环境介绍:
- CentOS: 7.6
- Docker: 18.06.1-ce
- Kubernetes: 1.13.4
- Kuberadm: 1.13.4
- Kuberlet: 1.13.4
- Kuberctl: 1.13.4
部署介绍:
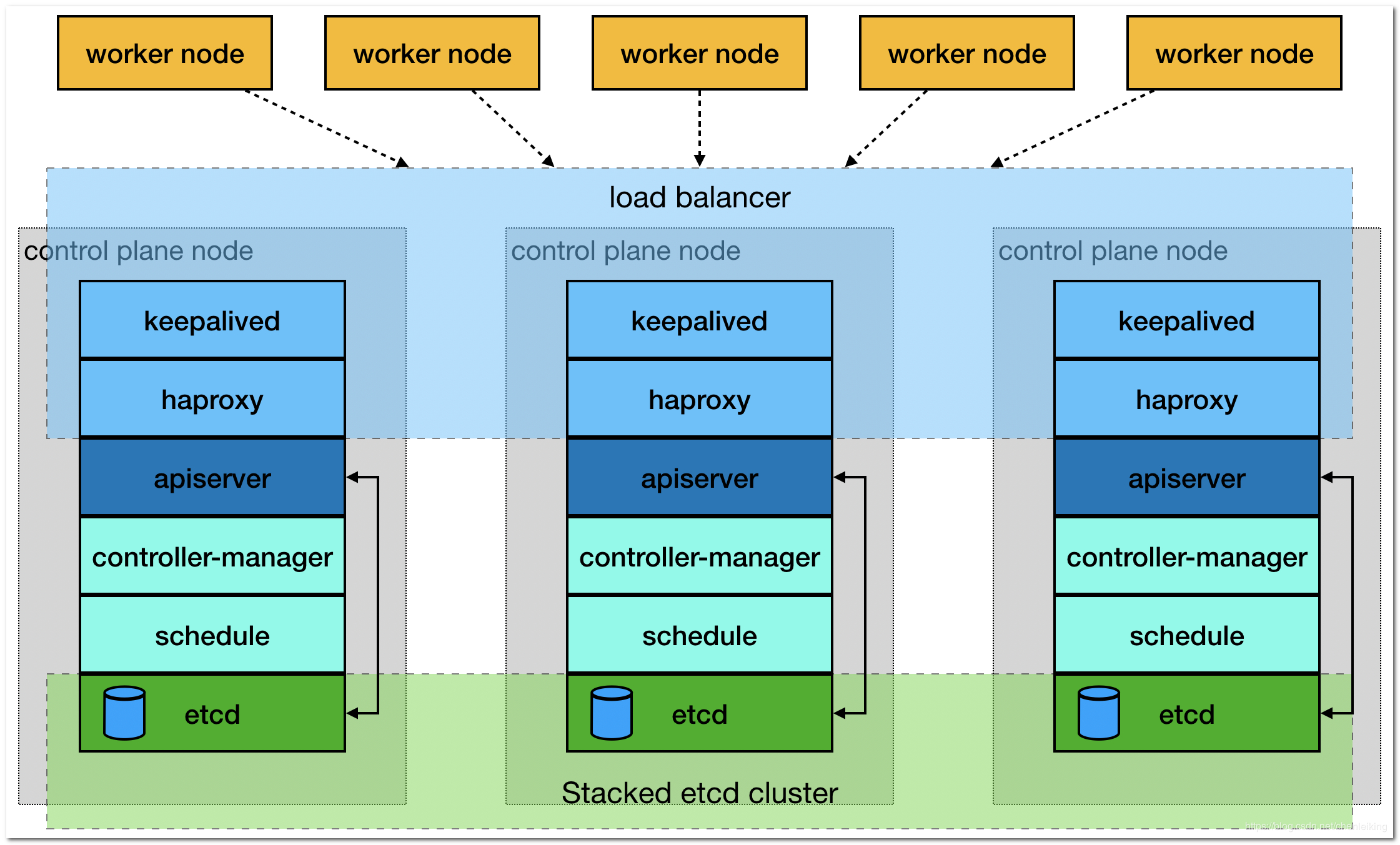
创建高可用首先先有一个 Master 节点,然后再让其他服务器加入组成三个 Master 节点高可用,然后再讲工作节点 Node 加入。下面将描述每个节点要执行的步骤:
- Master01: 二、三、四、五、六、七、八、九、十一
- Master02、Master03: 二、三、五、六、四、九
- node01、node02: 二、五、六、九
集群架构:
一、kuberadm 简介
Kuberadm 作用
Kubeadm 是一个工具,它提供了 kubeadm init 以及 kubeadm join 这两个命令作为快速创建 kubernetes 集群的最佳实践。
kubeadm 通过执行必要的操作来启动和运行一个最小可用的集群。它被故意设计为只关心启动集群,而不是之前的节点准备工作。同样的,诸如安装各种各样值得拥有的插件,例如 Kubernetes Dashboard、监控解决方案以及特定云提供商的插件,这些都不在它负责的范围。
相反,我们期望由一个基于 kubeadm 从更高层设计的更加合适的工具来做这些事情;并且,理想情况下,使用 kubeadm 作为所有部署的基础将会使得创建一个符合期望的集群变得容易。
Kuberadm 功能
- kubeadm init: 启动一个 Kubernetes 主节点
- kubeadm join: 启动一个 Kubernetes 工作节点并且将其加入到集群
- kubeadm upgrade: 更新一个 Kubernetes 集群到新版本
- kubeadm config: 如果使用 v1.7.x 或者更低版本的 kubeadm 初始化集群,您需要对集群做一些配置以便使用 kubeadm upgrade 命令
- kubeadm token: 管理 kubeadm join 使用的令牌
- kubeadm reset: 还原 kubeadm init 或者 kubeadm join 对主机所做的任何更改
- kubeadm version: 打印 kubeadm 版本
- kubeadm alpha: 预览一组可用的新功能以便从社区搜集反馈
功能版本
| Area | Maturity Level |
|---|---|
| Command line UX | GA |
| Implementation | GA |
| Config file API | beta |
| CoreDNS | GA |
| kubeadm alpha subcommands | alpha |
| High availability | alpha |
| DynamicKubeletConfig | alpha |
| Self-hosting | alpha |
二、前期准备
1、虚拟机分配说明
| 地址 | 主机名 | 内存&CPU | 角色 |
|---|---|---|---|
| 192.168.2.10 | — | — | vip |
| 192.168.2.11 | k8s-master-01 | 2C & 2G | master |
| 192.168.2.12 | k8s-master-02 | 2C & 2G | master |
| 192.168.2.13 | k8s-master-03 | 2C & 2G | master |
| 192.168.2.21 | k8s-node-01 | 2c & 4G | node |
| 192.168.2.22 | k8s-node-02 | 2c & 4G | node |
2、各个节点端口占用
- Master 节点
| 规则 | 方向 | 端口范围 | 作用 | 使用者 |
|---|---|---|---|---|
| TCP | Inbound | 6443* | Kubernetes API | server All |
| TCP | Inbound | 2379-2380 | etcd server | client API kube-apiserver, etcd |
| TCP | Inbound | 10250 | Kubelet API | Self, Control plane |
| TCP | Inbound | 10251 | kube-scheduler | Self |
| TCP | Inbound | 10252 | kube-controller-manager | Sel |
- node 节点
| 规则 | 方向 | 端口范围 | 作用 | 使用者 |
|---|---|---|---|---|
| TCP | Inbound | 10250 | Kubelet API | Self, Control plane |
| TCP | Inbound | 30000-32767 | NodePort Services** | All |
3、基础环境设置
Kubernetes 需要一定的环境来保证正常运行,如各个节点时间同步,主机名称解析,关闭防火墙等等。
主机名称解析
分布式系统环境中的多主机通信通常基于主机名称进行,这在 IP 地址存在变化的可能 性时为主机提供了固定的访问人口,因此一般需要有专用的 DNS 服务负责解决各节点主机 不过,考虑到此处部署的是测试集群,因此为了降低系复杂度,这里将基于 hosts 的文件进行主机名称解析。
修改hosts
分别进入不同服务器,进入 /etc/hosts 进行编辑
vim /etc/hosts
加入下面内容:
192.168.2.10 master.k8s.io k8s-vip 192.168.2.11 master01.k8s.io k8s-master-01 192.168.2.12 master02.k8s.io k8s-master-02 192.168.2.13 master03.k8s.io k8s-master-03 192.168.2.21 node01.k8s.io k8s-node-01 192.168.2.22 node02.k8s.io k8s-node-02
修改hostname
分别进入不同的服务器修改 hostname 名称
# 修改 192.168.2.11 服务器 hostnamectl set-hostname k8s-master-01 # 修改 192.168.2.12 服务器 hostnamectl set-hostname k8s-master-02 # 修改 192.168.2.13 服务器 hostnamectl set-hostname k8s-master-03 # 修改 192.168.2.21 服务器 hostnamectl set-hostname k8s-node-01 # 修改 192.168.2.22 服务器 hostnamectl set-hostname k8s-node-02
主机时间同步
将各个服务器的时间同步,并设置开机启动同步时间服务
systemctl start chronyd.service
systemctl enable chronyd.service
关闭防火墙服务
停止并禁用防火墙
systemctl stop firewalld
systemctl disable firewalld
关闭并禁用SELinux
# 若当前启用了 SELinux 则需要临时设置其当前状态为 permissivesetenforce 0
# 编辑/etc/sysconfig selinux 文件,以彻底禁用 SELinuxsed -i 's/^SELINUX=enforcing$/SELINUX=disabled/' /etc/selinux/config
# 查看selinux状态getenforce
如果为permissive,则执行reboot重新启动即可
禁用 Swap 设备
kubeadm 默认会预先检当前主机是否禁用了 Swap 设备,并在未用时强制止部署 过程因此,在主机内存资惊充裕的条件下,需要禁用所有的 Swap 设备
# 关闭当前已启用的所有 Swap 设备swapoff -a && sysctl -w vm.swappiness=0
# 编辑 fstab 配置文件,注释掉标识为 Swap 设备的所有行
vi /etc/fstab
# /etc/fstab # Created by anaconda on Wed Mar 6 00:53:57 2019 # # Accessible filesystems, by reference, are maintained under '/dev/disk' # See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info # /dev/mapper/centos-root / ext4 defaults 1 1 UUID=363884d8-5454-4886-bdbb-d5ebcd884408 /boot ext4 defaults 1 2 ##/dev/mapper/centos-swap swap swap defaults 0 0
设置系统参数
设置允许路由转发,不对bridge的数据进行处理
创建 /etc/sysctl.d/k8s.conf 文件
vim /etc/sysctl.d/k8s.conf
加入下面内容:
net.ipv4.ip_forward = 1 net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1
挂载br_netfilter
modprobe br_netfilter
生效配置文件
sysctl -p /etc/sysctl.d/k8s.conf
sysctl命令:用于运行时配置内核参数
查看是否生成相关文件
ls /proc/sys/net/bridge
资源配置文件
/etc/security/limits.conf 是 Linux 资源使用配置文件,用来限制用户对系统资源的使用
echo "* soft nofile 65536" >> /etc/security/limits.conf echo "* hard nofile 65536" >> /etc/security/limits.conf echo "* soft nproc 65536" >> /etc/security/limits.conf echo "* hard nproc 65536" >> /etc/security/limits.conf echo "* soft memlock unlimited" >> /etc/security/limits.conf echo "* hard memlock unlimited" >> /etc/security/limits.conf
安装依赖包以及相关工具
yum install -y epel-release yum install -y yum-utils device-mapper-persistent-data lvm2 net-tools conntrack-tools wget vim ntpdate libseccomp libtool-ltdl
三、安装Keepalived
- keepalived介绍: 是集群管理中保证集群高可用的一个服务软件,其功能类似于heartbeat,用来防止单点故障
- Keepalived作用: 为haproxy提供vip(192.168.2.10)在三个haproxy实例之间提供主备,降低当其中一个haproxy失效的时对服务的影响。
1、yum安装Keepalived
# 安装keepalived yum install -y keepalived
2、配置Keepalived
cat <<EOF > /etc/keepalived/keepalived.conf ! Configuration File for keepalived # 主要是配置故障发生时的通知对象以及机器标识。 global_defs { # 标识本节点的字条串,通常为 hostname,但不一定非得是 hostname。故障发生时,邮件通知会用到。 router_id LVS_k8s } # 用来做健康检查的,当时检查失败时会将 vrrp_instance 的 priority 减少相应的值。 vrrp_script check_haproxy { script "killall -0 haproxy" #根据进程名称检测进程是否存活 interval 3 weight -2 fall 10 rise 2 } # rp_instance用来定义对外提供服务的 VIP 区域及其相关属性。 vrrp_instance VI_1 { state MASTER #当前节点为MASTER,其他两个节点设置为BACKUP interface ens33 #改为自己的网卡 virtual_router_id 51 priority 250 advert_int 1 authentication { auth_type PASS auth_pass 35f18af7190d51c9f7f78f37300a0cbd } virtual_ipaddress { 192.168.2.10 #虚拟ip,即VIP } track_script { check_haproxy } } EOF
当前节点的配置中 state 配置为 MASTER,其它两个节点设置为 BACKUP
配置说明:
- virtual_ipaddress: vip
- track_script: 执行上面定义好的检测的script
- interface: 节点固有IP(非VIP)的网卡,用来发VRRP包。
- virtual_router_id: 取值在0-255之间,用来区分多个instance的VRRP组播
- advert_int: 发VRRP包的时间间隔,即多久进行一次master选举(可以认为是健康查检时间间隔)。
- authentication: 认证区域,认证类型有PASS和HA(IPSEC),推荐使用PASS(密码只识别前8位)。
- state: 可以是MASTER或BACKUP,不过当其他节点keepalived启动时会将priority比较大的节点选举为MASTER,因此该项其实没有实质用途。
- priority: 用来选举master的,要成为master,那么这个选项的值最好高于其他机器50个点,该项取值范围是1-255(在此范围之外会被识别成默认值100)。
3、启动Keepalived
# 设置开机启动
systemctl enable keepalived
# 启动keepalived
systemctl start keepalived
# 查看启动状态
systemctl status keepalived
4、查看网络状态
kepplived 配置中 state 为 MASTER 的节点启动后,查看网络状态,可以看到虚拟IP已经加入到绑定的网卡中
[root@k8s-master-01 ~]#ip address show ens33
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:50:56:84:1e:c3 brd ff:ff:ff:ff:ff:ff
inet 192.168.2.11/24 brd 192.168.15.255 scope global noprefixroute ens160
valid_lft forever preferred_lft forever
inet 192.168.2.10/24 scope global secondary ens33
valid_lft forever preferred_lft forever
inet6 fe80::250:56ff:fe84:1ec3/64 scope link
valid_lft forever preferred_lft forever

当关掉当前节点的keeplived服务后将进行虚拟IP转移,将会推选state 为 BACKUP 的节点的某一节点为新的MASTER,可以在那台节点上查看网卡,将会查看到虚拟IP
四、安装haproxy
此处的haproxy为apiserver提供反向代理,haproxy将所有请求轮询转发到每个master节点上。相对于仅仅使用keepalived主备模式仅单个master节点承载流量,这种方式更加合理、健壮。
1、yum安装haproxy
yum install -y haproxy
2、配置haproxy
cat > /etc/haproxy/haproxy.cfg << EOF #--------------------------------------------------------------------- # Global settings #--------------------------------------------------------------------- global # to have these messages end up in /var/log/haproxy.log you will # need to: # 1) configure syslog to accept network log events. This is done # by adding the '-r' option to the SYSLOGD_OPTIONS in # /etc/sysconfig/syslog # 2) configure local2 events to go to the /var/log/haproxy.log # file. A line like the following can be added to # /etc/sysconfig/syslog # # local2.* /var/log/haproxy.log # log 127.0.0.1 local2 chroot /var/lib/haproxy pidfile /var/run/haproxy.pid maxconn 4000 user haproxy group haproxy daemon # turn on stats unix socket stats socket /var/lib/haproxy/stats #--------------------------------------------------------------------- # common defaults that all the 'listen' and 'backend' sections will # use if not designated in their block #--------------------------------------------------------------------- defaults mode http log global option httplog option dontlognull option http-server-close option forwardfor except 127.0.0.0/8 option redispatch retries 3 timeout http-request 10s timeout queue 1m timeout connect 10s timeout client 1m timeout server 1m timeout http-keep-alive 10s timeout check 10s maxconn 3000 #--------------------------------------------------------------------- # kubernetes apiserver frontend which proxys to the backends #--------------------------------------------------------------------- frontend kubernetes-apiserver mode tcp bind *:16443 option tcplog default_backend kubernetes-apiserver #--------------------------------------------------------------------- # round robin balancing between the various backends #--------------------------------------------------------------------- backend kubernetes-apiserver mode tcp balance roundrobin server master01.k8s.io 192.168.2.11:6443 check server master02.k8s.io 192.168.2.12:6443 check server master03.k8s.io 192.168.2.13:6443 check #--------------------------------------------------------------------- # collection haproxy statistics message #--------------------------------------------------------------------- listen stats bind *:1080 stats auth admin:awesomePassword stats refresh 5s stats realm HAProxy Statistics stats uri /admin?stats EOF
haproxy配置在其他master节点上(192.168.2.12和192.168.2.13)相同
3、启动并检测haproxy
# 设置开机启动
systemctl enable haproxy
# 开启haproxy
systemctl start haproxy
# 查看启动状态
systemctl status haproxy
4、检测haproxy端口
ss -lnt | grep -E "16443|1080"
显示:

五、安装Docker (所有节点)
1、移除之前安装过的Docker
sudo yum remove docker docker-client docker-client-latest docker-common docker-latest docker-latest-logrotate docker-logrotate docker-selinux docker-engine-selinux docker-ce-cli docker-engine
查看还有没有存在的docker组件
rpm -qa|grep docker
有则通过命令 yum -y remove XXX 来删除,比如:
yum remove docker-ce-cli
2、配置docker的yum源
下面两个镜像源选择其一即可,由于官方下载速度比较慢,推荐用阿里镜像源
- 阿里镜像源
sudo yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
- Docker官方镜像源
sudo yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
2、安装Docker:
显示docker-ce所有可安装版本:
yum list docker-ce --showduplicates | sort -r
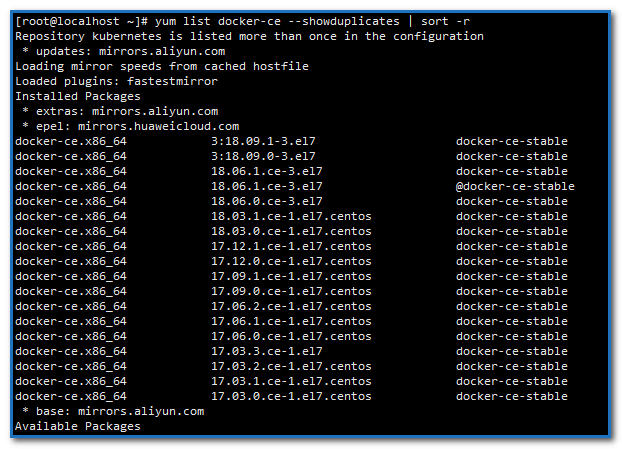
安装指定docker版本
sudo yum install docker-ce-18.06.1.ce-3.el7 -y
设置镜像存储目录
找到大点的挂载的目录进行存储
# 修改docker配置 vi /lib/systemd/system/docker.service 找到这行,王后面加上存储目录,例如这里是 --graph /apps/docker ExecStart=/usr/bin/docker --graph /apps/docker
启动docker并设置docker开机启动
systemctl enable docker
systemctl start docker
确认一下iptables
确认一下iptables filter表中FOWARD链的默认策略(pllicy)为ACCEPT。
iptables -nvL
显示:
Chain FORWARD (policy ACCEPT 0 packets, 0 bytes) pkts bytes target prot opt in out source destination 0 0 DOCKER-USER all -- * * 0.0.0.0/0 0.0.0.0/0 0 0 DOCKER-ISOLATION-STAGE-1 all -- * * 0.0.0.0/0 0.0.0.0/0 0 0 ACCEPT all -- * docker0 0.0.0.0/0 0.0.0.0/0 ctstate RELATED,ESTABLISHED 0 0 DOCKER all -- * docker0 0.0.0.0/0 0.0.0.0/0 0 0 ACCEPT all -- docker0 !docker0 0.0.0.0/0 0.0.0.0/0 0 0 ACCEPT all -- docker0 docker0 0.0.0.0/0 0.0.0.0/0
Docker从1.13版本开始调整了默认的防火墙规则,禁用了iptables filter表中FOWARD链,这样会引起Kubernetes集群中跨Node的Pod无法通信。但这里通过安装docker 1806,发现默认策略又改回了ACCEPT,这个不知道是从哪个版本改回的,因为我们线上版本使用的1706还是需要手动调整这个策略的。
六、安装kubeadm、kubelet
1、配置可用的国内yum源用于安装:
cat <<EOF > /etc/yum.repos.d/kubernetes.repo [kubernetes] name=Kubernetes baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/ enabled=1 gpgcheck=0 repo_gpgcheck=0 gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg EOF
2、安装kubelet
-
需要在每台机器上都安装以下的软件包:
- kubeadm: 用来初始化集群的指令。
- kubelet: 在集群中的每个节点上用来启动 pod 和 container 等。
- kubectl: 用来与集群通信的命令行工具。
查看kubelet版本列表
yum list kubelet --showduplicates | sort -r
安装kubelet
yum install -y kubelet-1.13.4-0
启动kubelet并设置开机启动
systemctl enable kubelet
systemctl start kubelet
检查状态
检查状态,发现是failed状态,正常,kubelet会10秒重启一次,等初始化master节点后即可正常
systemctl status kubelet
3、安装kubeadm
负责初始化集群
查看kubeadm版本列表
yum list kubeadm --showduplicates | sort -r
安装kubeadm
yum install -y kubeadm-1.13.4-0
安装 kubeadm 时候会默认安装 kubectl ,所以不需要单独安装kubectl
4、重启服务器
为了防止发生某些未知错误,这里我们重启下服务器,方便进行后续操作
reboot
七、初始化第一个kubernetes master节点
因为需要绑定虚拟IP,所以需要首先先查看虚拟IP启动这几台master机子哪台上
ip address show ens33
显示:
ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000 link/ether 00:0c:29:7e:65:b3 brd ff:ff:ff:ff:ff:ff inet 192.168.2.11/24 brd 192.168.2.255 scope global noprefixroute ens33 valid_lft forever preferred_lft forever inet 192.168.2.10/32 scope global ens33 valid_lft forever preferred_lft forever
可以看到 10虚拟ip 和 11的ip 在一台机子上,所以初始化kubernetes第一个master要在master01机子上进行安装
1、创建kubeadm配置的yaml文件
cat > kubeadm-config.yaml << EOF apiServer: certSANs: - k8s-master-01 - k8s-master-02 - k8s-master-03 - master.k8s.io - 192.168.2.10 - 192.168.2.11 - 192.168.2.12 - 192.168.2.13 - 127.0.0.1 extraArgs: authorization-mode: Node,RBAC timeoutForControlPlane: 4m0s apiVersion: kubeadm.k8s.io/v1beta1 certificatesDir: /etc/kubernetes/pki clusterName: kubernetes controlPlaneEndpoint: "master.k8s.io:16443" controllerManager: {} dns: type: CoreDNS etcd: local: dataDir: /var/lib/etcd imageRepository: registry.aliyuncs.com/google_containers kind: ClusterConfiguration kubernetesVersion: v1.13.4 networking: dnsDomain: cluster.local podSubnet: 10.20.0.0/16 serviceSubnet: 10.10.0.0/16 scheduler: {} EOF
以下两个地方设置: - certSANs: 虚拟ip地址(为了安全起见,把所有集群地址都加上) - controlPlaneEndpoint: 虚拟IP:监控端口号
配置说明:
- imageRepository: registry.aliyuncs.com/google_containers (使用阿里云镜像仓库)
- podSubnet: 10.20.0.0/16 (pod地址池)
- serviceSubnet: 10.10.0.0/16
#service地址池
2、初始化第一个master节点
kubeadm init --config kubeadm-config.yaml
日志:
Your Kubernetes master has initialized successfully! To start using your cluster, you need to run the following as a regular user: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/ You can now join any number of machines by running the following on each node as root: kubeadm join master.k8s.io:16443 --token dm3cw1.kw4hq84ie1376hji --discovery-token-ca-cert-hash sha256:f079b624773145ba714b56e177f52143f90f75a1dcebabda6538a49e224d4009
在此处看日志可以知道,通过
kubeadm join master.k8s.io:16443 --token dm3cw1.kw4hq84ie1376hji --discovery-token-ca-cert-hash sha256:f079b624773145ba714b56e177f52143f90f75a1dcebabda6538a49e224d4009
来让节点加入集群
3、配置kubectl环境变量
配置环境变量
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config
4、查看组件状态
kubectl get cs
显示:
NAME STATUS MESSAGE ERROR controller-manager Healthy ok scheduler Healthy ok etcd-0 Healthy {"health": "true"}
查看pod状态
kubectl get pods --namespace=kube-system
显示:

可以看到coredns没有启动,这是由于还没有配置网络插件,接下来配置下后再重新查看启动状态
八、安装网络插件
1、配置flannel插件的yaml文件
cat > kube-flannel.yaml << EOF --- kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1beta1 metadata: name: flannel rules: - apiGroups: - "" resources: - pods verbs: - get - apiGroups: - "" resources: - nodes verbs: - list - watch - apiGroups: - "" resources: - nodes/status verbs: - patch --- kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1beta1 metadata: name: flannel roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: flannel subjects: - kind: ServiceAccount name: flannel namespace: kube-system --- apiVersion: v1 kind: ServiceAccount metadata: name: flannel namespace: kube-system --- kind: ConfigMap apiVersion: v1 metadata: name: kube-flannel-cfg namespace: kube-system labels: tier: node app: flannel data: cni-conf.json: | { "name": "cbr0", "plugins": [ { "type": "flannel", "delegate": { "hairpinMode": true, "isDefaultGateway": true } }, { "type": "portmap", "capabilities": { "portMappings": true } } ] } net-conf.json: | { "Network": "10.20.0.0/16", "Backend": { "Type": "vxlan" } } --- apiVersion: extensions/v1beta1 kind: DaemonSet metadata: name: kube-flannel-ds-amd64 namespace: kube-system labels: tier: node app: flannel spec: template: metadata: labels: tier: node app: flannel spec: hostNetwork: true nodeSelector: beta.kubernetes.io/arch: amd64 tolerations: - operator: Exists effect: NoSchedule serviceAccountName: flannel initContainers: - name: install-cni image: registry.cn-shenzhen.aliyuncs.com/cp_m/flannel:v0.10.0-amd64 command: - cp args: - -f - /etc/kube-flannel/cni-conf.json - /etc/cni/net.d/10-flannel.conflist volumeMounts: - name: cni mountPath: /etc/cni/net.d - name: flannel-cfg mountPath: /etc/kube-flannel/ containers: - name: kube-flannel image: registry.cn-shenzhen.aliyuncs.com/cp_m/flannel:v0.10.0-amd64 command: - /opt/bin/flanneld args: - --ip-masq - --kube-subnet-mgr resources: requests: cpu: "100m" memory: "50Mi" limits: cpu: "100m" memory: "50Mi" securityContext: privileged: true env: - name: POD_NAME valueFrom: fieldRef: fieldPath: metadata.name - name: POD_NAMESPACE valueFrom: fieldRef: fieldPath: metadata.namespace volumeMounts: - name: run mountPath: /run - name: flannel-cfg mountPath: /etc/kube-flannel/ volumes: - name: run hostPath: path: /run - name: cni hostPath: path: /etc/cni/net.d - name: flannel-cfg configMap: name: kube-flannel-cfg EOF
“Network”: “10.20.0.0/16”要和kubeadm-config.yaml配置文件中podSubnet: 10.20.0.0/16相同
2、创建flanner相关role和pod
kubectl apply -f kube-flannel.yaml
等待一会时间,再次查看各个pods的状态
kubectl get pods --namespace=kube-system
显示:

可以看到coredns已经启动
九、加入集群
1、Master加入集群构成高可用
复制秘钥到各个节点
在master01 服务器上执行下面命令,将kubernetes相关文件复制到 master02、master03
如果其他节点为初始化第一个master节点,则将该节点的配置文件复制到其余两个主节点,例如master03为第一个master节点,则将它的k8s配置复制到master02和master01。
- 复制文件到 master02
ssh root@master02.k8s.io mkdir -p /etc/kubernetes/pki/etcd scp /etc/kubernetes/admin.conf root@master02.k8s.io:/etc/kubernetes scp /etc/kubernetes/pki/{ca.*,sa.*,front-proxy-ca.*} root@master02.k8s.io:/etc/kubernetes/pki scp /etc/kubernetes/pki/etcd/ca.* root@master02.k8s.io:/etc/kubernetes/pki/etcd
- 复制文件到 master03
ssh root@master03.k8s.io mkdir -p /etc/kubernetes/pki/etcd scp /etc/kubernetes/admin.conf root@master03.k8s.io:/etc/kubernetes scp /etc/kubernetes/pki/{ca.*,sa.*,front-proxy-ca.*} root@master03.k8s.io:/etc/kubernetes/pki scp /etc/kubernetes/pki/etcd/ca.* root@master03.k8s.io:/etc/kubernetes/pki/etcd
- master节点加入集群
master02 和 master03 服务器上都执行加入集群操作
kubeadm join master.k8s.io:16443 --token dm3cw1.kw4hq84ie1376hji --discovery-token-ca-cert-hash sha256:f079b624773145ba714b56e177f52143f90f75a1dcebabda6538a49e224d4009 --experimental-control-plane
如果加入失败想重新尝试,请输入 kubeadm reset 命令清除之前的设置,重新执行从“复制秘钥”和“加入集群”这两步
显示安装过程:
...... This node has joined the cluster and a new control plane instance was created: * Certificate signing request was sent to apiserver and approval was received. * The Kubelet was informed of the new secure connection details. * Master label and taint were applied to the new node. * The Kubernetes control plane instances scaled up. * A new etcd member was added to the local/stacked etcd cluster. To start administering your cluster from this node, you need to run the following as a regular user: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config Run 'kubectl get nodes' to see this node join the cluster.
- 配置kubectl环境变量
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config
2、node节点加入集群
除了让master节点加入集群组成高可用外,slave节点也要加入集群中。
这里将k8s-node-01、k8s-node-02加入集群,进行工作
输入初始化k8s master时候提示的加入命令,如下:
kubeadm join master.k8s.io:16443 --token dm3cw1.kw4hq84ie1376hji --discovery-token-ca-cert-hash sha256:f079b624773145ba714b56e177f52143f90f75a1dcebabda6538a49e224d4009
3、如果忘记加入集群的token和sha256 (如正常则跳过)
- 显示获取token列表
kubeadm token list
默认情况下 Token 过期是时间是24小时,如果 Token 过期以后,可以输入以下命令,生成新的 Token
kubeadm token create
- 获取ca证书sha256编码hash值
openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | openssl rsa -pubin -outform der 2>/dev/null | openssl dgst -sha256 -hex | sed 's/^.* //'
- 拼接命令
kubeadm join master.k8s.io:16443 --token 882ik4.9ib2kb0eftvuhb58 --discovery-token-ca-cert-hash sha256:0b1a836894d930c8558b350feeac8210c85c9d35b6d91fde202b870f3244016a
如果是master加入,请在最后面加上 –experimental-control-plane 这个参数
4、查看各个节点加入集群情况
kubectl get nodes -o wide 显示: NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME k8s-master-01 Ready master 12m v1.13.4 192.168.2.11 <none> CentOS Linux 7 (Core) 3.10.0-957.1.3.el7.x86_64 docker://18.6.1 k8s-master-02 Ready master 10m v1.13.4 192.168.2.12 <none> CentOS Linux 7 (Core) 3.10.0-957.1.3.el7.x86_64 docker://18.6.1 k8s-master-03 Ready master 38m v1.13.4 192.168.2.13 <none> CentOS Linux 7 (Core) 3.10.0-957.1.3.el7.x86_64 docker://18.6.1 k8s-node-01 Ready <none> 68s v1.13.4 192.168.2.21 <none> CentOS Linux 7 (Core) 3.10.0-957.1.3.el7.x86_64 docker://18.6.1 k8s-node-02 Ready <none> 61s v1.13.4 192.168.2.22 <none> CentOS Linux 7 (Core) 3.10.0-957.1.3.el7.x86_64 docker://18.6.1
十、从集群中删除 Node
- Master节点:
kubectl drain <node name> --delete-local-data --force --ignore-daemonsets
kubectl delete node <node name>
- slave节点
kubeadm reset
十一、配置dashboard
这个在一个服务器上部署,其他服务器会复制这个部署的pod,所以这里在master01服务器上部署 dashboard
1、创建 dashboard.yaml 并启动
# ------------------- Dashboard Secret ------------------- # apiVersion: v1 kind: Secret metadata: labels: k8s-app: kubernetes-dashboard name: kubernetes-dashboard-certs namespace: kube-system type: Opaque --- # ------------------- Dashboard Service Account ------------------- # apiVersion: v1 kind: ServiceAccount metadata: labels: k8s-app: kubernetes-dashboard name: kubernetes-dashboard namespace: kube-system --- # ------------------- Dashboard Role & Role Binding ------------------- # kind: Role apiVersion: rbac.authorization.k8s.io/v1 metadata: name: kubernetes-dashboard-minimal namespace: kube-system rules: # Allow Dashboard to create 'kubernetes-dashboard-key-holder' secret. - apiGroups: [""] resources: ["secrets"] verbs: ["create"] # Allow Dashboard to create 'kubernetes-dashboard-settings' config map. - apiGroups: [""] resources: ["configmaps"] verbs: ["create"] # Allow Dashboard to get, update and delete Dashboard exclusive secrets. - apiGroups: [""] resources: ["secrets"] resourceNames: ["kubernetes-dashboard-key-holder", "kubernetes-dashboard-certs"] verbs: ["get", "update", "delete"] # Allow Dashboard to get and update 'kubernetes-dashboard-settings' config map. - apiGroups: [""] resources: ["configmaps"] resourceNames: ["kubernetes-dashboard-settings"] verbs: ["get", "update"] # Allow Dashboard to get metrics from heapster. - apiGroups: [""] resources: ["services"] resourceNames: ["heapster"] verbs: ["proxy"] - apiGroups: [""] resources: ["services/proxy"] resourceNames: ["heapster", "http:heapster:", "https:heapster:"] verbs: ["get"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: kubernetes-dashboard-minimal namespace: kube-system roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: kubernetes-dashboard-minimal subjects: - kind: ServiceAccount name: kubernetes-dashboard namespace: kube-system --- # ------------------- Dashboard Deployment ------------------- # # 1.修改了镜像仓库位置,编辑成自己的镜像仓库 # 2.变更了镜像拉去策略imagePullPolicy: IfNotPresent kind: Deployment apiVersion: apps/v1 metadata: labels: k8s-app: kubernetes-dashboard name: kubernetes-dashboard namespace: kube-system spec: replicas: 1 revisionHistoryLimit: 10 selector: matchLabels: k8s-app: kubernetes-dashboard template: metadata: labels: k8s-app: kubernetes-dashboard spec: containers: - name: kubernetes-dashboard image: registry.cn-hangzhou.aliyuncs.com/google_containers/kubernetes-dashboard-amd64:v1.10.1 imagePullPolicy: IfNotPresent ports: - containerPort: 8443 protocol: TCP args: - --auto-generate-certificates # Uncomment the following line to manually specify Kubernetes API server Host # If not specified, Dashboard will attempt to auto discover the API server and connect # to it. Uncomment only if the default does not work. # - --apiserver-host=http://my-address:port volumeMounts: - name: kubernetes-dashboard-certs mountPath: /certs # Create on-disk volume to store exec logs - mountPath: /tmp name: tmp-volume livenessProbe: httpGet: scheme: HTTPS path: / port: 8443 initialDelaySeconds: 30 timeoutSeconds: 30 volumes: - name: kubernetes-dashboard-certs secret: secretName: kubernetes-dashboard-certs - name: tmp-volume emptyDir: {} serviceAccountName: kubernetes-dashboard # Comment the following tolerations if Dashboard must not be deployed on master tolerations: - key: node-role.kubernetes.io/master effect: NoSchedule --- # ------------------- Dashboard Service ------------------- # # 增加了nodePort,使得能够访问,改变默认的type类型ClusterIP,变为NodePort # 如果不配置的话默认只能集群内访问 kind: Service apiVersion: v1 metadata: labels: k8s-app: kubernetes-dashboard name: kubernetes-dashboard namespace: kube-system spec: type: NodePort ports: - port: 443 targetPort: 8443 nodePort: 30001 selector: k8s-app: kubernetes-dashboard
运行 dashboard
kubectl create -f kubernetes-dashboard.yaml
2、Dashboard 创建 ServiceAccount 并绑定 Admin 角色
kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1beta1 metadata: name: admin annotations: rbac.authorization.kubernetes.io/autoupdate: "true" roleRef: kind: ClusterRole name: cluster-admin apiGroup: rbac.authorization.k8s.io subjects: - kind: ServiceAccount name: admin namespace: kube-system --- apiVersion: v1 kind: ServiceAccount metadata: name: admin namespace: kube-system labels: kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile
运行dashboard的用户和角色绑定
kubectl create -f dashboard-user-role.yaml
获取登陆token
kubectl describe secret/$(kubectl get secret -n kube-system |grep admin|awk '{print $1}') -n kube-system
显示:
[root@k8s-master-01 local]# kubectl describe secret/$(kubectl get secret -nkube-system |grep admin|awk '{print $1}') -nkube-system Name: admin-token-2mfdz Namespace: kube-system Labels: <none> Annotations: kubernetes.io/service-account.name: admin kubernetes.io/service-account.uid: 74efd994-38d8-11e9-8740-000c299624e4 Type: kubernetes.io/service-account-token Data ==== ca.crt: 1025 bytes namespace: 11 bytes token: eyJhbGciOiJSUzI1NiIsImtpZCI6IiJ9.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlLXN5c3RlbSIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJhZG1pbi10b2tlbi1qdjd4ayIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50Lm5hbWUiOiJhZG1pbiIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50LnVpZCI6ImM4ZTMxYzk0LTQ2MWEtMTFlOS1iY2M5LTAwMGMyOTEzYzUxZCIsInN1YiI6InN5c3RlbTpzZXJ2aWNlYWNjb3VudDprdWJlLXN5c3RlbTphZG1pbiJ9.TNw1iFEsZmJsVG4cki8iLtEoiY1pjpnOYm8ZIFjctpBdTOw6kUMvv2b2B2BJ_5rFle31gqGAZBIRyYj9LPAs06qT5uVP_l9o7IyFX4HToBF3veiun4e71822eQRUsgqiPh5uSjKXEkf9yGq9ujiCdtzFxnp3Pnpeuge73syuwd7J6F0-dJAp3b48MLZ1JJwEo6CTCMhm9buysycUYTbT_mUDQMNrHVH0868CdN_H8azA4PdLLLrFfTiVgoGu4c3sG5rgh9kKFqZA6dzV0Kq10W5JJwJRM1808ybLHyV9jfKN8N2_lZ7ehE6PbPU0cV-PyP74iA-HrzFW1yVwSLPVYA
3、运行dashboard并登陆
输入地址:https://192.168.2.10:30001 进入 dashboard 界面
这里输入上面获取的 token 进入 dashboard
问题
1、Master不会参与负载工作
Master不会参与负载工作,如何让其参加,这里需要了解traint
查看traint
# 查看全部节点是否能被安排工作 kubectl describe nodes | grep -E '(Roles|Taints)'
删除traint
# 所有node都可以调度 kubectl taint nodes --all node-role.kubernetes.io/master- # 指定node可以调度 kubectl taint nodes k8s-master-01 node-role.kubernetes.io/master-
2、重新加入集群
有时候节点出现问题需要重新加入集群,加入前需要清除一些设置,不然可能出现某些错误,比如
network is not ready: [runtime network not ready: NetworkReady=false reason:NetworkPluginNotReady message:docker: network plugin is not ready: cni config uninitialized] Back-off restarting failed container
按下面步骤执行,再执行加入集群命令即可
#重置kubernetes服务,重置网络。删除网络配置,link kubeadm reset #重启kubelet systemctl stop kubelet #停止docker systemctl stop docker #重置cni rm -rf /var/lib/cni/ rm -rf /var/lib/kubelet/* rm -rf /etc/cni/ ifconfig cni0 down ifconfig flannel.1 down ifconfig docker0 down ip link delete cni0 ip link delete flannel.1 #重启docker systemctl start docker
再次加入集群
kubeadm join cluster.kube.com:16443 --token gaeyou.k2650x660c8eb98c --discovery-token-ca
参考:
http://www.mydlq.club/article/4/