为了规避多进程模型带来的问题
- 线程被称作轻量级进程,是进程的子运行单位
令人感到意外的是,linux不支持原生态的线程(thread),window,solaris都支持,linux把线程当进程一样对待,管理上略有区别,成为 lwp(light weight process)轻量级进程,线程的创建,撤销依赖glibc相关
库,各线程库对资源的耗用各不相同,linux可以切换线程库,满足不同需求!
一个进程地址空间内可以开启多个线程并发或线程并行,一个进程空间,大致可分为指令区(代码区),存放数据的(堆,栈),静态区等,堆区中会存放打开的文件
- 多线程比多进程究竟好在哪
解答这个问题,我们不妨设想这样一个应用场景:有5个请求访问同一网页资源,如果是多进程响应(开5个进程,每个进程响应一个请求)且不说内核空间切换进程带来的资源消耗,即使返回数据,那么同样的数据也会在进程空间
有5个备份。线程的好处在于,由于进程空间是共享的(打开的文件,传入的信号,占用的内存资源比进程有所下降),线程1拿到资源后,线程2可以直接读取数据,并通过网卡交互给互联网用户
如果没有多颗cpu,线程优势发挥不出来,多核CPU条件下,进程下的线程可以在多个cpu上并行执行,一个进程乃至一个线程可以有多个执行流,可以更好的分配资源。
值得注意的是一个进程不可能通过开启无数个线程响应所有请求:例如读,写操作不能共享,只能切换;cpu一直在运转,每秒都查询线程是否就绪 称之为忙等使用自旋锁spin lock,切换出线程谓之闲等,线程切换过快会带来线程抖动
- 多进程多线程组合使用
通过编程,隔离出一个CPU,然后绑定一个进程,在这个进程下开启多个线程,让线程在这个CPU下切换
- 一个线程(你没看错,是线程)处理多个请求
一个进程响应一个请求和一个线程响应一个请求的场景,其实请求完成的通知机制都可以用select机制,因为前文提到,linux环境下线程和进程并无实质性不同,线程被看做轻量级进程,如下图所示,每一个进程或线程
(请求)进来后,内核空间都会分配给一个文件描述符用来说明请求的执行情况(完成/未完成),那么内核每次通知时会遍历文件描述符,标记该文件描述符的状态,这种通知机制就是select模型
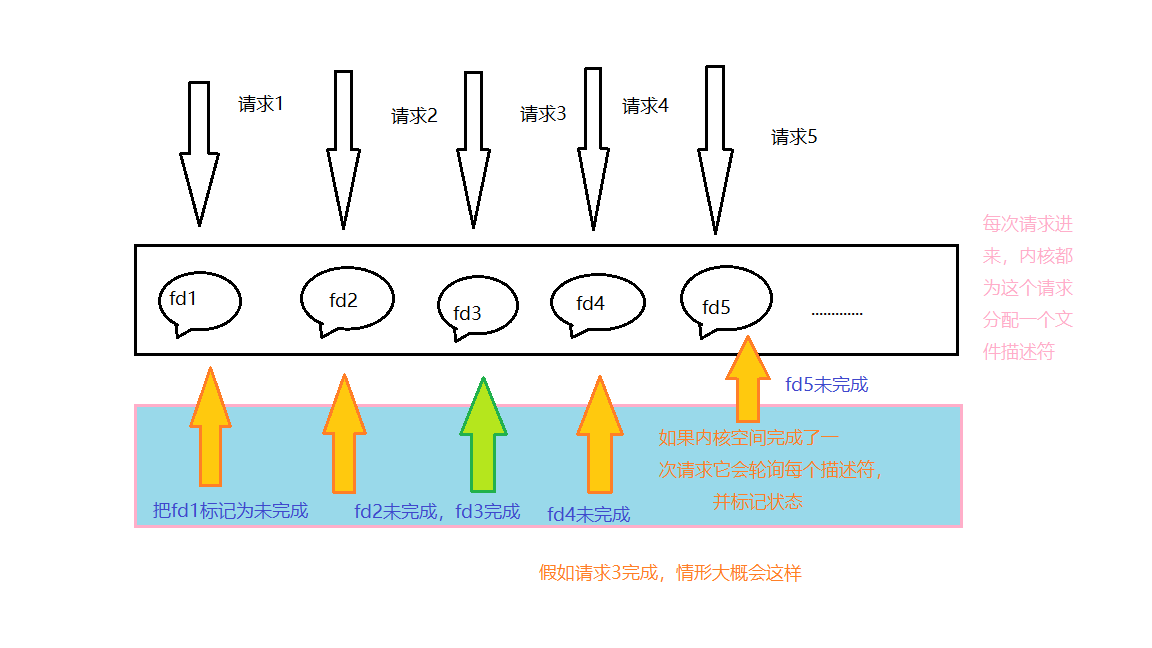
再回到问题本身,如果一个线程A服务多个请求如果出现阻塞的情形,再切换到别的线程B,就意味着A内的其他请求就无法执行,直到阻塞被释放,然而这样做并不合理,因为A内的其他请求可能不是I/O阻塞的,这就决定了,
不能切换线程,同时要在请求的上报机制上做出优化。请求一到达就通知内核空间处理的方式谓之同步,请求到达,达到一定数量时统一通知内核空间谓之异步
通知机制上,可以通知所有的文件描述符,无论完成未完成,也可以只通知完成的,可以通知一次,也可以通知多次;这种可以响应多个请求,又让请求知道自己的请求是否就绪的处理机制就谓之IO多路复用,或者
是I/O复用
在磁盘I/O上要使用AIO也就是异步I/O,不能因为I/O未完成而阻塞I/O;在某一时刻,如果某个请求尚未完成,那么该请求就处于等待状态。一旦请求完成,要重新建立这个请求的链接,并通知该请求结果就绪,
可以来取数据
网路上唤醒I/O------通过内核的I/O多路复用机制,如select模型;无论什么样的请求,反映在服务器主机上就是一堆套接字文件,一堆文件描述符,一旦就绪,该请求的文件描述符就会被激活;这就有了通知机制,例如:select