借助hbase的读写思路做数仓
hbase读写速度快(与HDFS对比)是基于两方面:
1)用户写(入cache)和(cache)写入硬盘是异步的
2)有-root-和-meta-表,能够快速定位表的位置 => 成为物理化的标准索引
详见:https://www.cnblogs.com/sabertobih/p/14001268.html
设计案例
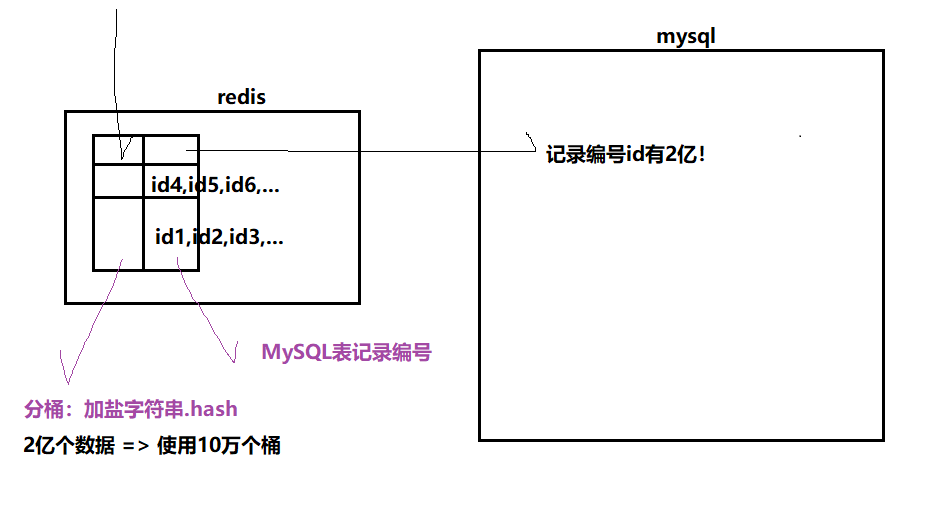
需求描述:在mysql中存在2亿数据,全是真药。药品id如果在库中不存在,则为假药。
要求给一个药品id,能立刻判断出是真药假药?
设计思路:
1)给mysql的id建立索引 => 会快一些,但仅仅是一些
2)在高速缓存中建立索引表,所有id插入key:value(set集合)时用加盐哈希分桶,存储set集合(防止mysql中真要id有重复)
=> 这样我给一个id=12345,根据索引定位进某个桶,遍历1000size的数据
=> 没找到即为真药 => 添加进mysql+redis
找到即为假药
优点:原本遍历mysql2亿数据量,现在只需要遍历1000数据量
插入索引表
public static String tucketNo(int i){ // 此方法如果String值特别大会出现负数 // hadoop默认的hashpartitioner中为了解决这个问题,使用与运算:(key.hashCode() & Integer.MAX_VALUE) % numReduceTasks; return (i+"").hashCode()%100000+""; // 这里可以用abs取绝对值,否则生成200000个桶 } Jedis jedis = new Jedis("192.168.56.111",6379); Pipline pip = jedis.pipelined(); // 开启Jedis的多线程操作 for (int i = 0; i <200000000 ; i++) { pip.sadd(tucketNo(i),i+""); // 看进度条的 if(i%100000==0){ Thread.sleep(50); System.out.println(i); } } pip.syns(); jedis.close();
性能测试
Jedis jedis = new Jedis("192.168.56.111",6379); int no = 123344; long time = System.currentTimeMillis(); // 这个桶(value是set的key)是不是存在no这个数? System.out.println(jedis.sismember(tucketNo(no),no+"")); // 判断是否redis某个桶中存在某个数只花费了___milliseconds System.out.println(System.currentTimeMillis()-time);
实现药品需求伪代码:找不到id则另开线程,异步写入缓存+mysql
if 找不到这个id => new Thread(new Runnable(){ @overrideid public void run(){ sout("id插入数据库mysql") jedis.sadd(tucketNo(no),no+""); // id插入索引 sout() } }).start()