简介
写这篇博客主要是为了进一步了解如何将CNN当作Encoder结构来使用,同时这篇论文也是必看的论文之一。该论文证明了使用CNN作为特征抽取结构实现Seq2Seq,可以达到与 RNN 相接近甚至更好的效果,并且CNN的高并行能力能够大大减少我们的模型训练时间(本文对原文中不清晰的部分做了梳理,建议与原文搭配服用)
原文链接:Convolutional Sequence to Sequence Learning
模型结构如下图所示:
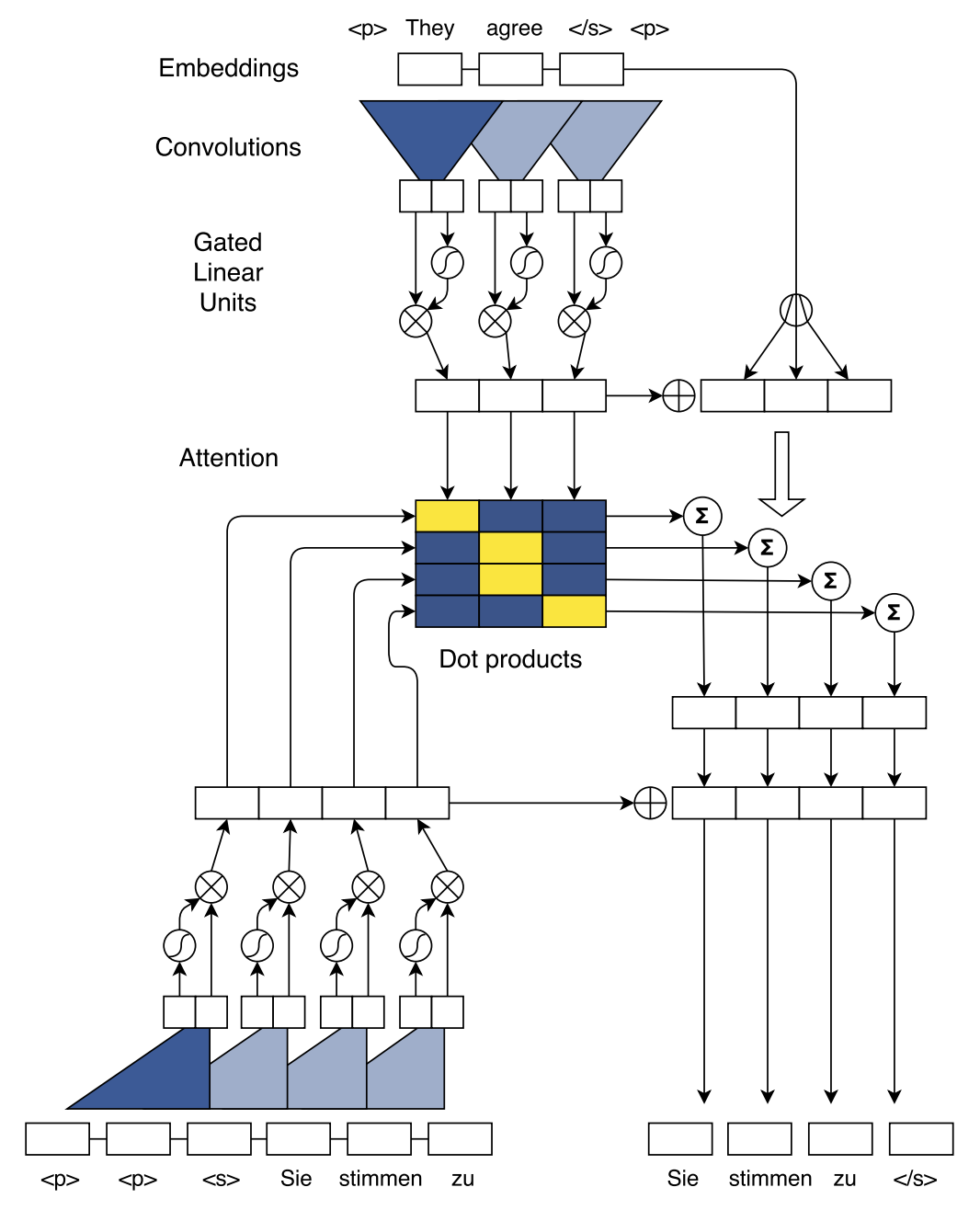
下面对模型的每个部分进行分块介绍:
Position Embeddings
卷积网络和Transformer一样,不是类似于RNN的时序模型,因此需要加入位置编码来体现词与词之间的位置关系
- 样本输入的词向量:(w = (w_1, w_2, ..., w_n))
- 样本位置编码:(p = (p_1, p_2, ..., p_n))
- 最终词向量表征:(e = (w_1 + p_1, w_2 + p_2, ..., w_n + p_n))
GLU or GRU
GLU和GTU是在同一篇论文中提出的,其中,GLU也是CNN Seq2Seq的主要结构。可以直接将其当作激活函数来看待,其将某以卷积核的输出输入到两个结构相同的卷积网络,令其中一个的输出为(A),另一个为(B)。
GLU与GRU的区别就在于A输出的激活函数不同:
而CNN Seq2Seq就采用了GLU作为模型的激活函数
原文链接:Language Modeling with Gated Convolutional Networks
Convolutional Block Structure
编码器与解码器都是由多个卷积层构成的(原文中称为block,实际上就是layer),每一层包含一个1维卷积核以及一个门控线性单元(Gated linear units, GLU)。假设单词数即输入长度为(m),kernel大小为(k),pad为(p),那么计算输出sequence长度的公式为((m+2p-k)/stride+1),只要适当的设置卷积核的kernel大小、pad以及步长参数,即可使得输出序列与输入序列的维度保持一致。在文中,输入为25,kernel为5,则输出序列长度为((25+2*2-5)/1+1=25)。
另外,为了充分让输出节点跟整个sequence单词有联系,必须使用多个卷积层,这样才能使得最后一个卷积核有足够大得感受野以感受整个句子的特征,同时也能捕捉局部句子的特征。
来看一下整个编码器的前向传播方式:
- 每次输入到卷积核的句子的大小为(X in R^{k imes d}),表明每次卷积核能够读取的序列长度为(k),也就是卷积核的宽度为(k),词向量维度为(d)
- 卷积核的权重矩阵大小为(W^{2d imes k imes d}),偏置向量为(b_W in R^{2d}),表明每一层有(2d)个卷积核,因此输出序列的维度为(2d),而由于事先的设计,使得输入序列与输出序列的长度是相同的,因此经过卷积之后,得到的序列的矩阵大小为(Y in R^{k imes 2d})。
- 我们将上面的(2d)个卷积核分为两个部分,这两个部分的卷积核尺寸与个数完全相同,输出维度也完全相同,则可以将其当作(GLU)的两个输入,输入到GLU整合过后,输出的序列维度又变为了(hat{Y} in R^{k imes d})
- 为了能够实现深层次的网络,在每一层的输入和输出之间采用了残差结构
- 对于解码序列来说,我们需要提取解码序列的隐藏表征,但是解码序列的解码过程是时序递归的,即我们无法观测到当前预测对象之后的序列,因此论文作者将输入的decoder序列
这样的卷积策略保证了每一层的输入与输出序列的一一对应,并且能够将其看作简单的编码器单元,多层堆叠以实现更深层次的编码。
Multi-step Attention
对于Attention的计算,关键就是找到 Query、Key 和 Value。下图为计算Attention且解码的示意图

Attention的计算过程如下:
- Query由decoder的最后一个卷积层的输出(h_i^l)以及上一时刻decoder最终的生成的目标(g_i)共同决定,(W^l_d)与(b_d^l)为线性映射的参数。
- Key 则采用 Encoder 的输出(z_j^u),典型的二维匹配模型,将 Query 与 Key 一一对齐,计算 dot attention分数:
- Value 的值则取编码器的输出(z_j^u)以及词向量表征(e_j)之和,目的是为编码器的输出加上位置表征信息。得到对应的 Value 值 (c_i^l) 之后,直接与当前时刻的 Decoder 输出 (h_i^l) 相加,再输入分类器进行分类。
Normalization Strategy
模型还通过归一化策略来保证通过每一层模型的方差变化不会太大,这里先简单的记录一下,具体的操作细节需要回去仔细琢磨代码。归一化的主要策略如下:
- 对残差网络的输入和输出乘以 (sqrt{0.5}) 来保证输入和输出的方差减半(这假设两侧的方差是相等的,虽然这不是总是正确的,但是实验证明这样做是有效的)
- 由于注意力模块的输出向量为 m 个向量的加权和,因此将其乘以 (m sqrt{m}) 来抵消方差的变化,其中,乘以 (m) 是为了将向量放大到原始的大小(实际中通常不会这么做,但是这么做的效果良好)
- 由于采用了多重注意力机制的卷积解码器,作者根据注意力机制的数量来对反向传播到编码器的梯度进行压缩,这可以避免编码器接收过多的梯度信息,使得训练变得更加平稳。
Initialization
初始化的目的与归一化是一致的,即都是为了保证前向与后项传播的数据方差能够保持在一个较稳定的水准,模型初始化的策略如下:
- 此前如层都由平均值为0以及标准差为0.1的正太分布进行初始化。
- 对于其输出未直接输入门控线性单元的层,我们以正态分布 (N(0, sqrt{1/n_l})) 来初始化权重,其中 (n_l) 是每个神经元的输入连接个数。 这样可以确保正太分布的输入的方差得以保留
- 对于输出与GLU相连的层,我们采取不同的策略。如果GLU的输入的均值为0且方差足够小,则输出方差可以近似等于输入方差的1/4。 因此,需要初始化权重使得GLU激活的输入具有该层输入方差的4倍,即该层的初始化分布为 (N(0, sqrt{4/n_l}))。
- 此外,每一层的偏置 (b) 统一设置为0
- 另外,考虑到 dropout 也会影响数据的方差分布,假设dropout的保留概率为p,则方差将放大为 (1/p) 倍,因此上述提到的初始化策略需要修正为: (N(0, sqrt{p/n_l})) 以及 (N(0, sqrt{4p/n_l}))
最后的实验部分就不记录了,有兴趣的同学可以去原文里看看。
https://zhuanlan.zhihu.com/p/26918935
https://zhuanlan.zhihu.com/p/27464080
https://www.zhihu.com/question/59645329/answer/170014414