ITIL
TIL,即基础架构库(Information Technology Infrastructure Library,ITIL,信息技术基础架构库)由英国由英国政府部门CCTA(Central Computing and Telecommunications Agency)在20世纪80年代末制订,现由英国商务部OGC(Office of Government Commerce)负责管理,主要适用于IT服务管理(ITSM)。ITIL为企业的IT服务管理实践提供了一个客观、严谨、可量化的标准和规范。
1、事件管理(Incident Management)
事故管理负责记录、归类和安排专家处理事故并监督整个处理过程直至事故得到解决和终止。事故管理的目的是在尽可能最小地影响客户和用户业务的情况下使IT系统恢复到服务级别协议所定义的服务级别。
目标是:在不影响业务的情况下,尽可能快速的恢复服务,从而保证最佳的效率和服务的可持续性。事件管理流程的建立包括事件分类,确定事件的优先级和建立事件的升级机制。
2、问题管理(Problem Management)
问题管理是指通过调查和分析IT基础架构的薄弱环节、查明事故产生的潜在原因,并制定解决事故的方案和防止事故再次发生的措施,将由于问题和事故对业务产生的负面影响减小到最低的服务管理流程。与事故管理强调事故恢复的速度不同,问题管理强调的是找出事故产生的根源,从而制定恰当的解决方案或防止其再次发生的预防措施。
目标是:调查基础设施和所有可用信息,包括事件数据库,来确定引起事件发生的真正潜在原因,一起提供的服务中可能存在的故障。
3、配置管理(Configuration Management)
配置管理是识别和确认系统的配置项,记录和报告配置项状态和变更请求,检验配置项的正确性和完整性等活动构成的过程,其目的是提供IT基础架构的逻辑模型,支持其它服务管理流程特别是变更管理和发布管理的运作。
目标是:定义和控制服务与基础设施的部件,并保持准确的配置信息。
4、变更管理(Change Management)
变更管理是指为在最短的中断时间内完成基础架构或服务的任一方面的变更而对其进行控制的服务管理流程。变更管理的目标是确保在变更实施过程中使用标准的方法和步骤,尽快地实施变更,以将由变更所导致的业务中断对业务的影响减小到最低。
目标是:以受控的方式,确保所有变更得到评估、批准、实施和评审。
5、发布管理(Release Management)
发布管理是指对经过测试后导入实际应用的新增或修改后的配置项进行分发和宣传的管理流程。发布管理以前又称为软件控制与分发。
目标是:在实际运行环境的发布中,交付、分发并跟踪一个或多个变更。
IT运维分类
IT运维,指的是对已经搭建好的网络、软件、硬件进行维护。运维领域有硬件运维和软件运维。
- 硬件运维,主要包括对基础设施的运维,如机房的设备,主机的硬盘,内存这些物理设备的维护。
- 软件运维主要包括系统运维和应用运维,系统运维主要包括对OS,数据库,中间件的监控和维护,这些系统介于设备和应用之间,应用运维主要是对线上业务系统的运维。
软件运维自动化,包括系统运维和应用运维的自动化。
传统运维痛点
- 日常工作繁琐
日常运维工作是比较繁琐,研发同学会经常需要到服务器上查日志,重启应用,或者是说今天上线某个产品,需要部署下环境。这些琐事是传统运维的大部分工作
- 应用运行环境不统一
在部署某应用后,应用不能访问,就会听到开发人员说,在我的环境运行很好的,怎么部署到测试环境后,就不能用了,因为各类环境的类库不统一,还有一种极端情况,运维人员习惯不同,可能凭自己的习惯来安装部署软件,每种服务器上运行软件的目录不统一
- 运维及部署效率低下
想想运维人员需要登录到服务器上执行命令,部署程序,不仅效率很低,并且非常容易出现人为的错误,一旦手工出错,追溯问题将会非常不容易
- 无用报警信息过多
经常会收到很多报警信息,多数是无用的报警信息,造成运维人员经常屏蔽报警信息,另外如果应用的访问速度出了问题,总是需要从系统、网络、应用、数据库等一步步的查找原因
- 资产管理和应用管理混乱
资产管理,服务管理经常记录在excel,文本文件或者wiki中,不便于管理,老员工因为比较熟,不注重这些文档的维护,只有靠每次有新员工入职时,资产才能够更正一次
自动化运维平台的特性
运维自动化最重要的就是标准化一切
- OS的选择统一化,同一个项目使用同样的OS系统部署其所需要的各类软件
- 软件安装标准化,例如JAVA虚拟机,php,nginx,mysql等各类应用需要的软件版本,安装目录,数据存放目录,日志存放目录等
- 应用包目录统一标准化,及应用命名标准化
- 启动脚本统一目录和名字,需要变化的部分通过参数传递
- 配置文件标准化,需要变化的部分通过参数传递
- 日志输出,日志目录,日志名字标准化
- 应用生成的数据要实现统一的目录存放
- 主机/虚拟机命名标准化,虚拟机管理使用标准化模板
- 使用docker比较容易实现软件运行环境的标准化
资产管理系统(CMDB)
CMDB(Configuration Management Database)配置管理数据库,CMDB存储与管理企业IT架构中设备的各种配置信息,它与所有服务支持和服务交付流程都紧密相连,支持这些流程的运转、发挥配置信息的价值,同时依赖于相关流程保证数据的准确性。
在实际的项目中,CMDB常常被认为是构建其他ITIL流程的基础而优先考虑,ITIL项目的成败与是否建立CMDB有非常大的关系。
- 整合是指能够充分利用来自其他数据源的信息,对CMDB中包含的记录源属性进行存取,将多个数据源合并至一个视图中,生成连同来自CMDB和其他数据源信息在内的报告;
- 调和能力是指通过对来自每个数据源的匹配字段进行对比,保证CMDB中的记录在多个数据源中没有重复现象,维持CMDB中每个配置项目数据源的完整性;自动调整流程使得初始实施、数据库管理员的手动运作和现场维护支持工作降至最低;
- 同步指确保CMDB中的信息能够反映联合数据源的更新情况,在联合数据源更新频率的基础上确定CMDB更新日程,按照经过批准的变更来更新 CMDB,找出未被批准的变更;
- 应用映射与可视化,说明应用间的关系并反应应用和其他组件之间的依存关系,了解变更造成的影响并帮助诊断问题。
CMDB是运维自动化项目,它可以减少人工干预,降低人员成本。
功能:自动装机、实时监控、自动化部署软件,建立在它们的基础上是资产信息变更记录(资产管控自动进行汇报)
CMDB是所有运维工具的数据基础
CMDB包含的功能
- 用户管理、记录测试,开发,运维人员的用户表
- 业务线管理,需要记录业务的详情
- 项目管理,指定此项目用属于哪条业务线,以及项目详情
- 应用管理,指定此应用的开发人员,属于哪个项目,和代码地址,部署目录,部署集群,依赖的应用,软件等信息
- 主机管理,包括云主机,物理机,主机属于哪个集群,运行着哪些软件,主机管理员,连接哪些网络设备,云主机的资源池,存储等相关信息
- 主机变更管理,主机的一些信息变更,例如管理员,所属集群等信息更改,连接的网络变更等
- 网络设备管理,主要记录网络设备的详细信息,及网络设备连接的上级设备
- IP管理,IP属于哪个主机,哪个网段,是否被占用等
CMDB实现的四种方式
-
第一种:Agent实现方式(基于shell命令实现)
Agent方式,可以将服务器上面的Agent程序作定时任务,定时将资产信息提交到指定API录入数据库
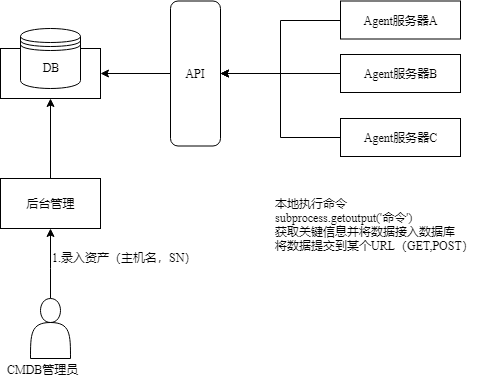
其本质上就是在各个服务器上执行subprocess.getoutput()命令,然后将每台机器上执行的结果,返回给主机API,然后主机API收到这些数据之后,放入到数据库中,最终通过web界面展现给用户


1.将subprocess执行的代码放到每台服务器上 2.定时(crontab)的执行收集代码,但结果还在服务器上 3.将执行的结果返回给我们的某一台收集的总服务器
优点:速度快
缺点:需要为每台服务器部署一个Agent程序
-
第二种:Paramiko类(SSH形式,基于Paramiko模块)
中控机通过Paramiko(py模块)登录到各个服务器上,然后执行命令的方式去获取各个服务器上的信息

优点:不需要为每台服务器部署一个Agent程序
缺点:速度慢
如果在服务器较少的情况下,可应用此方法
import paramiko
创建SSH对象
ssh = paramiko.SSHClient()
# 允许连接不在know_hosts文件中的主机
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
# 连接服务器
ssh.connect(hostname='c1.salt.com', port=22, username='root', password='123')
# 执行命令
stdin, stdout, stderr = ssh.exec_command('df')
# 获取命令结果
result = stdout.read()
# 关闭连接
ssh.close()
-
第三种:saltstack方式

此方案本质上和第二种方案大致是差不多的流程,中控机发送命令给服务器执行。服务器将结果放入另一个队列中,中控机获取将服务信息发送到API进而录入数据库
优点:开发成本低,速度快
缺点:依赖saltstack软件(第三方工具)
saltstack的安装和配置
1 安装和配置
master端:
"""
1. 安装salt-master
yum install salt-master
2. 修改配置文件:/etc/salt/master
interface: 0.0.0.0 # 表示Master的IP
3. 启动
service salt-master start
"""
slave端:
"""
1. 安装salt-minion
yum install salt-minion
2. 修改配置文件 /etc/salt/minion
master: 10.211.55.4 # master的地址
或
master:
- 10.211.55.4
- 10.211.55.5
random_master: True
id: c2.salt.com # 客户端在salt-master中显示的唯一ID
3. 启动
service salt-minion start
ps aux | grep salt-master #查看salt-master有没有启动
ps aux | grep salt-minion #查看salt-minion进程

2 授权
salt-key -L # 查看已授权和未授权的slave salt-key -a salve_id # 接受指定id的salve salt-key -r salve_id # 拒绝指定id的salve salt-key -d salve_id # 删除指定id的salve
salt-key -A #允许所有
3 执行命令
在master服务器上对salve进行远程操作
salt'c2.salt.com' cmd.run 'ifconfig'
或
salt "*" cmd.run "ifconfig" #向所有salt-minion发送命令
基于API的方式
import salt.client
local = salt.client.LocalClient()
result = local.cmd('c2.salt.com', 'cmd.run', ['ifconfig'])
参考安装
http://www.cnblogs.com/tim1blog/p/9987313.html
https://www.jianshu.com/p/84de3e012753
-
第四种:Puppet(ruby语言开发)(了解)
每隔30分钟,通过RPC消息队列将执行的结果返回给用户
基于Puppet的factor和report功能实现
1 puppet中默认自带了5个report,放置在【/usr/lib/ruby/site_ruby/1.8/puppet/reports/】路径下。如果需要执行某个report,那么就在puppet的master的配置文件中做如下配置: 2 3 ######################## on master ################### 4 /etc/puppet/puppet.conf 5 [main] 6 reports = store #默认 7 #report = true #默认 8 #pluginsync = true #默认 9 10 11 ####################### on client ##################### 12 13 /etc/puppet/puppet.conf 14 [main] 15 #report = true #默认 16 17 [agent] 18 runinterval = 10 19 server = master.puppet.com 20 certname = c1.puppet.com 21 22 如上述设置之后,每次执行client和master同步,就会在master服务器的 【/var/lib/puppet/reports】路径下创建一个文件,主动执行:puppet agent --test
自定义factor示例
1 在 /etc/puppet/modules 目录下创建如下文件结构: 2 3 modules 4 └── cmdb 5 ├── lib 6 │ └── puppet 7 │ └── reports 8 │ └── cmdb.rb 9 └── manifests 10 └── init.pp 11 12 ################ cmdb.rb ################ 13 # cmdb.rb 14 require 'puppet' 15 require 'fileutils' 16 require 'puppet/util' 17 18 SEPARATOR = [Regexp.escape(File::SEPARATOR.to_s), Regexp.escape(File::ALT_SEPARATOR.to_s)].join 19 20 Puppet::Reports.register_report(:cmdb) do 21 desc "Store server info 22 These files collect quickly -- one every half hour -- so it is a good idea 23 to perform some maintenance on them if you use this report (it's the only 24 default report)." 25 26 def process 27 certname = self.name 28 now = Time.now.gmtime 29 File.open("/tmp/cmdb.json",'a') do |f| 30 f.write(certname) 31 f.write(' | ') 32 f.write(now) 33 f.write(" ") 34 end 35 36 end 37 end 38 39 40 ################ 配置 ################ 41 /etc/puppet/puppet.conf 42 [main] 43 reports = cmdb 44 #report = true #默认 45 #pluginsync = true #默认
小结:
- 采集资产信息有四种不同的形式(puppet是基于ruby开发的)
- API提供相关处理接口
- 管理平台为用户提供可视化操作
传统运维和自动化运维的区别: 传统运维: 1. 项目上线: a. 产品经理前期调研 (需求分析) b. 和开发进行评审 c. 开发进行开发 d. 测试进行测试 e. 交给运维人员进行上线 上线: 直接将代码给运维人员,让业务运维人员把代码放到服务器上 痛点: 增加运维的成本 改进: 搞一个自动分发代码的系统 必须的条件: 服务器的信息(ip, hostname等) 2. 能不能把报警自动化 3. 装机系统: 传统的装机和布线: idc运维 用大量的人力和物力,来进行装机 自动运维: collober 自动发送命令装机 4. 收集服务器的元信息: a. excel表格 缺点: - 人为干预太严重 - 统计的时候也会有问题 b. 搞一个系统 作用: 自动的帮我收集服务器的信息,并且自动的记录我们的变更信息 cmdb: (********************) 作用: 自动的帮我收集服务器的信息,并且自动的记录我们的变更信息 愿景: 解放双手, 让所有的东西全部的都自动化 开始收集服务器的元数据: 在实际开发中,收集服务器的信息总共有4种方案: (****************************************) 1. agent方式: - agent脚本 - API - web界面 2. ssh类(parmiko, frbric, ansible) - parmiko模块 (获取主机名) - API - web界面 3. salt-stack方式(python3): - slat-stack软件 - API - web界面 4. puppet(ruby)(了解即可) 画图(echarts highcharts) 大致的步骤: 1. 收集服务器的信息 2. 数据提交给API 3. web页面展示 crontab: 13 11 * * * * python3 test.py > a.txt 分 时 日 月 周 年 Hexo + markdown 写博客 gap year 写代码: 三种CMDB采集的方案: - agent方式采集: - 场景: 服务器比较多 - 缺点: 需要每一台服务器上部署 - 优点: 速度快 - ssh类(parmiko fabric ansible): - 缺点: 速度慢 需要一台中控机 - 优点: 不需要部署agent脚本 - 场景: 服务器比较少 - salt-stack方式: - 缺点: 每一台需要部署这个软件 - 优点: 速度快, 开发成本低 - 场景: 企业之前已经在用 目标: 三种方案我们都要实现兼容 只需要改配置文件里面的一个配置,我们就能够自如的切换 采集服务器的信息代码编写(1/3) 项目的目录结构: - bin : 执行文件夹 - config: 自定义配置文件 - lib: 公共的模块或者类文件 - src: 核心业务逻辑代码 - tests: 测试的乱代码 配置文件的编写: 目标: 写一个类似于django的配置方法