一、关于读取/写入kfk
https://www.cnblogs.com/importbigdata/p/10765558.html
1.kfkstreaming只能接kfk,而sparkstreaming比较通用
2.两种读取方法:1.director 效率高 2.receiver
3.写入方法:包装成可序列化类,再广播到每个Executors

二、消费kfk->sparkstreaming

(1)pom
<dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka_2.11</artifactId> <version>2.0.0</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.kafka/kafka-clients --> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>2.0.0</version> </dependency> <!-- spark --> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.11</artifactId> <version>2.3.4</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_2.11</artifactId> <version>2.3.4</version> </dependency> <dependency> <groupId>com.fasterxml.jackson.core</groupId> <artifactId>jackson-databind</artifactId> <version>2.6.6</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.spark/spark-streaming --> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming_2.11</artifactId> <version>2.3.4</version> </dependency> <!-- log4j 1.2.17 --> <dependency> <groupId>log4j</groupId> <artifactId>log4j</artifactId> <version>1.2.17</version> </dependency> <dependency><!-- Spark Streaming Kafka -->需要以spark版本为准,否则报错 <groupId>org.apache.spark</groupId> <artifactId>spark-streaming-kafka-0-10_2.11</artifactId> <version>2.3.4</version> </dependency>
(2)代码
importorg.apache.kafka.clients.consumer.ConsumerConfig import org.apache.kafka.common.serialization.StringDeserializer import org.apache.spark.streaming.{Seconds, StreamingContext} import org.apache.spark.{SparkConf, SparkContext} import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies} object MyDataHandler { def main(args: Array[String]): Unit = { //准备streamingcontext val conf=new SparkConf().setMaster("local[*]").setAppName("ttt").set("spark.serializer", "org.apache.spark.serializer.KryoSerializer") val sc=new SparkContext(conf) val ssc=new StreamingContext(sc,Seconds(5)) ssc.checkpoint("d:/cks") //准备读取kafka参数 val kafkaParams=Map( ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG->"192.168.56.111:9092", ConsumerConfig.GROUP_ID_CONFIG->"cm", ConsumerConfig.MAX_POLL_RECORDS_CONFIG->"1000", ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG->classOf[StringDeserializer], ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG->classOf[StringDeserializer], ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG->"true", ConsumerConfig.AUTO_OFFSET_RESET_CONFIG->"earliest" ) //读取kafka数据 // 分区策略:均匀分配分区 // consumer策略:kfk consumer读哪个topic,谁读 val ds=KafkaUtils.createDirectStream(ssc,LocationStrategies.PreferConsistent, ConsumerStrategies.Subscribe[String,String](Set("mmm"),kafkaParams)) // 输出方式1:print ds.print() // 输出每批数据的前10个 // 输出方式2:foreachRDD ds.foreachRDD(line =>{ line.foreachPartition(iteratorCR => { // Iterator iteratorCR.foreach(cr=>{ println(cr.value()) }) }) } ) ssc.start() ssc.awaitTermination() } }
(3)结果
每5秒print一次,每一个GroupId能消费出mmm的topic,from beginning
三、写入Kfk
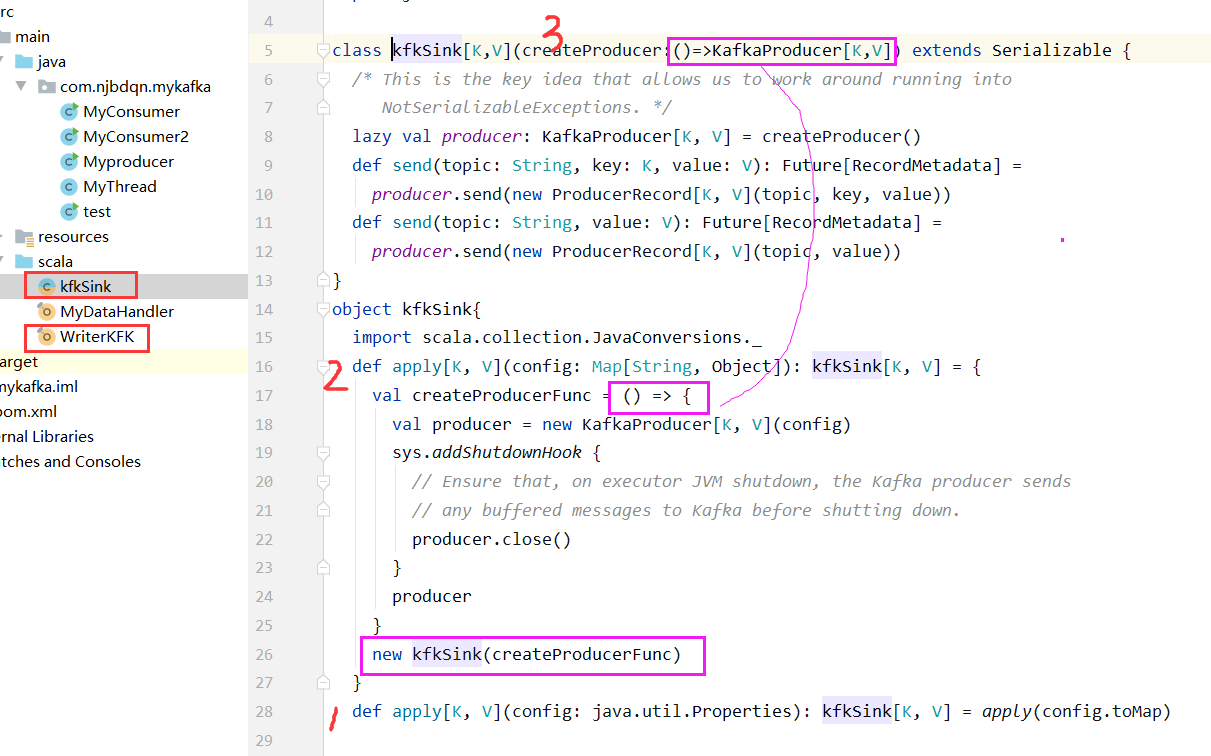

object WriterKFK { def main(args: Array[String]): Unit = { val conf = new SparkConf().setMaster("local[*]").setAppName("ttt") val sc = new SparkContext(conf) val prop = new Properties(); prop.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.56.111:9092") prop.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, classOf[StringSerializer].getName) prop.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, classOf[StringSerializer].getName) val kp = sc.broadcast(kfkSink[String, String](prop)) kp.value.send("mmm", "today is 15/12") } }
import org.apache.kafka.clients.producer.{ KafkaProducer, ProducerRecord, RecordMetadata } import java.util.concurrent.Future class kfkSink[K,V](createProducer:()=>KafkaProducer[K,V]) extends Serializable { /* This is the key idea that allows us to work around running into NotSerializableExceptions. */ lazy val producer: KafkaProducer[K, V] = createProducer() def send(topic: String, key: K, value: V): Future[RecordMetadata] = producer.send(new ProducerRecord[K, V](topic, key, value)) def send(topic: String, value: V): Future[RecordMetadata] = producer.send(new ProducerRecord[K, V](topic, value)) } object kfkSink{ import scala.collection.JavaConversions._ def apply[K, V](config: Map[String, Object]): kfkSink[K, V] = { val createProducerFunc = () => { val producer = new KafkaProducer[K, V](config) sys.addShutdownHook { // Ensure that, on executor JVM shutdown, the Kafka producer sends // any buffered messages to Kafka before shutting down. producer.close() } producer } new kfkSink(createProducerFunc) } def apply[K, V](config: java.util.Properties): kfkSink[K, V] = apply(config.toMap) }
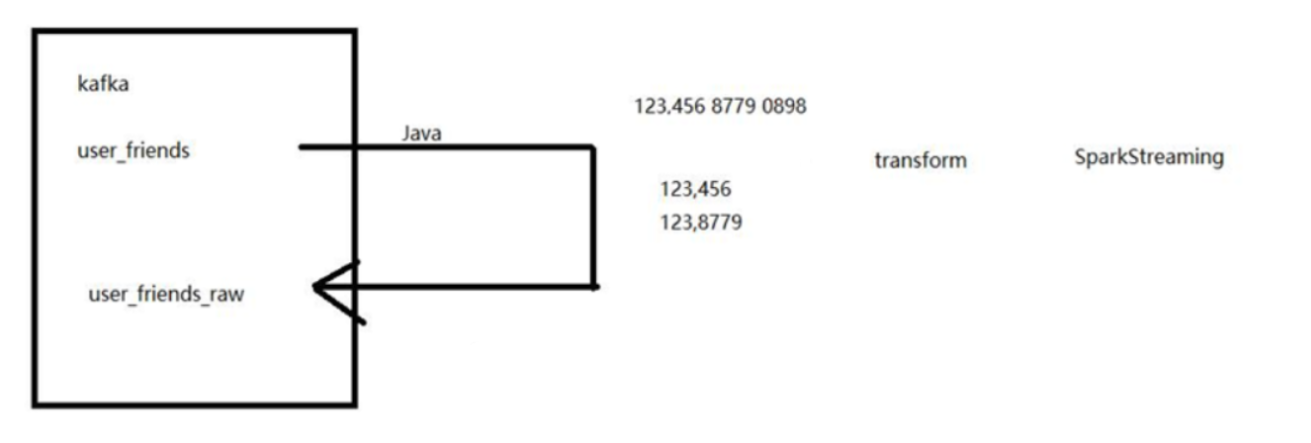
四、例1:把topic1:mmm数据读出,送到topic2:ddd2中
import java.util.Properties import org.apache.kafka.clients.consumer.ConsumerConfig import org.apache.kafka.clients.producer.ProducerConfig import org.apache.kafka.common.serialization.{StringDeserializer, StringSerializer} import org.apache.spark.streaming.{Seconds, StreamingContext} import org.apache.spark.{SparkConf, SparkContext} import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies} object MyDataHandler { def main(args: Array[String]): Unit = { //准备streamingcontext val conf=new SparkConf().setMaster("local[*]").setAppName("ttt").set("spark.serializer", "org.apache.spark.serializer.KryoSerializer") val sc=new SparkContext(conf) val ssc=new StreamingContext(sc,Seconds(5)) ssc.checkpoint("d:/cks") val prop = new Properties(); prop.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.56.111:9092") prop.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, classOf[StringSerializer].getName) prop.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, classOf[StringSerializer].getName) val kp = sc.broadcast(kfkSink[String, String](prop)) //准备读取kafka参数 val kafkaParams=Map( ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG->"192.168.56.111:9092", ConsumerConfig.GROUP_ID_CONFIG->"cm3", ConsumerConfig.MAX_POLL_RECORDS_CONFIG->"1000", ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG->classOf[StringDeserializer], ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG->classOf[StringDeserializer], ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG->"true", ConsumerConfig.AUTO_OFFSET_RESET_CONFIG->"earliest" ) //读取kafka数据 // 分区策略:均匀分配分区 // consumer策略:kfk consumer读哪个topic,谁读 val ds=KafkaUtils.createDirectStream(ssc,LocationStrategies.PreferConsistent, ConsumerStrategies.Subscribe[String,String](Set("mmm"),kafkaParams)) ds.foreachRDD(line =>{ line.foreachPartition(iteratorCR => { // Iterator iteratorCR.foreach(cr=>{ kp.value.send("ddd2", cr.value()) println("发送成功") }) }) } ) //ds.print() // 输出每批数据的前10个 ssc.start() ssc.awaitTermination() } }
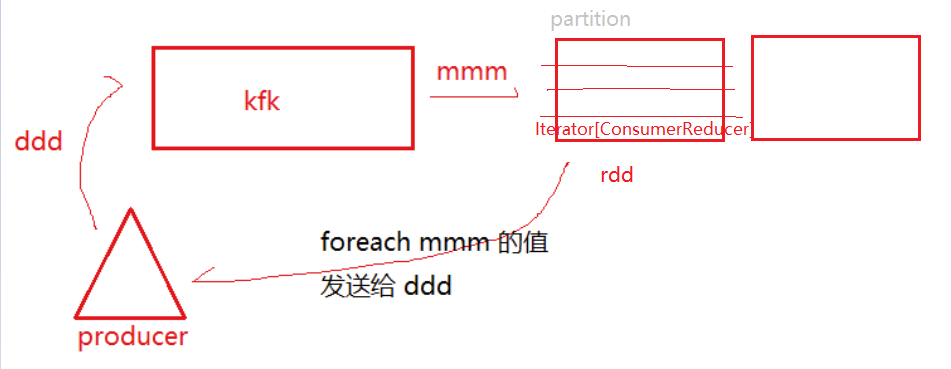
五、例2:使用kfk-sparkstreaming-kfk完成数据格式转换
方法1不推荐:只用foreachRDD无法去重(ds中没有foreach)
关键代码:
val ds=KafkaUtils.createDirectStream(ssc,LocationStrategies.PreferConsistent, ConsumerStrategies.Subscribe[String,String](Set("user_friends"),kafkaParams)) ds.foreachRDD(line =>{ line.foreachPartition(iteratorCR => { // Iterator iteratorCR.foreach(cr=>{ // ConsumerRecorder的value中:user,friends val datas = cr.value().split(",",-1) if(datas(1)!= ""){ val friends = datas(1).split(" ") friends.foreach(f=>{ kp.value.send("user_friends_2",datas(0)+","+f) }) } }) }) } )
方法2:先使用flatmap转换数据格式,可以完成去重等操作
为什么选择使用flatmap?每行xxx,xxx,xxxx转换成=> 每行的数组形式
再用foreachRDDZ逐条发送
user_friends
格式:user,friends
val ds=KafkaUtils.createDirectStream(ssc,LocationStrategies.PreferConsistent, ConsumerStrategies.Subscribe[String,String](Set("user_friends"),kafkaParams)) ds.flatMap(cr=>{ val user = cr.value().split(",",-1)(0) val friends= cr.value().split(",",-1)(1) friends.split(" ").map((user,_)).filter(_._2!="").distinct }) .foreachRDD(rdd=>{ rdd.foreach(x=>{ // 发的是string而不是元组 kp.value.send("user_friends_3",x._1+","+x._2) }) })
event_attendees
格式:event,yes,maybe,invited,no
-> (event,user,yes/no/invited/maybe)
val ds=KafkaUtils.createDirectStream(ssc,LocationStrategies.PreferConsistent, ConsumerStrategies.Subscribe[String,String](Set("event_attendees"),kafkaParams)) ds.flatMap(cr=>{ val rdd = cr.value().split(",",-1) val rdd1 = rdd(1).split(" ").filter(!_.trim.equals("")).map(y=>(rdd(0),y,"yes")) val rdd2 = rdd(2).split(" ").filter(!_.trim.equals("")).map(y=>(rdd(0),y,"maybe")) val rdd3 = rdd(3).split(" ").filter(!_.trim.equals("")).map(y=>(rdd(0),y,"invited")) val rdd4 = rdd(4).split(" ").filter(!_.trim.equals("")).map(y=>(rdd(0),y,"no")) rdd1.union(rdd2).union(rdd3).union(rdd4).distinct }) .foreachRDD(rdd=>{ rdd.foreach(x=>{ // 发的是string而不是元组 kp.value.send("event_attendees_actual",x._1+","+x._2+","+x._3) }) })
六、从kafka -> hbase
(1)导users
使用以前写的exam项目jar包(操作hbase工具包),结构见:https://www.cnblogs.com/sabertobih/p/14001250.html
项目位置:D:JAVA学习资料11.hbaseideaProjectshbase_operationexam
目录:
Users
public class Users { private String userId; private String locale; private String birthday; private String gender; private String joinedAt; private String location; private String timezone; public Users() { }
// 方便传 public Users(String datas){ String [] ds = datas.split(",",-1); // 注意-1 this.userId = ds[0]; this.locale = ds[1]; this.birthday = ds[2]; this.gender = ds[3]; this.joinedAt = ds[4]; this.location = ds[5]; this.timezone = ds[6]; }
AbstractHandler
/** * 适配类 */ public class AbstractHandler<T> implements IHBaseDataHandler<T> { @Override public Put insert(T t) { return null; } @Override public Get findById(Object o) { return null; } @Override public Scan findAll() { return null; } }
实现了 UsersHandler 类的insert方法
/** * 只使用insert方法 */ public class UsersHandler extends AbstractHandler<com.njbdqn.entity.Users> { @Override public Put insert(com.njbdqn.entity.Users users) { Put put = new Put(users.getUserId().getBytes()); put.addColumn("profile".getBytes(),"birthyear".getBytes(),users.getBirthday().getBytes()); put.addColumn("profile".getBytes(),"gender".getBytes(),users.getGender().getBytes()); put.addColumn("region".getBytes(),"locale".getBytes(),users.getLocale().getBytes()); put.addColumn("region".getBytes(),"location".getBytes(),users.getLocation().getBytes()); put.addColumn("region".getBytes(),"timezone".getBytes(),users.getTimezone().getBytes()); put.addColumn("registration".getBytes(),"joinedAt".getBytes(),users.getJoinedAt().getBytes()); return put; } }
MyRun
执行:
运行MyRun前
hbase shell list create_namespace 'event_db' create 'event_db:users','profile','region','registration'
运行后验证成功:分别统计hbase和kfk的记录数
hbase org.apache.hadoop.hbase.mapreduce.RowCounter 'event_db:users'
kafka-run-class.sh kafka.tools.GetOffsetShell --topic users--time -1 --broker-list 192.168.56.111:9092 --partitions 0
(2)导user_friends
发现数据太多,用原框架一条一条insert太慢,需要优化工具包 => batch insert
见 https://www.cnblogs.com/sabertobih/p/14001250.html 第三版本优化
UserFriends
public class UserFriends { private String userId; private String friendId; public UserFriends() { } public UserFriends(String ufs) { String[]datas=ufs.split(",",-1); this.userId=datas[0]; this.friendId=datas[1]; }
UserFriendsHandler
package com.njbdqn.services; import com.njbdqn.entity.UserFriends; import org.apache.hadoop.hbase.client.Put; import java.util.ArrayList; import java.util.List; public class UserFriendsHandler extends AbstractHandler<UserFriends> { @Override public Put insert(UserFriends userFriends) { Put put = new Put((userFriends.getUserId()+userFriends.getFriendId()).getBytes()); // 保证唯一ROWKEY put.addColumn("uf".getBytes(),"userid".getBytes(),userFriends.getUserId().getBytes()); put.addColumn("uf".getBytes(),"friendid".getBytes(),userFriends.getFriendId().getBytes()); return put; } @Override public List<Put> batchInsert(List<UserFriends> list) { List<Put> puts = new ArrayList<>(); for(UserFriends uf:list){ puts.add(insert(uf)); } return puts; } }
MyRun
package com.njbdqn.run; import com.njbdqn.entity.UserFriends; import com.njbdqn.entity.Users; import com.njbdqn.services.*; import org.apache.kafka.clients.consumer.ConsumerConfig; import org.apache.kafka.clients.consumer.ConsumerRecord; import org.apache.kafka.clients.consumer.ConsumerRecords; import org.apache.kafka.clients.consumer.KafkaConsumer; import java.time.Duration; import java.util.ArrayList; import java.util.Arrays; import java.util.List; import java.util.Properties; public class MyRun { public static void main(String[] args) throws Exception{ DatabaseHandler<UserFriends> handler = DatabaseUtils.getHandlerProxy(DatabaseType.HBASE, "event_db:user_friends", UserFriendsHandler.class); //Users user = new Users("1,cc,dd,ee,ff,dd,gg"); 用来测试是否能用工具导入hbase成功 // handler.add(user); Properties prop = new Properties(); prop.put("bootstrap.servers","192.168.56.111:9092"); prop.put("group.id","cm8"); prop.put("enable.auto.commit",false); prop.put("key.deserializer","org.apache.kafka.common.serialization.StringDeserializer"); prop.put("value.deserializer","org.apache.kafka.common.serialization.StringDeserializer"); prop.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"earliest");//从头开始 KafkaConsumer<String,String> consumer = new KafkaConsumer<>(prop); consumer.subscribe(Arrays.asList("user_friend_actual")); // 为user_friend转换后的表,(user,friend)唯一 //consumer.assgin(""); # 消费分区为x while(true){ ConsumerRecords<String,String> records = consumer.poll(Duration.ofSeconds(1)); // 每秒消费一批 if(!records.isEmpty()){ List<UserFriends> ufs = new ArrayList<>();
// 一批records -> ufs for(ConsumerRecord<String, String> rec : records){ UserFriends uf = new UserFriends(rec.value()); ufs.add(uf); }
// 把每秒一批的records一次塞进hbase handler.batchAdd(ufs); } consumer.commitSync(); } } }
(3)jar包形式,可以用脚本定时运行
1)在原来依赖的操作hbase的jar包中修改读取配置(改成这样只能用于java -jar执行了,本地执行这种路径就错了)

2)入口MIAN函数中添加args[0]
DatabaseHandler<Test> handler = DatabaseUtils.getHandlerProxy(DatabaseType.HBASE, "event_db:test", TestHandler.class,args[0]);
3)linux端
java -jar kfkToHbase_2-jar-with-dependencies.jar /root/driver.properties
验证成功: hbase org.apache.hadoop.hbase.mapreduce.RowCounter 'event_db:test'