AWS机器学习初探(1):Comprehend - 自然语言处理服务
这几个服务的功能和使用都很直接和简单,因此放在一篇文章中介绍。
1. 文本翻译服务 Translate
1.1 功能介绍
AWS Translate 服务是一种AWS 机器学习应用服务,它利用高级机器学习技术来进行文本翻译。它的使用非常简单,只需要提供输入文本,该服务就给出输出文本。
- 输入文本(Source text):待翻译的文本,必须是 UTF-8 格式。
- 输出文本(Output text):AWS Translate 服务输出的翻译好的文本,也是 UTF-8 格式。
AWS Translate 服务有两个组件:
- encoder:每次从输入文本中读取一个单词,然后根据其含义构造语义表达。
- decoder:利用encoder给出的语义表达,产生一个翻译词汇。
AWS Translate 利用 attention 机制来理解上下文,它帮助 decoder 聚焦在原文中最相关的部分,这有助于它翻译模糊的单词和短语。
Translate 目前只支持将多种语言翻译为英文,以及将英文翻译成多种目标语言。Translate 能自动检测输入文本是哪种语言,它是利用 Comprehend 来实现语言探测的。
来对比下AWS Translate 和 Google 翻译的结果:
这是一段川普的推特文本:
I am hearing so many great things about the Republican Party’s California Gubernatorial Candidate, John Cox. He is a very successful businessman who is tired of high Taxes & Crime. He will Make California Great Again & make you proud of your Great State again. Total Endorsement!
Google 翻译结果:
关于共和党加州州长候选人约翰考克斯,我听到了很多很棒的事情。 他是一个非常成功的商人,厌倦了高税收和犯罪。 他将使加利福尼亚再次伟大,让你再次为你的伟大国家感到骄傲。 总代言!
AWS Translate 翻译结果:
我听到很多关于共和党加州州长候选人约翰·考克斯的伟大事情。 他是一个非常成功的商人,厌倦了高税与犯罪。 他将再次使加州成为伟大的国家,让你再次为你的伟大国家感到骄傲。 完全赞同!
从结果看,AWS Translage的质量应该比Google 稍微好一些。
1.2 界面操作示例
以下示例将中文文本翻译为英文:
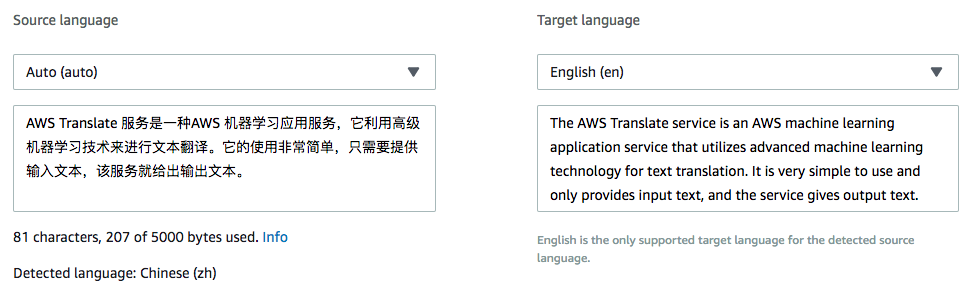
1.3 CLI 操作示例
aws translate translate-text --region us-east-1 --source-language-code "auto" --target-language-code "zh" --text "I am hearing so many great things about the Republican Party California Gubernatorial Candidate, John Cox. He is a very successful businessman who is tired of high Taxes & Crime. He will Make California Great Again & make you proud of your Great State again. Total Endorsement" { "TranslatedText": "我听到很多关于共和党加州州长候选人约翰·考克斯的伟大事情。 他是一个非常成功的商人,厌倦了高税与犯罪。 他将再次使加州成为伟大的国家,让你再次为你的伟大国家感到骄傲。 完全赞同", "SourceLanguageCode": "en", "TargetLanguageCode": "zh" }
1.4 API
Translate 服务只有一个API,就是 TranslateText。
请求语法:
{ "SourceLanguageCode": "string", "TargetLanguageCode": "string", "Text": "string" }
返回语法:
{ "SourceLanguageCode": "string", "TargetLanguageCode": "string", "TranslatedText": "string" }
1.5 python 示例代码
代码:
import boto3 translate = boto3.client(service_name='translate', region_name='us-east-1', use_ssl=True) result = translate.translate_text(Text="Hello World", SourceLanguageCode="auto", TargetLanguageCode="zh") print('TranslatedText: ' + result.get('TranslatedText')) print('SourceLanguageCode: ' + result.get('SourceLanguageCode')) print('TargetLangaugeCode: ' + result.get('TargetLanguageCode'))
输出:
TranslatedText: 您好世界
SourceLanguageCode: en
TargetLangaugeCode: zh
2. 文本转语音Polly
2.1 功能介绍
所谓的文本转语音服务,就是把文本朗读出来。它的输入输出为:
- 输入文本:待被Polly转化为语音的文本。可以是纯文字(plain text),也可以是 SSML(Speech Syntessis Markup Language) 格式。SSML 格式可以进行更精细的控制,比如音量、语速、发音等。
- 输出的语言种类:Polly 支持多种语言,每种语音支持多种发声模式,比如女生声音和男性声音。
- 输出格式:Polly 支持输出多种格式的语音,比如 mp3格式,PCM 格式等。
几个特色功能:
- 支持发音字典(lexicon):通过发音字典可以自定义单词的发音。用户可以将发音字典上传到AWS 上,然后将其应用到 SynthesizeSpeech API 中。
- 支持异步语音合成:可以以异步方式为大文本合成语音。三步走:启动一个合成任务,获取任务的详情,从S3中获取合成结果。近实时API只支持3000个字符,而异步API可以支持最多20万个字符。
- 支持 SSML:详情可参考官方文档。
2.2 界面操作示例
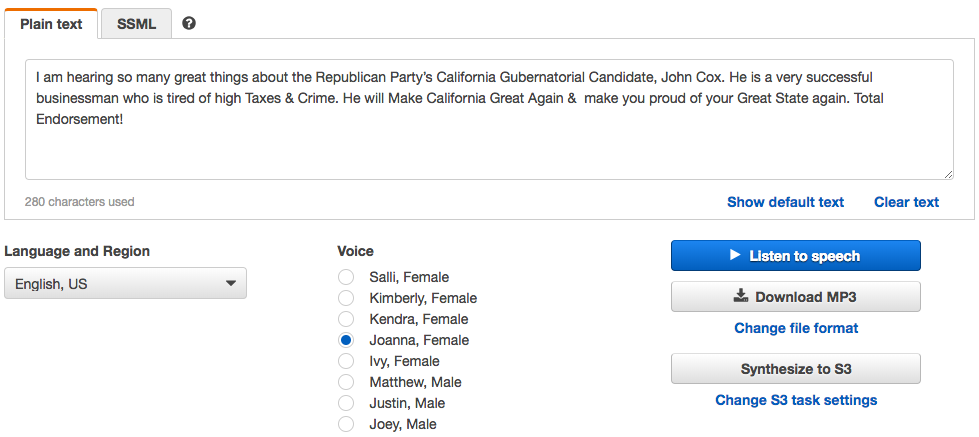
- Listen to speech:直接听语音
- Download MP3:可以将语音保存为 MP3 格式,并直接下载
- Syntesize to S3:将语音输出保存到 S3 中。
2.3 CLI 操作示例
SammydeMacBook-Air:~ Sammy$ aws polly synthesize-speech --output-format mp3 --voice-id Joanna --text 'Hello, my name is Joanna. I learned about the W3C on 10/3 of last year.' helloworld.mp3 { "ContentType": "audio/mpeg", "RequestCharacters": "71" } SammydeMacBook-Air:~ Sammy$ ls helloworld.mp3 helloworld.mp3
2.4 API
Polly 具有以下几个API:
• SynthesizeSpeech:合成语音
• ListLexicons:列表发音词典
• PutLexicon:创建发音词典
• GetLexicon:检索发音词典
• DeleteLexicon:删除发音词典
• DescribeVoices:获取声音列表
• GetSpeechSynthesisTask:获取语音生成任务
• ListSpeechSynthesisTasks:获取语音生成任务列表
• StartSpeechSynthesisTask:开始语音生成任务
2.5 python 示例代码
from boto3 import Session from contextlib import closing import os import sys import subprocess from tempfile import gettempdir session = Session(profile_name="default") polly = session.client("polly") try: text = "To the incredible people of the Great State of Wyoming: Go VOTE TODAY for Foster Friess - He will be a fantastic Governor! Strong on Crime, Borders & 2nd Amendment. Loves our Military & our Vets. He has my complete and total Endorsement!" response = polly.synthesize_speech(Text = text, OutputFormat="mp3", VoiceId="Joanna") except Exception as error: print(error) sys.exit(-1) if "AudioStream" in response: with closing(response["AudioStream"]) as stream: output = os.path.join(gettempdir(), "speech.mp3") try: with open(output, "wb") as file: file.write(stream.read()) except IOError as error: print(error) sys.exit(-1) else: print("Could not stream audio") sys.exit(-1) if sys.platform == "win32": os.startfile(output) else: opener = "open" if sys.platform == "darwin" else "xdg-open" subprocess.call([opener, output])
这段代码会将语音保存到 speech.mp3中,然后调用系统默认播放器进行播放。
3. 语音转文本服务Transcribe
3.1 功能介绍
AWS Transcribe 服务于利用机器学习来识别语音文件中的声音,然后将其转化为文本。目前支持英语和西班牙文语音。必须将语音文件保存在S3中,输出结果也会被保存在S3中。
- 输入声音文件,支持 flac、mp3、mp4 和 wav 文件格式。长度不能超过2小时。
- 指定语言。
几个特色功能:
- 发音者识别(speaker identification):Transcribe 能区别一个语音文件中的多个说话者。支持2到10个发音者。
- 支持多声道(channel identification): 如果声音文件中有多声道,那么
- 支持字典(vocabulary):比如不能识别的单词,特定领域不常用的单词
3.2 界面操作示例
创建一个job:
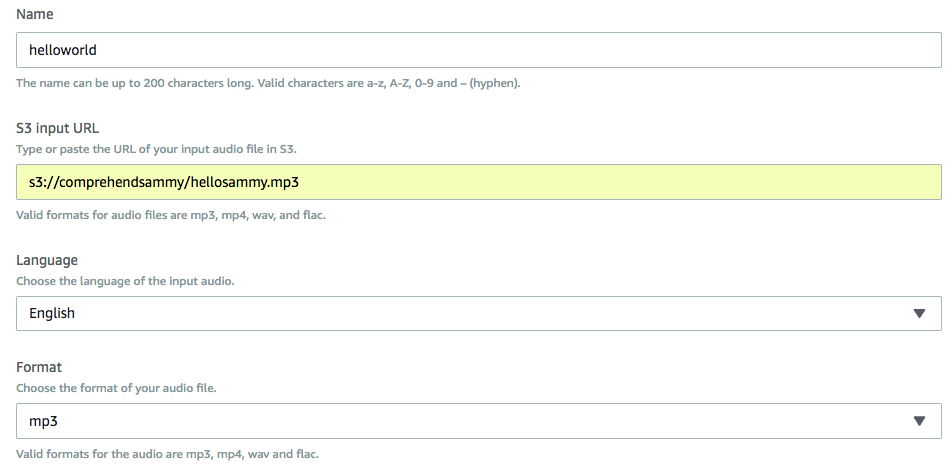
job列表:

结果:
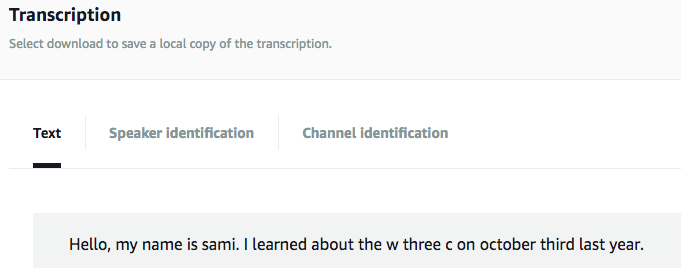
3.3 CLI 操作示例
(1)提交一个job
{ "TranscriptionJobName": "testTranscribe", "LanguageCode": "en-US", "MediaFormat": "mp3", "Media": { "MediaFileUri": "https://s3.dualstack.us-east-1.amazonaws.com/*********/hellosammy.mp3" } } aws transcribe start-transcription-job --region us-east-1 --cli-input-json file://testTranscribeJob.json
(2)获取job 列表
aws transcribe list-transcription-jobs --region us-east-1 --status IN_PROGRESS { "Status": "IN_PROGRESS", "TranscriptionJobSummaries": [ { "TranscriptionJobName": "testTranscribe", "CreationTime": 1535338023.662, "LanguageCode": "en-US", "TranscriptionJobStatus": "IN_PROGRESS", "OutputLocationType": "SERVICE_BUCKET" } ] }
(3)一旦 job 完成后,从其包含的TranscriptFileUri地址可以下载输出文本,部分内容如下:
{"jobName":"testTranscribe","accountId":"725348140609","results":{"transcripts":[{"transcript":"Hello, my name is sami. I learned about the w three c on october third last year."}],"items":[{"start_time":"0.0","end_time":"0.59","alternatives":[{"confidence":"0.9023","content":"Hello"}],"type":"pronunciation"},{"alternatives":[{"confidence":null,"content":","}],"type":"punctuation"},{"start_time":"0.7","end_time":"0.88","alternatives":
[{"confidence":"0.9867","content":"last"}],"type":"pronunciation"},{"start_time":"4.69","end_time":"5.07","alternatives":[{"confidence":"0.9867","content":"year"}],"type":"pronunciation"},{"alternatives":[{"confidence":null,"content":"."}],"type":"punctuation"}]},"status":"COMPLETED"}
3.4 API
- StartTranscriptionJob:开始一个转换任务
- ListTranscriptionJobs:获取任务列表
- GetTranscriptionJob:获取任务
- CreateVocabulary:创建字典
- DeleteVocabulary:删除字典
- GetVocabulary:获取字典
- ListVocabularies:获取字典列表
- UpdateVocabulary:上传字典
3.5 python 示例代码
import time import boto3 transcribe = boto3.client(('transcribe')) job_name = "testTranscribeJob100" job_uri = "https://s3.dualstack.us-east-1.amazonaws.com/*****/hellosammy.mp3" transcribe.start_transcription_job(TranscriptionJobName=job_name, Media={'MediaFileUri': job_uri}, MediaFormat='mp3', LanguageCode='en-US') while True: status = transcribe.get_transcription_job(TranscriptionJobName = job_name) if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', "FAILED"]: break print("Job not ready yet...") time.sleep(5) print(status)
参考文档:
- AWS Translate、Polly 和 Transcribe 开发者文档
欢迎大家关注我的个人公众号:
