用 ceph-deploy 从管理节点建立一个 Ceph 存储集群,该集群包含三个节点,以此探索 Ceph 的功能。

创建一个 Ceph 存储集群,它有一个 Monitor 和两个 OSD 守护进程。一旦集群达到 active + clean 状态,再扩展它:增加第三个 OSD 、增加元数据服务器和两个 Ceph Monitors。为获得最佳体验,先在管理节点上创建一个目录,用于保存 ceph-deploy 生成的配置文件和密钥对。
切换到上一步创建的ceph_user普通用户后再执行如下命令
su - ceph_user
mkdir my-cluster
cd my-cluster
ceph-deploy 会把文件输出到当前目录,所以请确保在此目录下执行 ceph-deploy 。
如果你是用另一普通用户登录的,不要用 sudo 或在 root 身份运行 ceph-deploy ,因为它不会在远程主机上调用所需的 sudo 命令。
禁用 requiretty
在某些发行版(如 CentOS )上,执行 ceph-deploy 命令时,如果你的 Ceph 节点默认设置了 requiretty 那就会遇到报错。可以这样禁用此功能:执行 sudo visudo ,找到 Defaults requiretty 选项,把它改为 Defaults:ceph !requiretty ,这样 ceph-deploy 就能用 ceph 用户登录并使用 sudo 了。
创建集群
如果在某些地方碰到麻烦,想从头再来,可以用下列命令清除配置:
ceph-deploy purgedata {ceph-node} [{ceph-node}]
ceph-deploy forgetkeys
用下列命令可以连 Ceph 安装包一起清除:
ceph-deploy purge {ceph-node} [{ceph-node}]
如果执行了 purge ,你必须重新安装 Ceph 。
在管理节点上,进入刚创建的放置配置文件的目录,用 ceph-deploy 执行如下步骤。
1.创建集群。
# 命令举例: ceph-deploy new {initial-monitor-node(s)}
# 实际执行如下这个命令
ceph-deploy new node1
执行这个命令后报错如下:
$ ceph-deploy new node1
Traceback (most recent call last):
File "/bin/ceph-deploy", line 18, in <module>
from ceph_deploy.cli import main
File "/usr/lib/python2.7/site-packages/ceph_deploy/cli.py", line 1, in <module>
import pkg_resources
ImportError: No module named pkg_resources
解决办法:
# 其他主机上也执行这个命令
# yum install gcc python-setuptools python-devel -y
在当前目录下用 ls 和 cat 检查 ceph-deploy 的输出,应该有一个 Ceph 配置文件、一个 monitor 密钥环和一个日志文件。
$ ll
总用量 12
-rw-rw-r--. 1 ceph_user ceph_user 195 11月 30 16:45 ceph.conf
-rw-rw-r--. 1 ceph_user ceph_user 3166 11月 30 16:45 ceph-deploy-ceph.log
-rw-------. 1 ceph_user ceph_user 73 11月 30 16:45 ceph.mon.keyring
2.把 Ceph 配置文件里的默认副本数从 3 改成 2 ,这样只有两个 OSD 也可以达到 active + clean 状态。把下面这行加入 [global] 段:
osd pool default size = 2
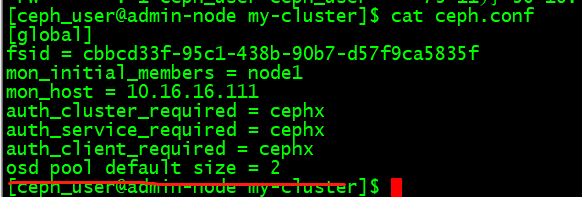
3.如果你有多个网卡,可以把 public network 写入 Ceph 配置文件的 [global] 段下。
这个根据实际情况设置一下,若不设置,在下面步骤添加mon的时候会报错,还是的添加这个的。
public network = {ip-address}/{netmask}
4.安装 Ceph
# 命令示例:ceph-deploy install {ceph-node} [{ceph-node} ...]
$ ceph-deploy install admin-node node1 node2 node3
报错如下:
[ceph_deploy][ERROR ] RuntimeError: NoSectionError: No section: 'ceph'
解决办法: yum remove -y ceph-release
把这个东西卸了,应该是这个的版本不兼容。
ceph-deploy 将在各节点安装 Ceph 。
注:如果你执行过 ceph-deploy purge ,你必须重新执行这一步来安装 Ceph 。
5.配置初始 monitor(s)、并收集所有密钥,完成上述操作后,当前目录里应该会出现这些密钥环:
$ ceph-deploy mon create-initial
$ ll
总用量 540
-rw-------. 1 ceph_user ceph_user 113 11月 30 17:21 ceph.bootstrap-mds.keyring
-rw-------. 1 ceph_user ceph_user 113 11月 30 17:21 ceph.bootstrap-mgr.keyring
-rw-------. 1 ceph_user ceph_user 113 11月 30 17:21 ceph.bootstrap-osd.keyring
-rw-------. 1 ceph_user ceph_user 113 11月 30 17:21 ceph.bootstrap-rgw.keyring
-rw-------. 1 ceph_user ceph_user 151 11月 30 17:21 ceph.client.admin.keyring
-rw-rw-r--. 1 ceph_user ceph_user 220 11月 30 16:56 ceph.conf
-rw-rw-r--. 1 ceph_user ceph_user 273213 11月 30 17:21 ceph-deploy-ceph.log
-rw-------. 1 ceph_user ceph_user 73 11月 30 16:45 ceph.mon.keyring
只有在安装 Hammer 或更高版时才会创建 bootstrap-rgw 密钥环。
如果此步失败并输出类似于如下信息 “Unable to find /etc/ceph/ceph.client.admin.keyring”,请确认 ceph.conf 中为 monitor 指定的 IP 是 Public IP,而不是 Private IP。
1.添加两个 OSD 。
如何为 OSD 及其日志使用独立硬盘或分区,请参考 ceph-deploy osd 。http://docs.ceph.org.cn/rados/deployment/ceph-deploy-osd/
官网文档使用的是目录,但是在实际操作的过程中,下一步的命令发生改变了,没找到怎么使用目录来创建的,这里采用裸盘的方式。
给node2和node3均新增一个20G的磁盘,也就是:/dev/vdb (根据实际情况来定)
然后,从管理节点执行 ceph-deploy 来准备 OSD 。
# 命令示例:ceph-deploy osd prepare {ceph-node}:/path/to/directory
# 这个命令废弃了: ceph-deploy osd prepare node2:/var/local/osd0 node3:/var/local/osd1
# 使用裸磁盘的方式
$ ceph-deploy osd create --data /dev/vdb node2
$ ceph-deploy osd create --data /dev/vdb node3
最后,激活 OSD 。
create 命令是依次执行 prepare 和 activate 命令的捷径。
上一步执行过create了,表示的是已经激活OSD了。
查看详情
$ ceph-deploy osd list node2
2.用 ceph-deploy 把配置文件和 admin 密钥拷贝到管理节点和 Ceph 节点,这样你每次执行 Ceph 命令行时就无需指定 monitor 地址和 ceph.client.admin.keyring 了。
# 命令示例:ceph-deploy admin {admin-node} {ceph-node}
$ ceph-deploy admin admin-node node1 node2 node3
ceph-deploy 和本地管理主机( admin-node )通信时,必须通过主机名可达。必要时可修改 /etc/hosts ,加入管理主机的名字。 (这一步在上一篇文章中已经做过了)
3.确保你对 ceph.client.admin.keyring 有正确的操作权限。
sudo chmod +r /etc/ceph/ceph.client.admin.keyring
4.创建mgr进程
$ ceph-deploy mgr create node1
若是不执行这一步,执行健康检查提示如下
$ ceph health
HEALTH_WARN no active mgr
5.检查集群的健康状况。
$ ceph health
等 peering 完成后,集群应该达到 active + clean 状态。
操作集群
用 ceph-deploy 部署完成后它会自动启动集群。要在 Debian/Ubuntu 发行版下操作集群守护进程,参见用 Upstart 运行 Ceph ;http://docs.ceph.org.cn/rados/operations/operating#rupstart-ceph
要在 CentOS 、 Red Hat 、 Fedora 和 SLES 下操作集群守护进程,参见用 sysvinit 运行 Ceph 。http://docs.ceph.org.cn/rados/operations/operating#sysvinit-ceph
关于 peering 和集群健康状况请参见监控集群;http://docs.ceph.org.cn/rados/operations/monitoring
关于 OSD 守护进程和归置组( placement group )健康状况参见监控 OSD 和归置组;http://docs.ceph.org.cn/rados/operations/monitoring-osd-pg
关于用户管理请参见用户管理。http://docs.ceph.org.cn/rados/operations/user-management
Ceph 集群部署完成后,你可以尝试一下管理功能、 rados 对象存储命令,之后可以继续快速入门手册,了解 Ceph 块设备、 Ceph 文件系统和 Ceph 对象网关。
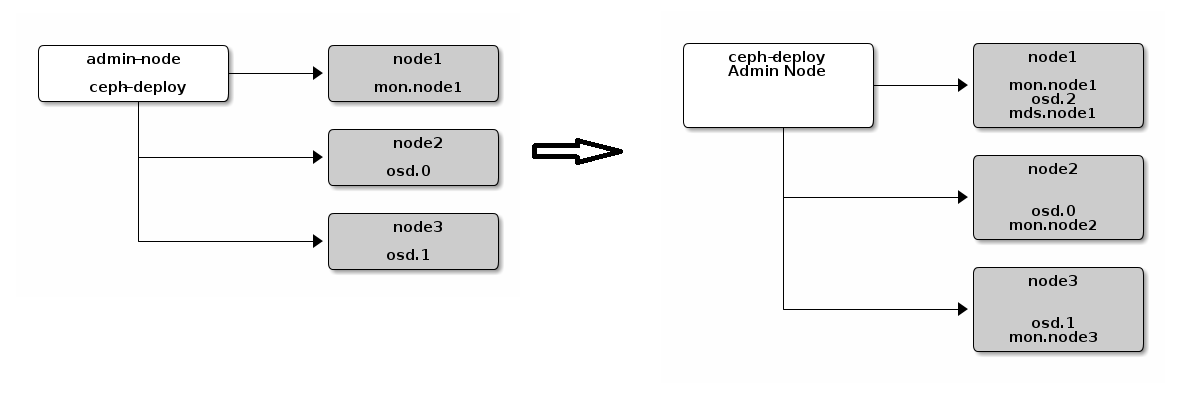
扩展集群(扩容)
一个基本的集群启动并开始运行后,下一步就是扩展集群。在 node1 上添加一个 OSD 守护进程和一个元数据服务器。然后分别在 node2 和 node3 上添加 Ceph Monitor ,以形成 Monitors 的法定人数。
注意:还是切换到普通用户ceph_user,在my_cluster目录下执行,不然会报错:[ceph_deploy][ERROR ] ConfigError: Cannot load config: [Errno 2] No such file or directory: 'ceph.conf'; has
ceph-deploy newbeen run in this directory?
1.添加 OSD
运行的这个三节点集群只是用于演示的,把 OSD 添加到 monitor 节点就行。
官方文档上给的是在node1节点上创建目录来添加,但是参考上面的步骤,目录形式的没有走通,这里还采用在node1节点上新增磁盘的方式来添加OSD
命令参数:
[ceph_user@admin-node my-cluster]$ ceph-deploy osd create --help
usage: ceph-deploy osd create [-h] [--data DATA] [--journal JOURNAL]
[--zap-disk] [--fs-type FS_TYPE] [--dmcrypt]
[--dmcrypt-key-dir KEYDIR] [--filestore]
[--bluestore] [--block-db BLOCK_DB]
[--block-wal BLOCK_WAL] [--debug]
[HOST]
positional arguments:
HOST Remote host to connect
optional arguments:
-h, --help show this help message and exit
--data DATA The OSD data logical volume (vg/lv) or absolute path
to device
--journal JOURNAL Logical Volume (vg/lv) or path to GPT partition
--zap-disk DEPRECATED - cannot zap when creating an OSD
--fs-type FS_TYPE filesystem to use to format DEVICE (xfs, btrfs)
--dmcrypt use dm-crypt on DEVICE
--dmcrypt-key-dir KEYDIR
directory where dm-crypt keys are stored
--filestore filestore objectstore
--bluestore bluestore objectstore
--block-db BLOCK_DB bluestore block.db path
--block-wal BLOCK_WAL
bluestore block.wal path
--debug Enable debug mode on remote ceph-volume calls
# 使用裸磁盘的方式
$ ceph-deploy osd create --data /dev/vdb node1
一旦你新加了 OSD , Ceph 集群就开始重均衡,把归置组迁移到新 OSD 。可以用下面的 ceph 命令观察此过程:
$ ceph -w
cluster:
id: cbbcd33f-95c1-438b-90b7-d57f9ca5835f
health: HEALTH_OK
services:
mon: 1 daemons, quorum node1
mgr: node1(active)
osd: 3 osds: 3 up, 3 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 3.0 GiB used, 57 GiB / 60 GiB avail
pgs:
能看到归置组状态从 active + clean 变为 active ,还有一些降级的对象;迁移完成后又会回到 active + clean 状态( Control-C 退出)。
2.添加元数据服务器
至少需要一个元数据服务器才能使用 CephFS ,执行下列命令创建元数据服务器:
# 命令示例:ceph-deploy mds create {ceph-node}
$ ceph-deploy mds create node1
当前生产环境下的 Ceph 只能运行一个元数据服务器。你可以配置多个,但现在我们还不会为多个元数据服务器的集群提供商业支持。
3.添加 RGW 例程
要使用 Ceph 的 Ceph 对象网关组件,必须部署 RGW 例程。用下列方法创建新 RGW 例程:
# 命令示例:ceph-deploy rgw create {gateway-node}
$ ceph-deploy rgw create node1

这个功能是从 Hammer 版和 ceph-deploy v1.5.23 才开始有的。
RGW 例程默认会监听 7480 端口,可以更改该节点 ceph.conf 内与 RGW 相关的配置,如下:
[client]
rgw frontends = civetweb port=80
用的是 IPv6 地址的话:
[client]
rgw frontends = civetweb port=[::]:80
4.添加 Monitors
Ceph 存储集群需要至少一个 Monitor 才能运行。
为达到高可用,典型的 Ceph 存储集群会运行多个 Monitors,这样在单个 Monitor 失败时不会影响 Ceph 存储集群的可用性。
Ceph 使用 PASOX 算法,此算法要求有多半 monitors(即 1 、 2:3 、 3:4 、 3:5 、 4:6 等 )形成法定人数。
新增两个监视器到 Ceph 集群
# 命令示例:ceph-deploy mon add {ceph-node}
$ ceph-deploy mon add node2
$ ceph-deploy mon add node3
报错:
[node2][DEBUG ] create the init path if it does not exist
[node2][INFO ] Running command: sudo systemctl enable ceph.target
[node2][INFO ] Running command: sudo systemctl enable ceph-mon@node2
[node2][WARNIN] Created symlink from /etc/systemd/system/ceph-mon.target.wants/ceph-mon@node2.service to /usr/lib/systemd/system/ceph-mon@.service.
[node2][INFO ] Running command: sudo systemctl start ceph-mon@node2
[node2][INFO ] Running command: sudo ceph --cluster=ceph --admin-daemon /var/run/ceph/ceph-mon.node2.asok mon_status
[node2][ERROR ] admin_socket: exception getting command descriptions: [Errno 2] No such file or directory
[node2][WARNIN] node2 is not defined in `mon initial members`
[node2][WARNIN] monitor node2 does not exist in monmap
[node2][WARNIN] neither `public_addr` nor `public_network` keys are defined for monitors
[node2][WARNIN] monitors may not be able to form quorum
[node2][INFO ] Running command: sudo ceph --cluster=ceph --admin-daemon /var/run/ceph/ceph-mon.node2.asok mon_status
[node2][ERROR ] admin_socket: exception getting command descriptions: [Errno 2] No such file or directory
[node2][WARNIN] monitor: mon.node2, might not be running yet

由下面这条警告知道,在ceph.conf配置文件中缺少 pubulic network的描述。
[node2][WARNIN] neither `public_addr` nor `public_network` keys are defined for monitors
因此,在admin节点修改ceph.conf文件,新增下面这行(根据实际网段来设置)
public network = 10.16.16.0/24
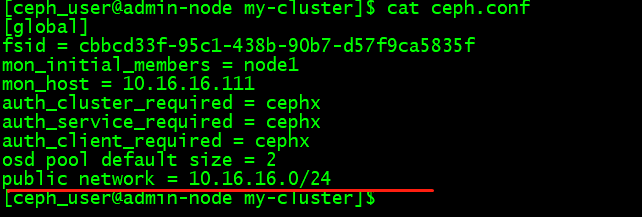
然后,将修改的ceph.conf推送到各个节点上:
ceph-deploy --overwrite-conf config push node1 node2 node3
新增 Monitor 后,Ceph 会自动开始同步并形成法定人数。你可以用下面的命令检查法定人数状态:
$ ceph quorum_status --format json-pretty
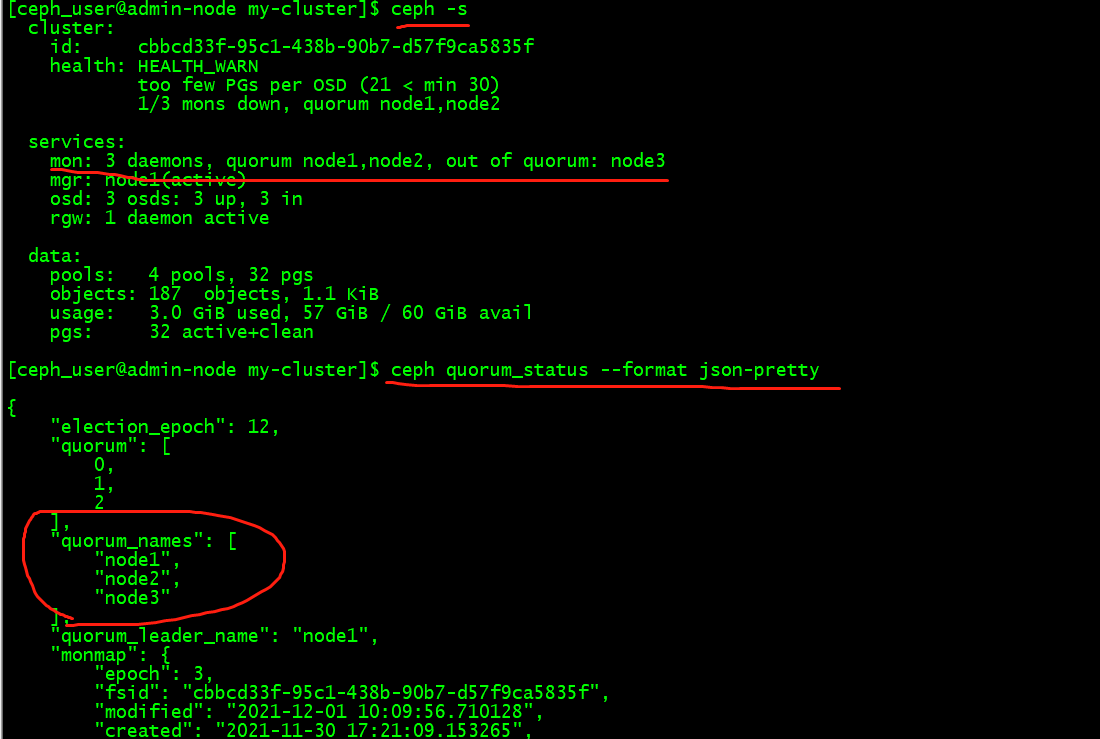
当你的 Ceph 集群运行着多个 monitor 时,各 monitor 主机上都应该配置 NTP ,而且要确保这些 monitor 位于 NTP 服务的同一级。
此时再查看ceph 状态,会提示:too few PGs per OSD (21 < min 30)
$ ceph -s
cluster:
id: cbbcd33f-95c1-438b-90b7-d57f9ca5835f
health: HEALTH_WARN
too few PGs per OSD (21 < min 30)
services:
mon: 3 daemons, quorum node1,node2,node3
mgr: node1(active)
osd: 3 osds: 3 up, 3 in
rgw: 1 daemon active
data:
pools: 4 pools, 32 pgs
objects: 219 objects, 1.1 KiB
usage: 3.0 GiB used, 57 GiB / 60 GiB avail
pgs: 32 active+clean
具体来说是因为创建ceph后,默认创建的pool中,pg_num和pgp_num不符合规范,
查看现有pool列表(默认创建的pool)
$ ceph osd lspools
1 .rgw.root
2 default.rgw.control
3 default.rgw.meta
4 default.rgw.log
通常在创建pool之前,需要覆盖默认的pg_num,官方推荐:
若少于5个OSD, 设置pg_num为128。510个OSD,设置pg_num为512。1050个OSD,设置pg_num为4096。超过50个OSD,可以参考pgcalc计算。
这里只有3个OSD,因此设置pg_num为128,pgp_num也是128
默认的pool不动,直接创建新的pool,指定pg_num和pgp_num就行了
# 创建一个新的pool
$ ceph osd pool create rbd 128 128
pool 'rbd' created
# 查看pool列表
$ ceph osd lspools
1 .rgw.root
2 default.rgw.control
3 default.rgw.meta
4 default.rgw.log
5 rbd
# 查看状态
$ ceph -s
cluster:
id: cbbcd33f-95c1-438b-90b7-d57f9ca5835f
health: HEALTH_OK
services:
mon: 3 daemons, quorum node1,node2,node3
mgr: node1(active)
osd: 3 osds: 3 up, 3 in
rgw: 1 daemon active
data:
pools: 5 pools, 160 pgs
objects: 219 objects, 1.1 KiB
usage: 3.0 GiB used, 57 GiB / 60 GiB avail
pgs: 160 active+clean
io:
client: 4.7 KiB/s rd, 0 B/s wr, 4 op/s rd, 3 op/s wr
附加知识
删除pool
# 说明:pool名字要输入两次,另外如果是缓存卷,无法删除。
$ ceph osd pool rm test-pool test-pool --yes-i-really-really-mean-it
Error EPERM: pool deletion is disabled; you must first set the mon_allow_pool_delete config option to true before you can destroy a pool
# 提示没有删除pool权限
# 添加删除pool权限,ceph-deploy主机上操作
$ cat /etc/ceph/ceph.conf
[global]
mon_allow_pool_delete = true
# 分发配置文件,ceph-deploy主机上操作
$ ceph-deploy --overwrite-conf config push node1 node2 node3
# 重启mon,在node1 node2 node3三台主机上都执行
systemctl restart ceph-mon.target
# 最后再删除就可以了
$ ceph osd pool rm test-pool test-pool --yes-i-really-really-mean-it
pool 'test-pool' removed
存入/检出对象数据 (暂时看不懂,未操作)
要把对象存入 Ceph 存储集群,客户端必须做到:
1.指定对象名
2.指定存储池
Ceph 客户端检出最新集群运行图,用 CRUSH 算法计算出如何把对象映射到归置组,然后动态地计算如何把归置组分配到 OSD 。要定位对象,只需要对象名和存储池名字即可,例如:
# 命令示例:ceph osd map {poolname} {object-name}
练习:定位某个对象
先创建一个对象,用 rados put 命令加上对象名、一个有数据的测试文件路径、并指定存储池。例如:
echo {Test-data} > testfile.txt
rados put {object-name} {file-path} --pool=data
rados put test-object-1 testfile.txt --pool=data
为确认 Ceph 存储集群存储了此对象,可执行:
rados -p data ls
现在,定位对象:
ceph osd map {pool-name} {object-name}
ceph osd map data test-object-1
Ceph 应该会输出对象的位置,例如:
osdmap e537 pool 'data' (0) object 'test-object-1' -> pg 0.d1743484 (0.4) -> up [1,0] acting [1,0]
用rados rm 命令可删除此测试对象,例如:
rados rm test-object-1 --pool=data
随着集群的运行,对象位置可能会动态改变。 Ceph 有动态均衡机制,无需手动干预即可完成。