transforms
上篇博文《Pytorch:Dataloader和Dataset以及搭建数据部分的步骤》提到transforms是pytorch数据模块的预处理部分。transforms来自torchvision,torchvision是pytorch的计算机视觉工具包。torchvision有以下几个主要的模块:
torchvision.transforms:常用的图像预处理方法
torchvision.datasets:常用数据集的datasets实现,MNIST,CIFAR-10,Imagenet等
torchvision.model:常用的模型预训练,Alexnet,VGG,Resnet,Googlenet等
torcvision.transforms提供了很多常用的图像预处理方法,不限以下的归类:
数据中心化、数据标准化
缩放、裁剪、旋转、翻转、填充、噪声添加
灰度变换、线性变换、仿射变换、亮度 饱和度 对比度变换
transforms模块机制
在上篇博文中提到,在数据处理的流程中,通常在设置好数据的路径以及计算好数据的均值方差后,构建dataset以及dataloader前,设立transforms的compose。compose就是将所需的transforms的各种变换有序地组合在一起。
下面就是一个一般的数据预处理,包括resize、totensor以及normalize。而训练数据中的randomcrop是数据增强的举例体现,后续会详细介绍,验证集(valid)不需要数据增强。
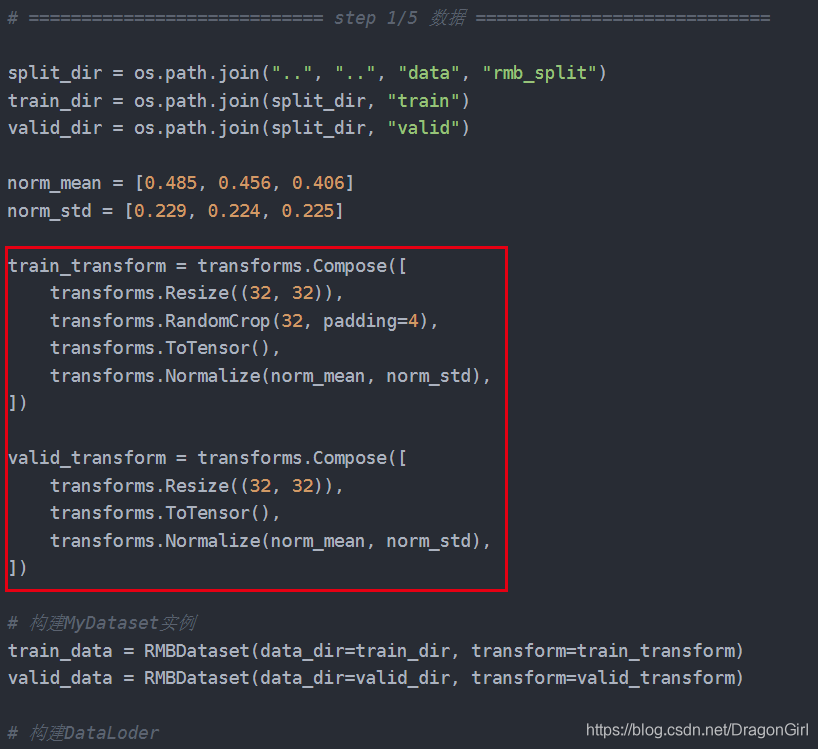
在上篇博文的底层代码步进流程中可以知晓,在自定义dataset中的__getitem__()函数中有检查是否执行transforms的判断,从这里再进入transforms.py的函数定义,会进入到call函数中,进行每个transforms方法的依次调用。这里的self便是compose体,t为compose中每个transforms具体的方法
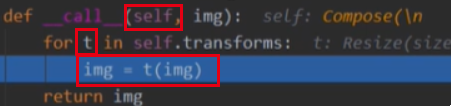
依次循环完后就在getitem做返回到fetch函数整理成一个batch的data,继而退出dataloaderiter,完成一次enumerate,得到一个batchsize的数据,进入训练
结合上述流程,考虑transforms重新整理成完整的流程图,可以得到:
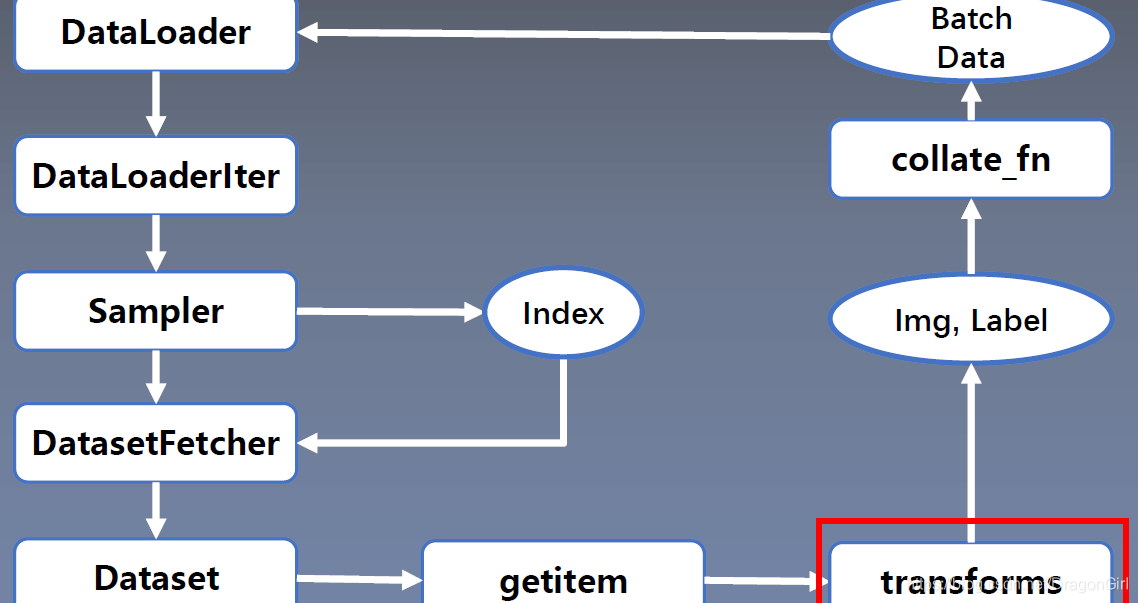
另外,简要说明下transform中几乎必用的标准化函数
transforms.normalize
功能:逐channel地对图像进行标准化
公式:output=(input - mean) / std
mean:各通道的均值
std:各通道的标准差
inplace:是否执行原地操作,默认False
tips:
为什么要对数据进行标准化? 标准化(即减均值除以标准差)可以大大加快模型的收敛,使得新的数据大体分布在0均值左右,且波动相对较小,使得训练的模型参数也相对简单和易学习。如果没有标准化操作,可想而知,模型习得的参数会比较大,而且损失函数也比较大,更新优化也相对缓慢与粗糙,对尤其是成千上万参数的模型训练来说是不可靠的。
下篇博文《Pytorch:transforms二十二种数据预处理方法及自定义transforms方法》会详细介绍transforms中用于数据增强的各种函数以及如何实现自定义的transforms方法