()方法即可,并不需要知道其内部是如何处理的。有了Sink对操作的包装,Stage之间的调用问题就解决了,执行时只需要从流水线的head开始对数据源依次调用每个Stage对应的Sink.{begin(), accept(), cancellationRequested(), end()}方法就可以了。
- 操作怎么执行?
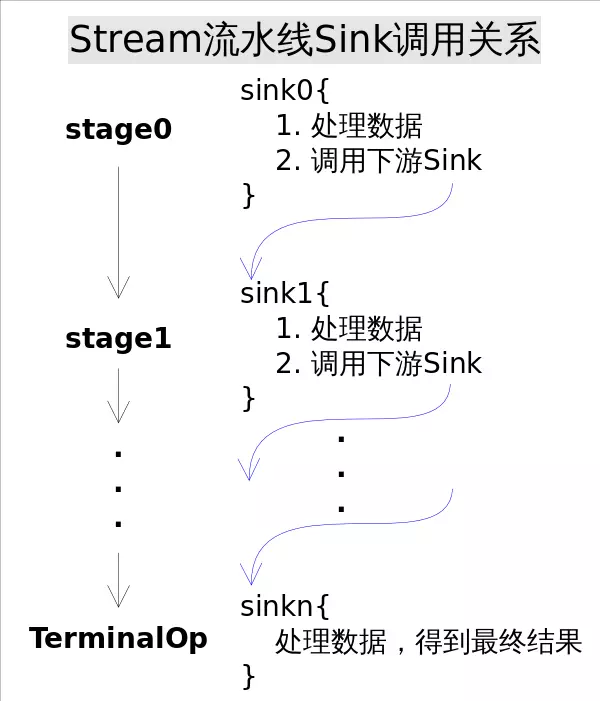 Sink完美封装了Stream每一步操作,并给出了[处理->转发]的模式来叠加操作。这一连串的齿轮已经咬合,就差最后一步拨动齿轮启动执行。是什么启动这一连串的操作呢?也许你已经想到了启动的原始动力就是结束操作(Terminal Operation),一旦调用某个结束操作,就会触发整个流水线的执行。
Sink完美封装了Stream每一步操作,并给出了[处理->转发]的模式来叠加操作。这一连串的齿轮已经咬合,就差最后一步拨动齿轮启动执行。是什么启动这一连串的操作呢?也许你已经想到了启动的原始动力就是结束操作(Terminal Operation),一旦调用某个结束操作,就会触发整个流水线的执行。