1.安装ssh免密登录
命令:ssh-keygen
overwrite(覆盖写入)输入y
一路回车
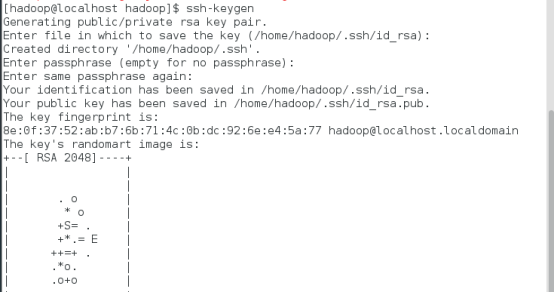
将生成的密钥发送到本机地址
ssh-copy-id localhost
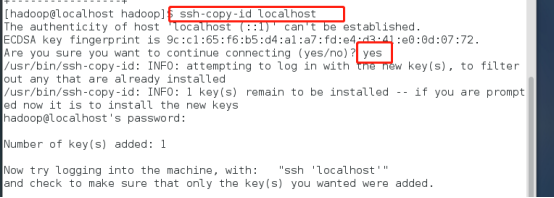
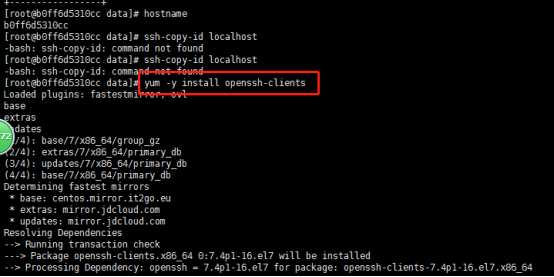
(若报错命令无法找到则需要安装openssh-clients)
yum –y install openssh-clients
测试免密设置是否成功
ssh localhost

2.卸载已有java
确定JDK版本
rpm –qa | grep jdk
rpm –qa | grep gcj
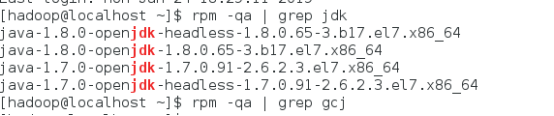
切换到root用户,根据结果卸载java

yum -y remove java-1.8.0-openjdk-headless.x86_64
yum -y remove java-1.7.0-openjdk-headless.x86_64
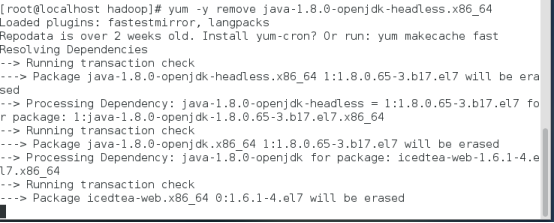
卸载后输入java –version查看

3.安装java
切换回hadoop用户,命令:su hadoop
查看下当前目标文件,命令:ls
新建一个app文件夹,命令:mkdir app

将桌面的hadoop文件夹中的java及hadoop安装包移动到app文件夹中
命令:
mv /home/hadoop/Desktop/hadoop/jdk-8u141-linux-x64.gz /home/hadoop/app
mv /home/hadoop/Desktop/hadoop/hadoop-2.7.0.tar.gz /home/hadoop/app
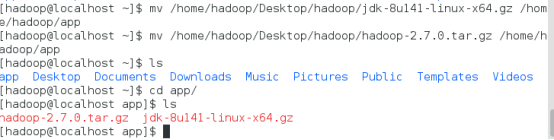
解压java程序包,命令:tar –zxvf jdk-7u79-linux-x64.tar.gz

创建软连接
ln –s jdk1.8.0_141 jdk

配置jdk环境变量
切换到root用户
再输入vi /etc/profile
输入
export JAVA_HOME=/home/hadoop/app/jdk1.8.0_141
export JAVA_JRE=JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JAVA_JRE/lib
export PATH=$PATH:$JAVA_HOME/bin

保存退出,并使/etc/profile文件生效
source /etc/profile

能查询jdk版本号,说明jdk安装成功
java -version

4.安装hadoop
切换回hadoop用户,解压缩hadoop-2.6.0.tar.gz安装包

创建软连接,命令:ln -s hadoop-2.7.0 hadoop

验证单机模式的Hadoop是否安装成功,命令:
hadoop/bin/hadoop version
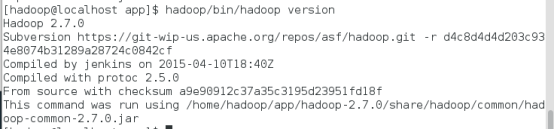
此时可以查看到Hadoop安装版本为Hadoop2.7.0,说明单机版安装成功。
查看Hadoop目录结构
[atguigu@hadoop101 hadoop-2.7.2]$ ll
总用量 52
drwxr-xr-x. 2 atguigu atguigu 4096 5月 22 2017 bin
drwxr-xr-x. 3 atguigu atguigu 4096 5月 22 2017 etc
drwxr-xr-x. 2 atguigu atguigu 4096 5月 22 2017 include
drwxr-xr-x. 3 atguigu atguigu 4096 5月 22 2017 lib
drwxr-xr-x. 2 atguigu atguigu 4096 5月 22 2017 libexec
-rw-r--r--. 1 atguigu atguigu 15429 5月 22 2017 LICENSE.txt
-rw-r--r--. 1 atguigu atguigu 101 5月 22 2017 NOTICE.txt
-rw-r--r--. 1 atguigu atguigu 1366 5月 22 2017 README.txt
drwxr-xr-x. 2 atguigu atguigu 4096 5月 22 2017 sbin
drwxr-xr-x. 4 atguigu atguigu 4096 5月 22 2017 share
重要目录
(1)bin目录:存放对Hadoop相关服务(HDFS,YARN)进行操作的脚本
(2)etc目录:Hadoop的配置文件目录,存放Hadoop的配置文件
(3)lib目录:存放Hadoop的本地库(对数据进行压缩解压缩功能)
(4)sbin目录:存放启动或停止Hadoop相关服务的脚本
(5)share目录:存放Hadoop的依赖jar包、文档、和官方案例
5.配置伪分布式登录
进入hadoop/etc/hadoop目录,修改相关配置文件
cd etc/
cd hadoop/

修改core-site.xml配置文件
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>file:/data/tmp</value> </property> <property> <name>hadoop.proxyuser.hadoop.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.hadoop.groups</name> <value>*</value> </property> </configuration>
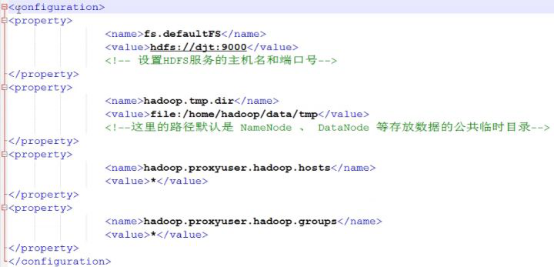
修改hdfs-site.xml配置文件
<configuration> <property> <name>dfs.namenode.name.dir</name> <value>/data/dfs/name</value> <final>true</final> </property> <property> <name>dfs.datanode.data.dir</name> <value>/data/dfs/data</value> <final>true</final> </property> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property> </configuration>

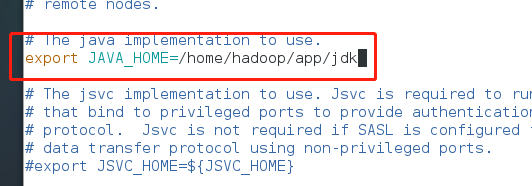
修改hadoop-env.sh配置文件
修改mapred-site.xml.template配置文件
<configuration> <property> <name>mapreduce.frameword.name</name> <value>yarn</value> </property> </configuration>
修改yarn-site.xml配置文件
<property> <name>yarn.nodemanager.aux-servies</name> <value>mapreduce_shuffle</value> </property> </configuration>
配置hadoop环境变量
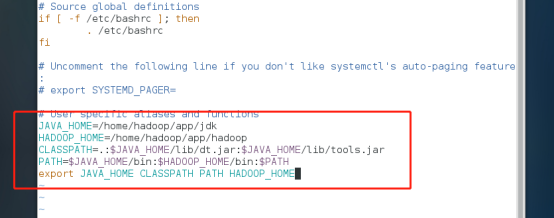
使修改生效,命令:sourec ~/.bashrc
创建hadoop相关数据目录
在hadoop相关配置文件中配置了多个数据目录,提前建立这些文件夹

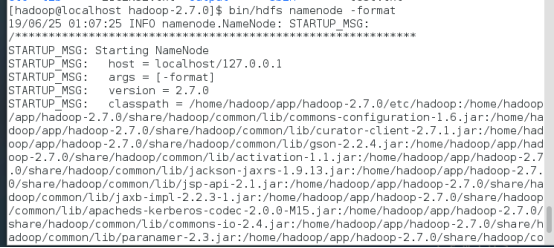
格式化namenode
在启动hadoop集群前需要格式化namenode。需要注意的是,第一次安装Hadoop集群的时候需要格式化Namenode,以后直接启动Hadoop集群即可,不需要重复格式化Namenode。
切回到hadoop目录,输入如下命令:
bin/hdfs namenode -format
启动hadoop伪分布式集群
sbin/start-all.sh

启动完毕输入jps查看
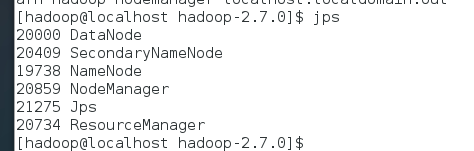
出现上面所有进程表示启动成功
通过网页访问
localhost:50070
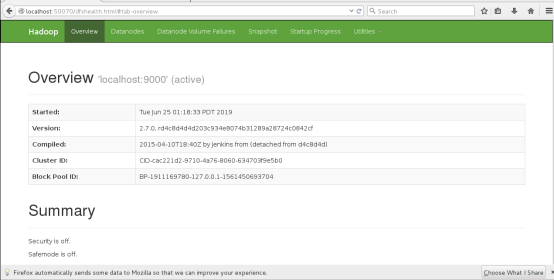
6.测试运行hadoop伪分布式集群
hadoop伪分布式集群搭建完成,通过命令查看hdfs根目录下没有任何文件
bin/hdfs dfs –ls /
将之前本地新建的test.txt文件上传至hdfs
bin/hdfs dfs –mkdir /data (在集群上新建一个数据文件夹)
bin/hdfs dfs –put test.txt /data(将本地的test文件上传到集群中的data文件夹)
运行wordcount程序计数
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.0.jar wordcount /data/test.txt /data/output
查看运行结果
bin/hdfs dfs –cat /data/output/*